日記 9750
adw という名前でやらせていただいております
趣味
- AtCoder
ちょっとコーディングにハマった - 乗り鉄
乗り鉄ですがなにか
好きな言語
- rust
最近は rust 一筋でやらせていただいております
いつも使ってるリポジトリ
https://mirror.hashy0917.net/
※自動変更スクリプトも書いてます。 よければ使ってください。 → change0917
リンクとか
RT 専門です。 垢わけようか、迷ってます
ボイスロイド劇場が好きです。 一人称劇場大好き。
ASMR 毎日お世話になってたら耳ガアアになったので、ほどほどに癒されてます。
github アカウントです。
qiita でも書いてます。- BlueSky
bluesky 登録できた(今更)


notepad.md について
- url: https://adw39.org
- repo: tam1192/tam1192
mdbookを使用した暫定ブログです。 今後機能つけて正式ブログにするか、wordpress 鯖立てるかは迷ってます。
github pages を使ってるので、そんなに落ちないと思います。 自宅鯖に移行した暁には落とさないようベストを尽くします。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
ブックマーク
このページでは、日記さんが参考にしたサイトをリンク集として公開しております。
git 関連
rebase 関連
- How do I git rebase the first commit?
この記事では、最初のコミットを empty(空)にする方法が載っています。 最初のコミットを編集する必要がある場合もこの記事が参考になります。 - リポジトリを作り直した件
この記事では行えませんでしたが、実際は 1 の方法で解決できます
qiita でアップしました!
日記さんが qiita でアップした記事の紹介です。 qiita のマイページ
投稿方針について
qiita アップロードする情報は、こちらより真面目かつ正確な情報を伝えようと努力したものです。(実際はそうじゃないかも) また、qiita 記事のコメントはぜひ qiita のコメント欄にてお願いします!!
ここでは何書くの?
記事の紹介と、書いてて思ったことを書きます。
notepad.md お馴染み、主観マシマシです!
今更 type-c デビューしてみた
lightning 使ってるとどうしても type-c への対応が遅れるからね。仕方ないね。 (デビュー日: 2024 年中旬)
本日のひとこと
いつも聞いてるけど本当に明るい気分になれる!! って曲です。好き。 ミク愛してる。
書いた感想とか
久々に qiita に書きました。 結構 wikipedia 先生参考にした記事です。
ノートについて
notepad.md でも note 機能をつけて使ってます
note
これのことです!
ここには主に主観、感想とかを入れるようにしてます。 notepad.md でも感想などは Note にしてますが、qiita 記事ではさらに Note にしてます。 少しでも正確性を増しながら、自分ふうな記事を書けるようにしてるのです。
ところで type-c ハブ買った
type-c になってから 9in1 ハブなどを使うようになりました。 これかった、ugreen さんのは信用できるから
やっぱ便利ですね。hdmi も rj45 も使えるようになるし、カメラ関係で sd カードつかえるし、
何よりたくさんのポートついてると嬉しいよね!(その考えがそもそも古いという...)
pd 対応が良い
pd 対応の物だと、充電器からハブに、ハブから pc、もしくはスマホとスムーズに繋げられます。 これまた便利
ところで type-c 電力メーター買った
pd については書く気なかったのですが、電力メーター買っちゃったので無理やり書きました。 pd はだいぶ前から恩恵受けてました。(lightning 使えたので)
まとめ
記事にも書いてある通り、真面目に詳しくないことを無理やり書きましたので、
コメントお待ちしております。
以上、少しでも自分の認識を正しくしたいマン 日記さんでお送りしました。
ライフタイムを意識してコードを書く.rs
過去にひとくちメモとして載せていた記事を修正、qiitaに移したものです。
本日のひとこと
ちねつき。
そもそもひとことメモじゃなかっただろ!
そういうボリュームの記事ですが、後から見直すと内容が多い割に割と整理された記事と感じたので、qiitaに載せる記事にしました。
移行時に思ったところ
このサイトはmdbookで作られており、mdbookはrustコミュニティーによってrustで作られてます。
rustのドキュメントを書くのには相性がよく、rustのコードブロックはPlaygroundを通じてその場で実行できるほどです。
もちろん、 mdbook専用のものなので、 qiitaに移す際はコードが実行できないことを念頭におく必要があります。
そのため、実行してもらえる前提のコード・記事から、実行されない前提のコードに変更しました。 といってもそこまで変えてません。 そもそもコードは私にしては割と丁寧に作られてたので...
1時間かけずに移行できた
移行に1時間かけませんでした。 割と手早くできました。
以上
移行した時の裏話でした。
記事はこちら 記事へのコメントお待ちしております!!!
コーディング日記
github であげたコードに対する備忘録を載せております。
My Parser Project
CommandAPIを用いて生成したプロセスの標準入出力を管理するプログラムを書いていて、 その実験用に登場した「DesperatelyRustyToolBox」が 独自のコマンドラインを持つプログラムであった。
このプログラムをもっと拡張できるよう、高度な構文解析が必要と考えて登場したのがこのプロジェクト。
他にも登場経緯はあるが割愛。
自分用標準構成
自分用とあるが、実際rustで開発するにあたって必要であるカスタム型、便利ツール、開発方法、モデルを定義したもの。
要素は以下の通り
- CI/CDを実現するためにGithubActionsを積極採用
cargo buildとcargo testを自動化。さらに、cargo docも自動化。
mainにマージされた時はクリーンなコードを保てる。 - テスト駆動開発で開発を行う
せっかくCI/CDでテストの自動化を行ったんだから、書かないわけにはいかない。
公式にもある通り、テスト駆動開発で目標の見える化を実現。 - エラートレイトを実装したオリジナルのカスタムエラー型を用意
ちゃんとsourceまであるならsourceまで実現。
エラー発生箇所の特定を容易にするだけでなく、
Fromの実装で?シュガーシンタックスに対応、コードがより見やすく。 - 一般的なブランチモデルを採用
いわゆる
git flowに基づいたブランチモデルを採用する。
また、名前規則やコメント規則等々も今後まとめていきたい。
最終目標
このプロジェクトを使い回していけるように頑張りたい。
参考とか
- Rust でパーサコンビネータを作ってみる/nojima様
パーサーコンビネータの基本のきがここに載ってます。とても参考になります。
当プロジェクトでは部分的に実装を変えたりしてるが、ほとんど参考にして作ってます。 - BNFや構文解析についてのメモ
四則演算パーサー実装時に参考にしました。
commit: first_commit
この記事はgitを用いながらrustでプログラムを書いてみよう っていう記事です。
warning
この記事は途中までです。
使ってる環境
- macOS Sequoia
- vscode
- git 2.39.5 (Apple Git-154)
- rustc 1.83.0 (90b35a623 2024-11-26)
- cargo 1.83.0 (5ffbef321 2024-10-29)
- github
詳しく説明しないこと
- unixのコマンド(もしくはpwsh,cmdのコマンド)
無駄に詳しく説明すること
- rustの知識(ある意味rust布教記事でもある)
commit: cargo initを実行
開発環境をセットアップして、最初のコミットをしよう。
localリポジトリをセットアップ
rustのプロジェクトを作ります。 とりあえずディレクトリを作成してそこに移動
cargo init .
を実行すると、いい感じにセットアップしてくれます。
.
├── Cargo.toml
└── src
└── main.rs
この時点ですでに、gitのローカルリポジトリがセットアップされています。
補足
cargoというのは、rust開発者を支援するツールです。 rust以外だと、cmake(c言語)、gradle(Java,Kotlin)、npm(nodejs)などがあります。
これらのツールは基本的に、外部ライブラリの整理(インストール)、ビルド支援(プログラム間の連携)をしてくれるわけです。
githubにアクセスできるようにする
github上にリポジトリを作りましょう。
git remote add
する方法もあり、学びとしてはそっちの方が深いのですが、
正直こっちの方が楽
https://cli.github.com
一度githubのアカウントを作成しておけば、CLI上でログインするだけでgithubの機能をコマンド上からアクセス可能です。
sshの鍵登録も不要!
インストール後、
gh auth login --web
コマンドでgithubにログインします。
githubにリポジトリを登録
一度ghコマンドを使えるようにすると、以降次の手順でgithubにリポジトリを作成可能です。
gh repo create
対話式で様々な質問が出てきます。
What would you like to do?
一番最初の質問で三択出てきますが
Push an existing local repository to GitHub
(存在しているローカルリポジトリを、githubにpushする) を選択します。
その後はenter連打でいけます。
注意
Visibility をprivateにすると、非公開になります。 公開するのが怖い場合は注意してください。
コミットする
ここまできたらコミットします。
コミットって何?
例えば、blenderでサイコロを作るとき...
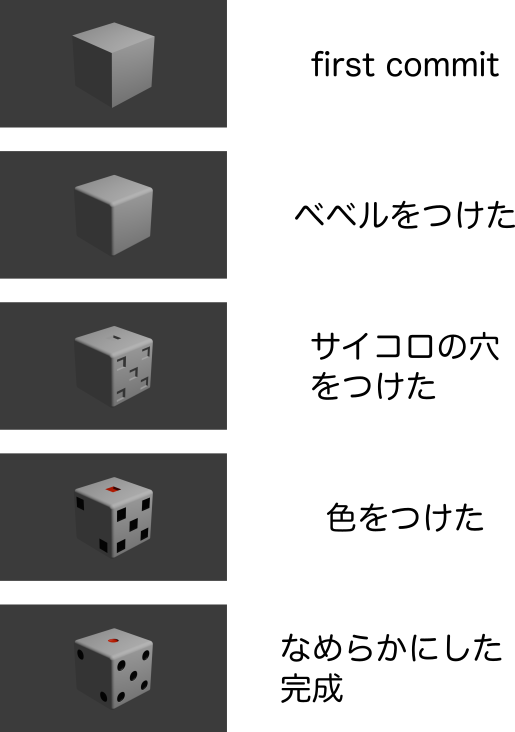
上からステップごとに分かれていて、作業ステップが変わる度に
git commmit -m <ここにコミットメッセージ>
というコマンドを入力します。
こうすることで、ファイルをいじった時、ファイルの変更にメッセージをつけて記録しておくことができます。
コミット頻度はどうしよう
例えば、サイコロの形に変更が入った時...
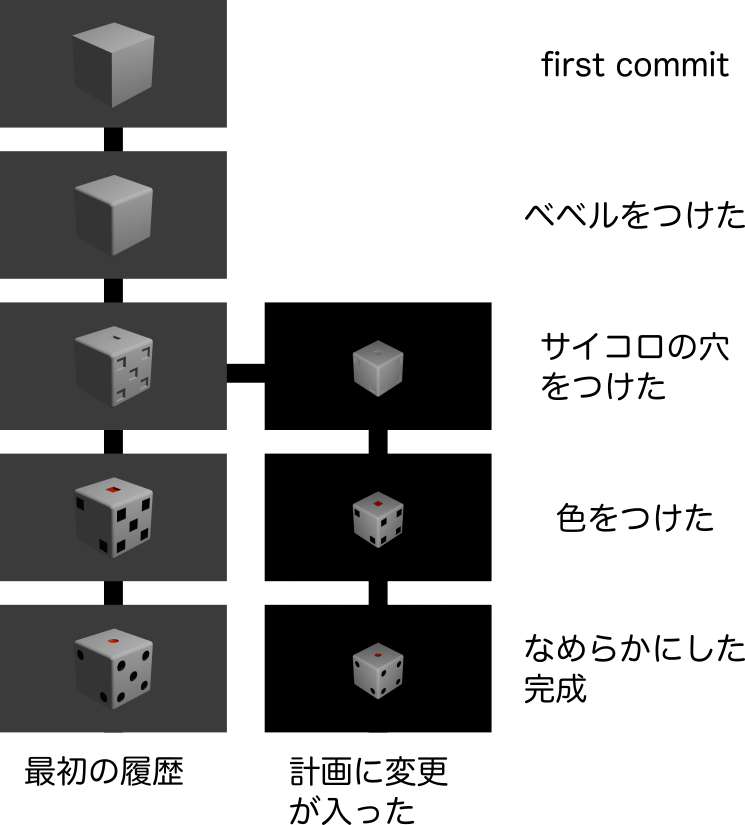
git logをたとって、あるコミットから分岐させることが可能になります。
(分岐の方法については後で記載します)
そう考えると、次の考え方ができます。
- コミット間に加えた変化が多いほど、戻しづらくなる
- しかし、コミットが多いほど、今度はログが見辛くなる
(例えば、サイコロの穴を開ける時、穴一つ一つ毎にコミットすれば、20コミット増えます)
しかも、git logした時、得られる情報はメッセージのみです。

そう考えると、
- コミットメッセージは丁寧にした方が良い
となるわけです。
コミットの頻度についてはこれらの記事が参考になると思います。
...参考にしてるのかよく分からないですが、 今回は 「変更が一行で説明できる範囲内で1コミット」 を目標に 頑張ります。
ところで
もちろんblenderでもgitは使えます。(blenderにターミナルついてないから相性は良くないかもだけど) 何なら、パワポ、ワード、エクセルといった3種の仁義、 その他etc...
gitのメリットの一つ バイナリファイルが扱える です。
(この記事も下敷きはgit使ってます)
実際に行ってみる
実際にコミットします。
まずはプロジェクトの一番浅いところで次のコマンドを実行
git add .
意味は次の章で説明
git commit -m "cargo initを実行"
これでコミットができます。
first commit? 邪道です、ちゃんとやったことを書く
(こだわり強く生きる)
リモートにあげる
コミットしただけではリモート(github)に適用されません。
次のコマンドでリモートにアップロードできます。
まず、git branchを実行。
このコマンドで表示された文字列がmasterなら
git push --set-upstream origin master
このコマンドで表示された文字列がmainなら
git push --set-upstream origin main
意味は後述
二回目以降はこちら 、理由は後述
git push
logを確認
> git log
commit 6c57a4c498b7a817265563bb8e1c8b31ee1a3a7d (HEAD -> master, origin/master)
Author: nikki9750 <76221172+tam1192@users.noreply.github.com>
Date: Sat Jan 11 17:42:06 2025 +0900
cargo init を実行
commitの後ろに書いてあるハッシュみたいな文字列はコミットハッシュです。 識別子。 さっきみたいにコミット戻す時に使います。
HEADは頭。 今触っているところ。master(main)はブランチと言います。originはリモートの名前です。Authorコミットした人Dateコミットした日付
これで最初の作業は終了です。
ブランチ
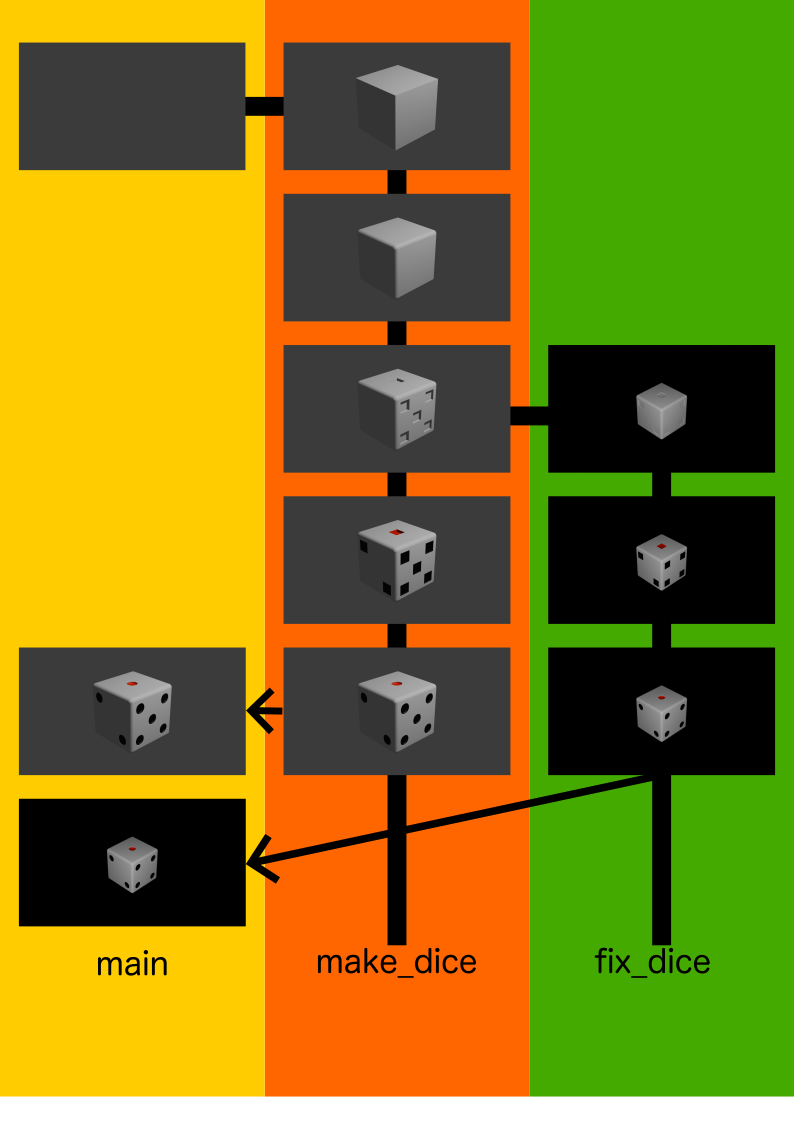 図のように、ログを切り分けることができます。
左から右に、ブランチを作成しています。(ブランチを切るという)
右から左の矢印は、切ったブランチから変更を適用しています。
図のように、ログを切り分けることができます。
左から右に、ブランチを作成しています。(ブランチを切るという)
右から左の矢印は、切ったブランチから変更を適用しています。
一度作成したブランチは消すまで存在し続けます。 別のブランチで加えた変更は、様々な方法で別のブランチで適用ができます。
ブランチのメリットは、触りながら理解できればいいかなと思います。
mainとmaster(変更は任意)
masterが差別用語に該当するとかで、mainという言い方に切り替わっています。(参考)
masterブランチは、これ以降mainに統一して説明します。
私の環境では、cargoが生成するgitリポジトリのデフォルトブランチが"master"なので、gitに触れるついでに変更しておきます。
今いるブランチをmasterにして、
git branch -m main
で変更。
-mはブランチ名の変更を意味するそう。
そのままpushしようとすると
fatal: The upstream branch of your current branch does not match
the name of your current branch. To push to the upstream branch
on the remote, use
git push origin HEAD:master
To push to the branch of the same name on the remote, use
git push origin HEAD
To choose either option permanently, see push.default in 'git help config'.
To avoid automatically configuring an upstream branch when its name
won't match the local branch, see option 'simple' of branch.autoSetupMerge
in 'git help config'.
と出るので、その通りに
git push origin HEAD
しかし、リモート側に新規作成されるだけで、変更にはならないので...
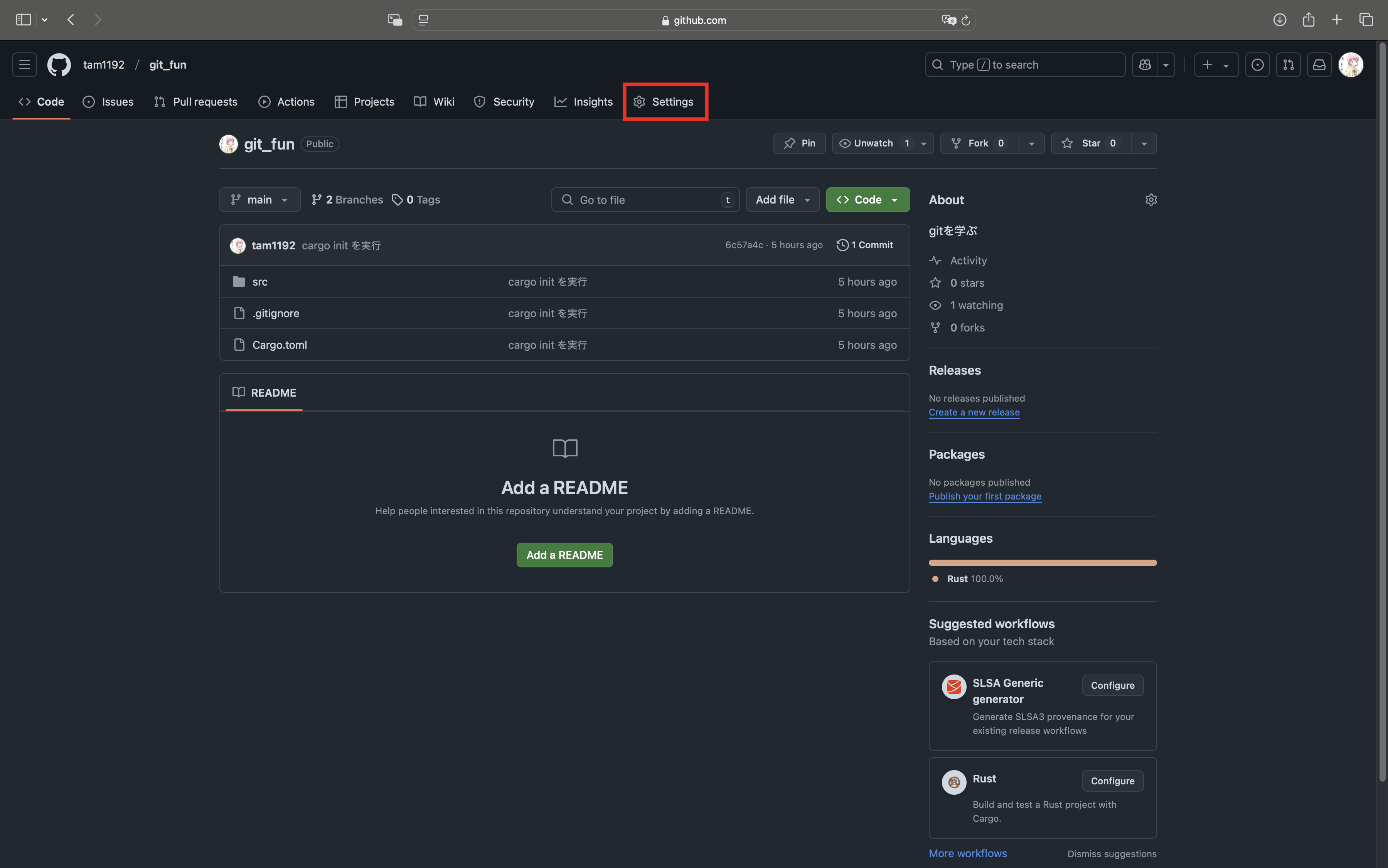 githubのSettingsにアクセスし
githubのSettingsにアクセスし
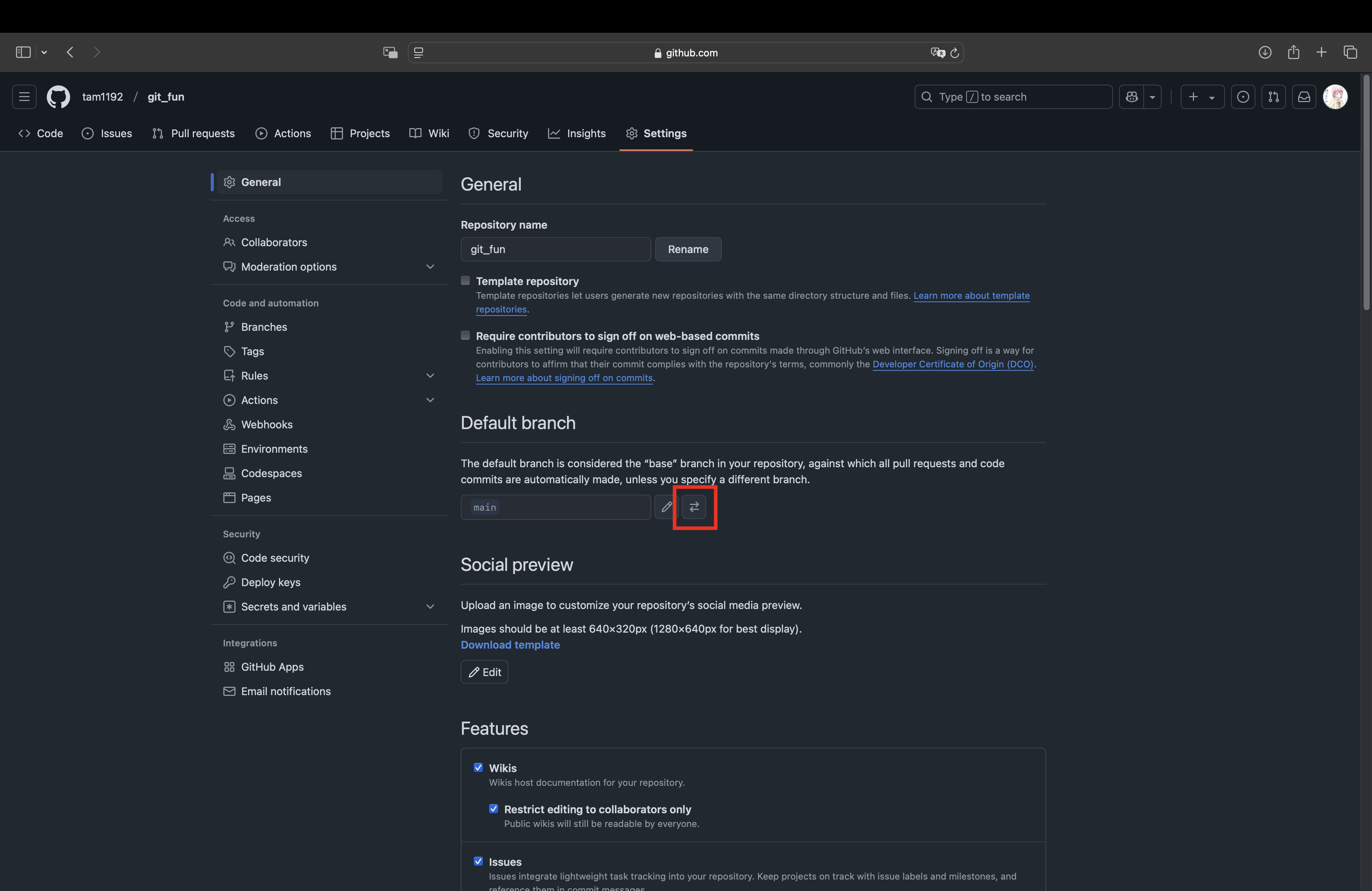
 Default branchを変更
Default branchを変更
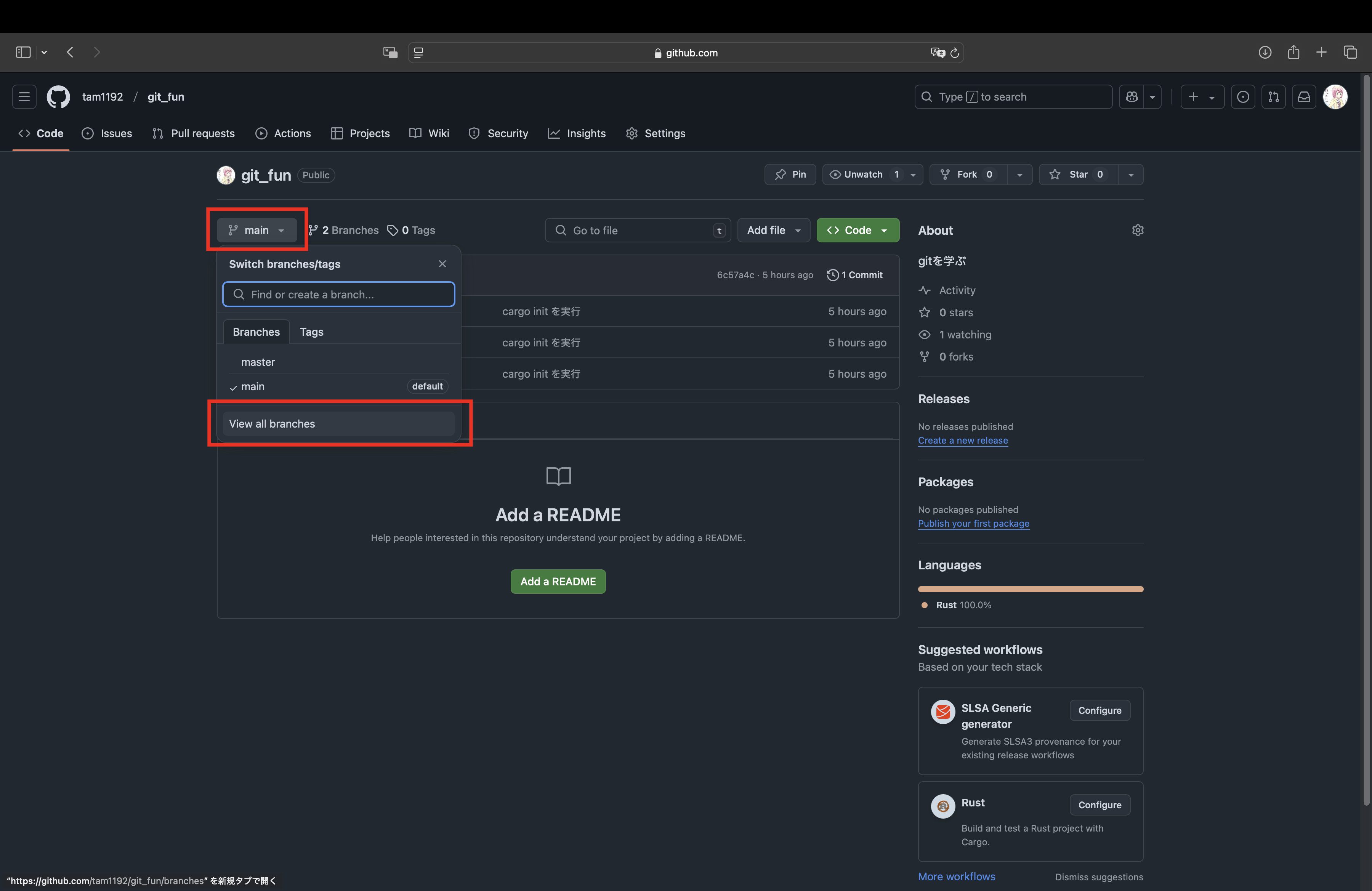
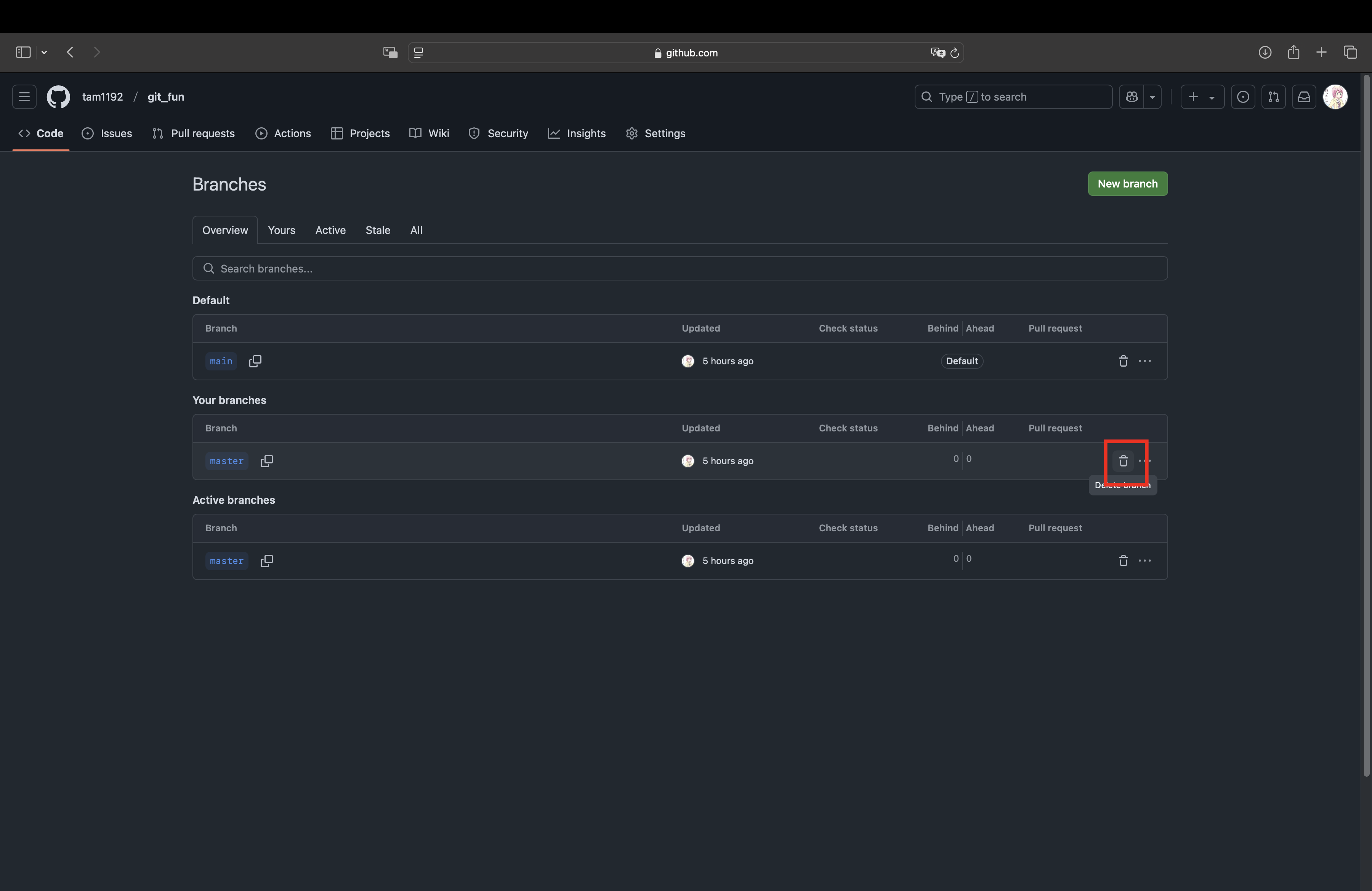 その後、masterブランチを削除する
その後、masterブランチを削除する
これで解決...しない ローカルの方でも変更が必要。
> git branch -a
* main
remotes/origin/main
remotes/origin/master
-aオプションは、隠しブランチ的な存在を表示してくれる。
remoteというのはその名通りリモートのこと。
リモートとローカルは、その性質上ズレが生じる。それをうまいこと解決してくれるブランチなのだが、masterが居残る。
git fetch --prune
を実行すると、masterが消えてくれる
> git branch -a
* main
remotes/origin/main
remotes/origin/master
試してないから知らんが、git branch -d /remotes/origin/masterよりは安全と見た。
branch: ライブラリを試験
日記さんはコマンドラインプログラムを書くことに決めました。
計画を練ろう
計画的に開発する方が、幸せになります。 (ちなみにこの記事は無計画です。)
コマンド名はnanodesuにします。
nanodesuは、nanoコマンドをめっちゃシンプルにしたテキストエディターです。
大まかな計画はこんな感じ
- 引数処理: 引数の処理をします
- ファイル入出力処理: ファイル読み込みの処理をします
- キー処理: コマンド実行中に受けた入力に応答します
- 画面処理: 入力に対応して画面が動くようになります
- デプロイ: 公開します。
- ドキュメント作成: 説明書を作ります。
使うライブラリを検討
一から書くと時間がかかります。 有志が作ってくれた優秀なライブラリをフル活用しましょう。
- clap: 引数の処理をしてくれます
- ratatui: 画面の処理とキー処理を担当してくれます
- fs: ファイルの処理をしてくれます
この先の計画を練る前に
ライブラリを使う場合、まずは触れてみたくなります。 触れるために新しいプロジェクトを作っても良いのですが、 せっかくgitを使ってるので 、gitで管理しようではありませんか。
ブランチを作る
この図のように、コミットログを切り替えることができます。
左から右に、ブランチを作成しています。(ブランチを切るという)
git checkout -b <ブランチ名>
でブランチを切ることができます。 ここで加えた変更は、mainには適用されません。
Readmeファイルを追加しよう
Githubでは、Readme.mdというマークダウンファイルがある場合
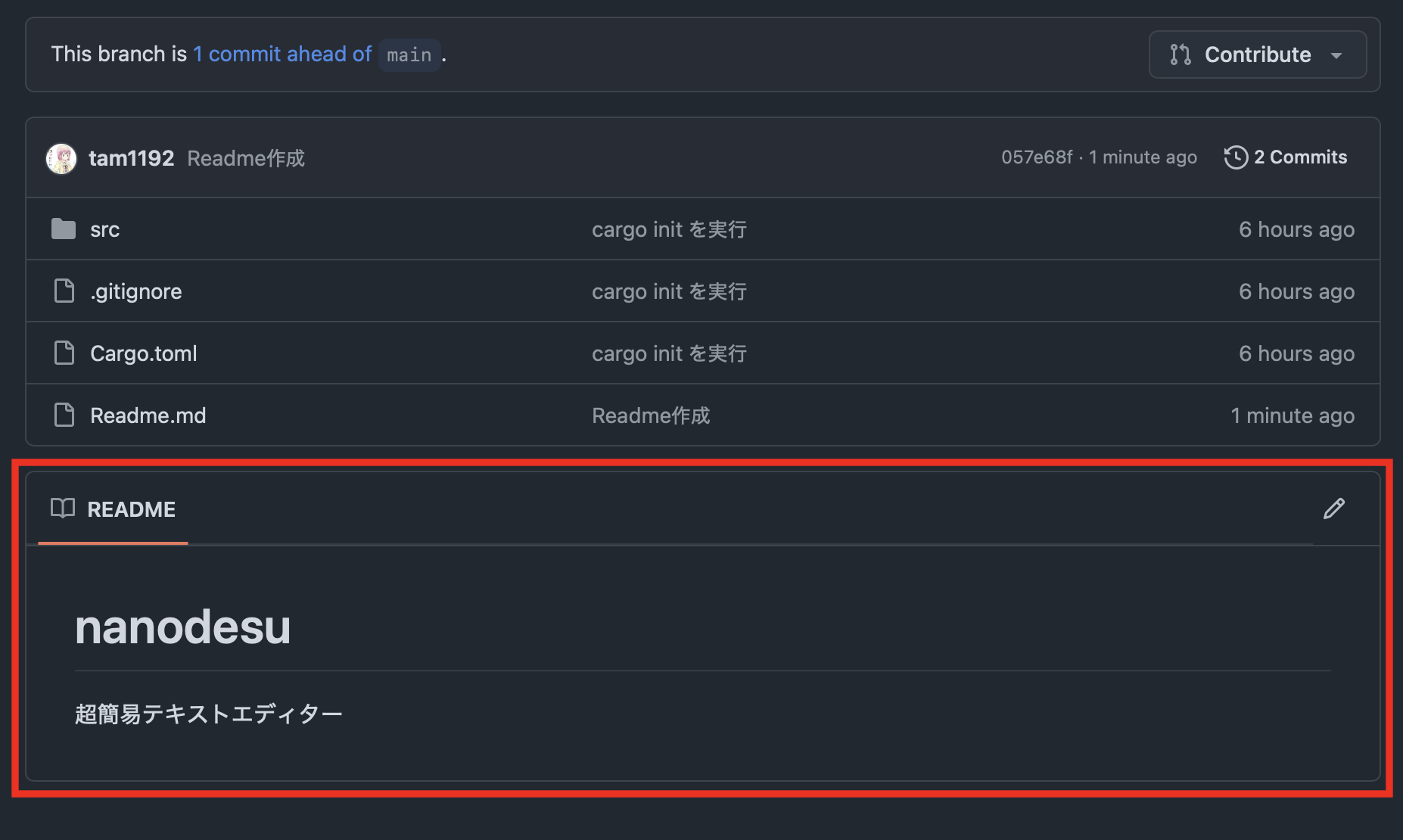 この部分に、その内容が表示されます。
この部分に、その内容が表示されます。
このファイルをブランチを使って追加してみましょう。
git checkout -b Readme追加
ブランチが作成されると
git branch
を実行した時に
> git branch
* Readme追加
main
となるはずです。 *が今作業しているブランチ。
内容は適当でいいので、Readme.mdを作成して保存。 コミットはまだしないでください。
ブランチを切り替える
git checkout main
で一度mainに戻ります。
lsコマンドで中身を除くとこうなるはずです。
> ls
Cargo.toml Readme.md src
ブランチをせっかく分けたのに、変更がmainにも同時に適用されているように見えます。
この時点で、Readme.mdがまだgitの管理下にない状態であることを理解する必要があります。 コミットもしてないから当然っちゃ当然?
ステージング
git checkout Readme追加
で先ほどのブランチの戻ります。
git addは、コミットするファイルをステージングするためのコマンドです。
git addは、前回のコミットから変更が加えられたファイルのみをステージングします。
git add .で、カレントディレクトリーより深く変更が加えられたファイル全てをステージングに追加します。
git addの恩恵はこの先で知ることができるはずです。
git add .
もしくは
git add Readme.md
でステージングします。
git checkout main
でもう一度mainに戻ります。
lsコマンドで中身を除くとこうなるはずです。
> ls
Cargo.toml Readme.md src
ステージングした時点ではまだコミットされていません
コミットするブランチを決める
この状態でgit commitをすると、mainブランチでコミットされます。
それだと困るので、
git checkout Readme追加
で先ほどのブランチの戻ります。
git commit -m Readme追加
ついでにremoteにあげましょう。
remoteとorigin
git remote -v
を実行すると
> git remote -v
origin https://github.com/tam1192/git_fun.git (fetch)
origin https://github.com/tam1192/git_fun.git (push)
となるはずです。 -vは`verboseの略で、冗長とかいう意味があります。
originとなってますが、名前を変更できます。
git remote rename origin github
もう一度実行すると
git remote -v
github https://github.com/tam1192/git_fun.git (fetch)
github https://github.com/tam1192/git_fun.git (push)
名前が変わっています。 gitは複数のリモートリポジトリを同時に管理可能なため、remoteを自由に追加できます。 originとは初期設定でつくremoteサーバーの識別名です。
複数のremoteを使えるのは、gitが分散型だからとも言えるのではないでしょうか。 しらんけど
だけど、基本一つのremoteしか使いたくない(複雑になるから)
リモートにブランチを作る
gitの分散というのは何も、複数のリモートを使えるということだけではありません。 リモートリポジトリの内容がローカルリポジトリに丸まるクローンされているというのも大きいです。
だからこそ、今作ったブランチがリモートに存在するとは限らないのです。
git pushとは何者か
git pushを実行すると、ブランチごとにあらかじめ設定しておいたリモートのブランチに、変更を送信します
set-upstreamでリモート
実際にリモートにブランチを作るにはこう設定します
git push --set-upstream <リモートの識別名> <リモートでのブランチ名>
なお、基本的にローカルとリモートのブランチ名は同一です。
git push --set-upstream origin Readme追加
※originをgithubに変えた場合は変更してください。
これで、リモートに変更が加えられます。
一度設定したら再び同じことをする必要はありません。
git pushだけで送信されます。
mainに変更を適用する
コミットが成功するとmainブランチで
> ls
Cargo.toml src
という結果が得られるはずです。
Readme.mdはReadme追加ブランチで変更を保存されたため、mainには存在しない扱いに切り替わったのです。
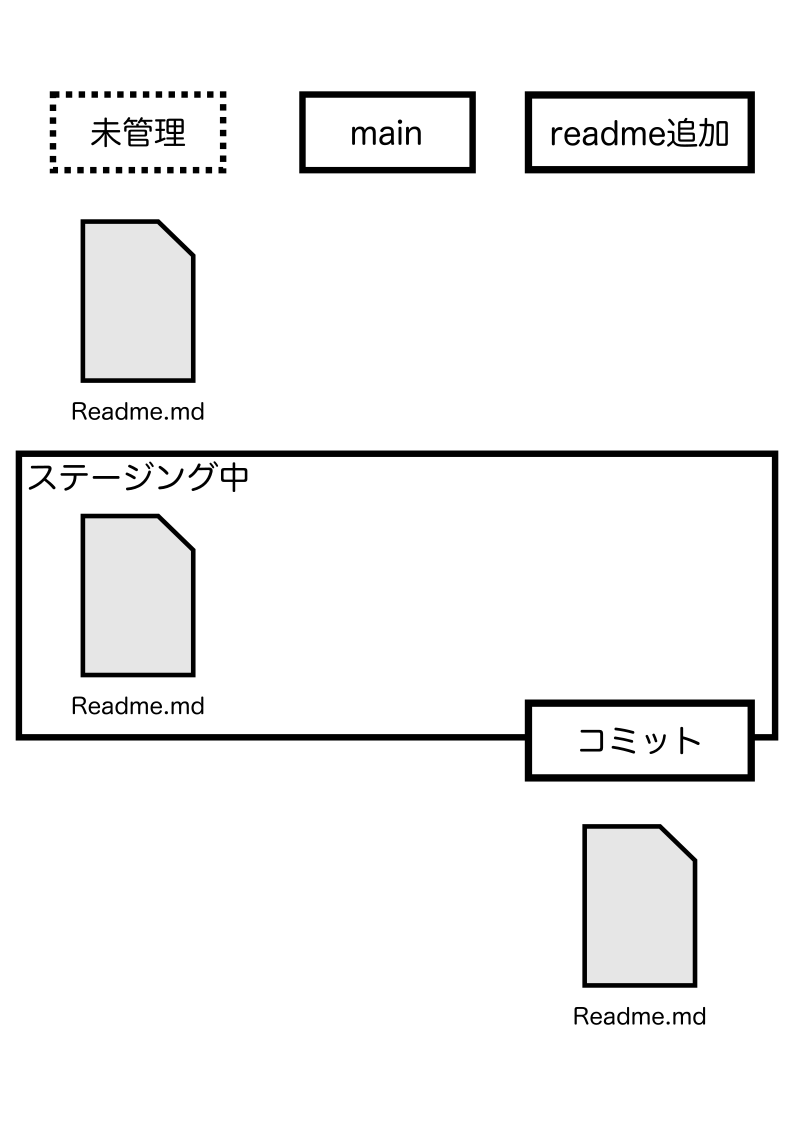 gitがまだ一度もコミットしたことがない、未管理のファイルはコミットするまで全てのブランチで表示されます。
gitがまだ一度もコミットしたことがない、未管理のファイルはコミットするまで全てのブランチで表示されます。
gitがファイルを操作していないからです。
一方で、コミットすると、コミット履歴が残っているブランチにのみファイルが存在するようになります。
gitがファイルを操作するようになるからです。
現時点でmainブランチにReadme.mdが作成された履歴がないから、表示されないわけです。
参考URLとか
感想もうっすら書いてます。割と適当なので注意されたし
作図・図とか
この際だからblender触ってみたかった。 最新版でもイケる
git
コミット頻度関係
頻繁にコミットするのが大切らしい
適度なコミットがよいらしい
便利だなぁ。是非ともブックマークしたい記事
ブランチ
-nではなく-mなのか。 変更することないから知らんかった。
追跡ブランチってちょっと複雑だから使わないように気をつけて書いてた。
rust関係
Crate
Vue × WASM × Rust—試行錯誤とこれからの展望
初版投稿日: 2025/06/10 (コミット履歴より) 更新日: 2025/09/05
元々 AI 一緒に書いた記事ですが、少し改めます。
本日のふたこと
(2025/09/05 のひとことになります)
すでに別記事をあげてるので二言目になります。
最近ずっと聴いてる
とりあえず
このサイトは、rust(nom)で書かれた四則演算パーサーを wasm で載せ、それを実際に動かしているものです。 nom などについては当サイトのパーサー記事が参考になるかと。
wasm の注目度
私が思っていたより、wasm はすごいものでした。 Linux コンテナの「次」としての WebAssembly、の解説
なんとコンテナの「次」なんですね!
これは驚いた。あんま深く考えてなかったから、共存ぐらいにしか思ってなかった。
wasm と java の違い
kotlin という rust の次に好きな言語のおかげで、java の抵抗も減ってます。
しかし、GC に抵抗ある人にとっては結構いい選択肢になると思います。
(あと java のバージョンかんりめんどくさい)
まとめ
詳しいことかつ当時の背景については、AI と一緒に書いた旧記事の項目を開いてみてみてください。
AIと一緒に描いた旧記事
最近、Vue や Nuxt、Nuxt UI を触れていて、「色々作れそうだな」と思うことが増えてきました。
一方で、JS の型システムがガバガバすぎて、Rust が恋しくなってきました。
そこで、WASM の存在を思い出し、Rust の強みを活かせる仕組みを急遽作ることにしました。
experiments-wasm-vue について
このリポジトリでは、Rust を WASM としてコンパイルし、Vue と連携する試みを行いました。
内容としてはシンプルで、BMP パーサーを作る際にお世話になった nom を活用し、四則演算パーサーを作ったものです。
当初、外部ライブラリを使うと WASM のコンパイルが難しいかと思っていましたが、入出力が絡まない処理なら問題なく通ることが分かりました。
LLVM が適切に変換してくれるらしく、「まじか…?」と驚きつつも、その柔軟さに感動しました。
リポジトリのリンク:
Vue の環境構築と WASM の連携
Vue の開発環境は Vite を使ってセットアップしました。 そのため、通常の Vue 開発とは少し異なり、Vite の設定にも気を配る必要がある点がポイントになります。
また、今後は Nuxt への連携も視野に入れているのですが、ここで引っ掛かったのが WASM を Node.js のモジュールではなく、Web サイトとして使える形式にビルドすることでした。
どーやら通常の HTML 同様の紐付け方をすれば OK らしい?ということが分かったので、今回はそうしました。
Nuxt のディレクトリ構造と WASM の管理方法
Nuxt4 から、主要なコンポーネントのディレクトリが/app に集約されるようになるそう。 なので、同じプロジェクト内で/wasm ディレクトリを作り、WASM のコードを管理するのが良さそうだと考えています。
まだ検証の余地はありますが、この方法なら Vue/Nuxt のコンポーネントと適切に連携できそうなので、今後試していきたいと思います。
今後の展望—ランタイムの構想
WASM の可能性を探る中で、「Web ブラウザ上で動く独自ランタイムを作ってみたい」とも考え始めました。
カーネルレベルの設計とまではいきませんが、例えば:
- ブラウザ内で動く軽量な仮想環境
- WASM の能力をフル活用できる処理オフロード
- Rust の型安全性を生かしたスクリプト実行システム
こういうの作ってみたいなって願望を持ってます。願望です。はい。
まとめ
wasm はいいぞ
参考など
- Vue ベースな Web ツールのロジック部分を Rust 製 Wasm で実装する: pirosuke 様
ディレクトリの構造等を参考にしました。 - Rust から WebAssembly にコンパイル/mdn
いつも通りめっちゃわかりやすい
なんで更新したの
リポジトリを綺麗にした記念です。 orphan ブランチ作って cherry-pick しまくり、main ブランチを完全に作り直しました。 また、まだ動かないコミットは dev ブランチに移動し、動作するようにさせました!
当時の記事にはmain コミットいじって動かなくなっちゃった!thprって書いてあって腹が立ったので描き直しました。
当時の自分に切れる
自分の敵は自分っちゅーことや
イケてる tui を作ってみる part1
tui: gui ではないが、コマンドラインで操作できる ui のこと
🎵 本日の一曲
ぎゅうたんたん
とりあえず一句
extern crate crossterm; use std::io::{Result, stdout}; use crossterm::{ExecutableCommand, cursor::MoveDown, execute, style::Print}; fn main() -> Result<()> { stdout() .execute(MoveDown(4))? .execute(Print("hello world"))?; Ok(()) }
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.06s
Running `target/debug/train_signal_sim`
hello world
行列自由に扱えるようになりますね。
queue について
extern crate crossterm; use std::{ io::{Result, Write, stdout}, thread::sleep, time::Duration, }; use crossterm::{QueueableCommand, style::Print}; fn main() -> Result<()> { let mut stdout = stdout(); stdout.queue(Print("hello\n"))?; sleep(Duration::from_secs(1)); stdout.queue(Print("world\n"))?; stdout.flush() }
1 秒経って
hello
world
と表示されると思っていた
実際には hello と表示された後に 1 秒待機になったで。
改行\nを抜いてみた
extern crate crossterm; use std::{ io::{Result, Write, stdout}, thread::sleep, time::Duration, }; use crossterm::{QueueableCommand, style::Print}; fn main() -> Result<()> { let mut stdout = stdout(); stdout.queue(Print("hello"))?; sleep(Duration::from_secs(1)); stdout.queue(Print("world"))?; stdout.flush()?; Ok(()) }
想定通り、1 秒経った後にhelloworldが表示された。
movedown で改行しよう
extern crate crossterm; use std::{ io::{Result, Write, stdout}, thread::sleep, time::Duration, }; use crossterm::{QueueableCommand, cursor::MoveDown, queue, style::Print}; fn main() -> Result<()> { let mut stdout = stdout(); queue!(stdout, Print("hello"), MoveDown(1))?; sleep(Duration::from_secs(1)); queue!(stdout, Print("world"), MoveDown(1))?; stdout.flush()?; Ok(()) }
hello
world
私はそんなスタイリッシュなのを求めていない。
movetonextline で改行しよう
extern crate crossterm; use std::{ io::{Result, Write, stdout}, thread::sleep, time::Duration, }; use crossterm::{cursor::MoveToNextLine, queue, style::Print}; fn main() -> Result<()> { let mut stdout = stdout(); queue!(stdout, Print("hello"), MoveToNextLine(1))?; sleep(Duration::from_secs(1)); queue!(stdout, Print("world"), MoveToNextLine(1))?; stdout.flush()?; Ok(()) }
hello
world
想定通りに動作したね。
m さんみたいなやつ
#?#
#?#?#
o
|
###################################
これを書いてみよう。
use std::{ io::{Result, Write, stdout}, thread::sleep, time::Duration, }; use crossterm::{ cursor::{MoveTo, MoveToNextLine}, queue, style::Print, terminal::{Clear, ClearType, size}, }; fn main() -> Result<()> { let mut stdout = stdout(); // 画面を初期化 queue!(stdout, Clear(ClearType::All))?; // サイズを確認する // 左上を1としてスタート // https://docs.rs/crossterm/latest/crossterm/terminal/fn.size.html let (col, row) = size()?; // 床の描画 for c in 0..col { queue!(stdout, MoveTo(c, row), Print("#"))?; } stdout.flush()?; Ok(()) }
とりあえず床だけ描画してみることにした。
#######################
イケてる tui を作ってみる part2
今回は標準入力を試してみます
🎵 本日の一曲
たまたま目に入ったので
百合注意
やっぱ琴葉姉妹百合最高だよな
...
リアルタイムで標準入力を受け取ってみよう
こんなかんじ
use std::{
io::{Result, Write, stdin, stdout},
thread::sleep,
time::Duration,
};
use crossterm::{
cursor::{MoveTo, MoveToNextLine},
event::{
EnableBracketedPaste, EnableFocusChange, EnableMouseCapture, Event, KeyEvent,
KeyboardEnhancementFlags, PopKeyboardEnhancementFlags, PushKeyboardEnhancementFlags, poll,
read,
},
execute, queue,
style::Print,
terminal::{Clear, ClearType, enable_raw_mode, size},
};
fn main() -> Result<()> {
// 色々な機能を無効にする
_ = enable_raw_mode();
// printlnなどの動作がおかしくなるので、crosstermの関数を使うようにする。
let mut stdout = stdout();
loop {
// 入力イベントの処理
if poll(Duration::from_millis(100))? {
if let Event::Key(event) = read()? {
execute!(stdout, MoveTo(0, 0), Print(format!("{:?}", event)))?
}
}
}
}とりあえずキーイベント only
KeyEvent {
code: Char('a'),
modifiers: KeyModifiers(0x0),
kind: Press,
state: KeyEventState(0x0)
}こんな感じの構造体が event の中に入ってる。
note
raw モードにしないと、enter を受け取るまで入力を待機してしまう
note
poll 関数を挟むと、(上記の例だと)100ms まって入力がなければ、false を返す(=イベントの処理をスキップする)
イベント楽しい
main 関数に設置した loop 文で、入力、処理、出力を繰り返す。 これを応用すると、ゲームとか作れる
おわり
subnautica、シーモス食われました。
資材集め大変です。
構造体で遊ぶ
この記事を書いた理由って必要ですか。
特に構造体推しでもないし、ネタ切れではあるけど、少しまとめとこと思っただけで理由って必要ですか。
(オリ曲のサビから抽出)
本日の一本
曲ストックが切れたので、次は動画でも共有しようかと思った。
これ本当草
(twitter の引用 RT かよ)
まず普通に定義する
classDiagram
class Point {
- usize x
- usize y
}
この UML の通りに構造体を定義してみます
struct Point { x: usize, y: usize, } fn main() { let p = Point { x: 3, y: 6 }; println!("{}", p); }
実行すりゃ破るけど、これだと普通にエラーになるわけで。
こいつは表示機能を持ってないからね。もしくは、println で表示する免許を持ってない。
Point 構造体に(とりあえず)Debugトレイトを実装しよう。
note
これを書いている頃の日記さんは、trait を免許とたとえてもいいんじゃないかという困ったどうでもいい考えを持ってます。
tip
実行すれば、コンパイルエラーと表示されるはずです。 (error: could not compile...)
コンパイルエラーは実行ファイルが作られないで発生するエラーです。 よって、コンパイルエラーが含まれているコードからはプログラムが発生しない。
コンパイルエラーは安全なのです。 一方、実行時に発生するエラーは安全ではないエラーです。
rust の安全性の一つは、コンパイルエラーが豊富なことだと感じます。(あくまで感想)
エラーが含まれるコードは、コンパイルの時点で弾いてくれるのでね。
Debug を定義する
classDiagram
direction TB
class Point {
-usize x
-usize y
}
class Debug {
- std::fmt::Result fmt()
}
<<Trait>> Debug
Point --|> Debug
多分こんな感じ
#[derive(Debug)] struct Point { x: usize, y: usize, } fn main() { let p = Point { x: 3, y: 6 }; println!("{:?}", p); }
derive マクロによってほぼ自動的に実装してもらいました。
println!の中身で、{}が{:?}に変わっていることに注意が必要です。
tip
#[]は手続きマクロと呼ばれるものですね。
この記事が詳しいと思います。
一方て、println!()と関数名の後ろに!がついているのは宣言マクロです。
可変長引数に対応する関数が作れます。
note
せっかくなので出力例を、おっと。
この mdbook というやつはコードブロックそのまま実行可能だったんだ。 ▶️ ボタンで実行可能。
文字列変換に対応させ、好きなフォーマットで出力できるようにする
classDiagram
direction TB
class Point {
-usize x
-usize y
}
class Debug {
- std::fmt::Result fmt()
}
<<Trait>> Debug
class Display {
- std::fmt::Result fmt()
}
<<Trait>> Display
Point --|> Debug
Point --|> Display
use std::fmt; #[derive(Debug)] struct Point { x: usize, y: usize, } impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}, {}", self.x, self.y) } } fn main() { let p = Point { x: 3, y: 6 }; println!("{}", p); assert_eq!(p.to_string(), String::from("3, 6")); }
Debug と異なり、Display はフォーマットを自分で作りたいので手動です。
Display はto_string()も間接的に実装してくれます ToString トレイトもありますが、Display を使っておけば両方に対応するのです。
write!マクロは println と使い心地が似てますが、先頭に Formatter を指定する必要があります。
ユーザーに自由な値を提供する
usize以外にも、u8でメモリを節約する、i32でプラマイに対応する、f64で小数点に対応させる、&strで文字列を扱うようにするなど、さまざまなユースケースが考えられます。
classDiagram
direction TB
class Point["Point < T >"] {
-T x
-T y
}
class Debug {
- std::fmt::Result fmt()
}
<<Trait>> Debug
class Display {
- std::fmt::Result fmt()
}
<<Trait>> Display
Point --|> Debug
Point --|> Display
use std::fmt; #[derive(Debug)] struct Point<T> { x: T, y: T, } impl<T> fmt::Display for Point<T> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}, {}", self.x, self.y) } } fn main() { let p = Point { x: 3, y: 6 }; println!("{}", p); assert_eq!(p.to_string(), String::from("3, 6")); }
残念ながらこれでは、コンパイルエラーになります。
問題点は「Display」です。 T が Display(もしくは ToString)を実装しているという確証がないのです。
T が特定のトレイトを実装している時のみ、メソッドの利用を許容する
rust のトレイトは、面白い機能があります。 メンバー変数が実装しているトレイトによって、使用できるメソッドを変化させられるのです!
use std::fmt; #[derive(Debug)] struct Point<T> { x: T, y: T, } impl<T> fmt::Display for Point<T> where T: fmt::Display, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}, {}", self.x, self.y) } } fn main() { let p = Point { x: 3, y: 6 }; println!("{}", p); assert_eq!(p.to_string(), String::from("3, 6")); }
構造体Pointは、型に制限なく作ることができます。 Display トレイトを実装してなくても、実装できます。
一方で、Point を Display に対応させるためには、型 T に Display トレイトを実装している必要があります。
足し算引き算できるようにする。
数学的なのはおいといて、x と y それぞれ足し引きできるようにします。 Addトレイト、およびSubトレイトです。
use std::{ fmt::{self, Pointer}, ops::{Add, Sub}, }; #[derive(Debug, PartialEq, Clone, Copy)] struct Point<T> { x: T, y: T, } impl<T> fmt::Display for Point<T> where T: fmt::Display, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}, {}", self.x, self.y) } } impl<T> Add for Point<T> where T: Add<Output = T>, { type Output = Point<T>; fn add(self, rhs: Self) -> Self::Output { let x = self.x + rhs.x; let y = self.y + rhs.y; Point { x, y } } } impl<T> Sub for Point<T> where T: Sub<Output = T>, { type Output = Point<T>; fn sub(self, rhs: Self) -> Self::Output { let x = self.x - rhs.x; let y = self.y - rhs.y; Point { x, y } } } fn main() { let p = Point { x: 3, y: 6 }; println!("{}", p); assert_eq!(p.to_string(), String::from("3, 6")); assert_eq!(p + p, Point { x: 6, y: 12 }) }
type は型に別名を与えるという役割を持ってます。型に名前をつけると、コメント以上に可読性が上がります。
オリジナルな型のように見えます。 構造体、enum の仲間みたいな。見えるだけでなく、可視性もそんな感じになったはず。
/// 戻り値は、kg単位で返却されます
fn latest_weight(id: usize) -> i32;
/// 戻り値は、cm単位で返却されます
fn latest_length(id: usize) -> i32;type Kg = i32;
type Cm = i32;
fn latest_weight(id: usize) -> Kg;
fn latest_length(id: usize) -> Cm;もう一つは、トレイト定義の自由度を高める使い方があります。
Add、Subなどの計算系トレイトの戻り値は、Output(出力)の方を自由に調整できます。
impl<T> Sub for Point<T>
where
T: Sub<Output = T> + Copy,
{
type Output = Point<T>;
}型 T 自体にも、T を Output とする Sub トレイトを実装している必要があり、
自身もPoint<T>を Output とする Sub トレイトを実装しています。
note
ついでに、Clone, Copy, PartialEq を実装しております
- Clone
構造体の複製を行う clone メソッドを追加する - Copy
デフォルトが move なのを、clone に置き換える
Copy まで実装しておくと楽です。
参照ではない時の値が move から copy に変わるため、所有権が奪われる心配が減ります。
一方で、インスタンスが増えてメモリを圧迫する、同じインスタンスだと思ったら別物だったなんてトラブルもつきます。
数値i32などでは、Copy が実装されています。
- PartialEq
値の比較ができるようになる。
参照で計算できるように工夫する
計算する度にコピーよりか、参照の方がいいと思った。でも中身で結局コピーしちゃうんだよね。
use std::{ fmt::{self}, ops::{Add, Sub}, }; #[derive(Debug, PartialEq, Clone)] struct Point<T> { x: T, y: T, } impl<T> fmt::Display for Point<T> where T: fmt::Display, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}, {}", self.x, self.y) } } impl<T> Add for &Point<T> where T: Add<Output = T> + Clone, { type Output = Point<T>; fn add(self, rhs: Self) -> Self::Output { let x = self.x.clone() + rhs.x.clone(); let y = self.y.clone() + rhs.y.clone(); Point { x, y } } } impl<T> Sub for &Point<T> where T: Sub<Output = T> + Clone, { type Output = Point<T>; fn sub(self, rhs: Self) -> Self::Output { let x = self.x.clone() - rhs.x.clone(); let y = self.y.clone() - rhs.y.clone(); Point { x, y } } } fn main() { let p = Point { x: 3, y: 6 }; println!("{}", p); assert_eq!(p.to_string(), String::from("3, 6")); assert_eq!(&p + &p, Point { x: 6, y: 12 }) }
Copy の方が楽ですね。
変換に対応させる
タプルから変換できると楽そうですよね。
use std::{ fmt::{self}, ops::{Add, Sub}, }; #[derive(Debug, PartialEq, Clone, Copy)] struct Point<T> { x: T, y: T, } impl<T> fmt::Display for Point<T> where T: fmt::Display, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}, {}", self.x, self.y) } } impl<T> Add for Point<T> where T: Add<Output = T>, { type Output = Point<T>; fn add(self, rhs: Self) -> Self::Output { let x = self.x + rhs.x; let y = self.y + rhs.y; Point { x, y } } } impl<T> Sub for Point<T> where T: Sub<Output = T>, { type Output = Point<T>; fn sub(self, rhs: Self) -> Self::Output { let x = self.x - rhs.x; let y = self.y - rhs.y; Point { x, y } } } impl<T> From<(T, T)> for Point<T> { fn from(value: (T, T)) -> Self { Point { x: value.0, y: value.1, } } } impl<T> From<Point<T>> for (T, T) { fn from(value: Point<T>) -> Self { (value.x, value.y) } } fn main() { let x: (i32, i32) = (2, 3); let x: Point<i32> = Point::from(x); let (x, y): (i32, i32) = x.into(); }
Fromトレイトを実装すると、変換が可能になります。 今回はタプルから Point へ、Point からタプルへ変換できるようにしました。
main 関数では、相互変換を実装しています。
2 行目は From の使い方です。 from はいわゆる静的メソッドであり、new メソッドのように新たなインスタンスを作ることを目的としています。
つまり、変換先のインスタンスは別物です。 そりゃそう。
一方で、3 行目は into メソッドによってタプルに変換されています。インスタンスについているメソッドですね。
From トレイトを実装すると、自動的に実装されます。
note
Into は From の逆だと聞いて、相互変換と考えてしまった時期がありました。
実際には、静的メソッドかただのメソットか、その差です。
相互変換に対応させるために、お互いに From トレイトを適用しています。
これによって相互変換ができるようになるのです。
into 使う時は、型注釈が必要です。
まとめ
オリ曲の存在を証明するには、私の頭を解剖するしかない。
クレート紹介 part1
書くネタないわけでは)ないです。
本日の一言
これはやばい。 浄化されて消えかける。
anyhow
エラー処理がぐーんと楽になるやつです。 標準で Error トレイトが存在するのは知ってましたが、使わざる得なくなりました。
anyhow::Result
anyhow::Result を使えば、他のことを考えないで済むようになりました。
anyhow::anyhow
anyhow マクロです。
extern crate anyhow; use anyhow::{anyhow, Result}; fn main() -> Result<()> { let reason = "エラープログラムだから"; Err(anyhow!("原因は{}", reason)) }
Error トレイトを実装したオブジェクトを文字列から簡単に作れます。
format も使えるので、{:?}でオブジェクトの中身を表示させられたりすることもできます。
anyhow::bail ensure
extern crate anyhow; extern crate rand; use anyhow::{Result, bail}; fn main() -> Result<()> { if rand::random() { bail!("random error"); } Ok(()) }
anyhow!に加え、return Err()まで実装してくれるマクロです。
extern crate anyhow; extern crate rand; use anyhow::{Result, ensure}; fn main() -> Result<()> { ensure!(rand::random::<bool>(), "random error"); Ok(()) }
assert!と同じような効果を持ってます。
使い方
strum
enum を使いやすくしてくれます。
enum との変換が楽になる
#[derive(Debug, Clone, PartialEq, Eq, strum_macros::Display, strum::EnumString)]
pub enum Version {
#[strum(serialize = "HTTP/1.0")]
Http10,
#[strum(serialize = "HTTP/1.1")]
Http11,
#[strum(serialize = "HTTP/2.0")]
Http20,
#[strum(serialize = "HTTP/3.0")]
Http30,
}EnumStringはFromStrトレイトを実装してくれます。
おかげで、
Version::from_str("HTTP/1.0");と、文字列から enum オブジェクトを生成できる他
Displayによって、トレイトのディスプレイを自動で実装できます。
上記のように、オブジェクトを持つというより、バージョンや定数を管理する時に楽になります。
使い方
構文解析 part1
公開日:2025/08/28
構文解析について、お話しします。
ひとくちメモ
彩澄姉妹が最近好きでして。
初めて声を聞いたのは、ほんの偶然というか。ボイロ劇場みてたらナレーターとして使われてた。
りりねぇが少なめですまねぇ。決してアレではない
参照(ポインタ)
C を学ぶ時、ポインタを知ります。 ポインタってどこで使うんだとなるわけです。
rust にもポインタが存在しますが、近い存在として参照があります。
tip
一方 C にも参照は存在する
じゃあ実際参照とポインタって何が違うんだよ
って話になるよね。
独自研究マシマシで回答を作成してみると
rust ではポインタの登場頻度は低い方だと思います。 参照は所有権的問題をクリアするためにある、そういった物です。
一方ポインタはあくまでアドレスのみの管理です。型も大雑把にしか管理しません。 rust では unsafe となります。
C のポインタ、参照も似てる。 ポインタはキャストすれば int を char として扱うなんて容易いし。
compiler explorerで見てみる
compiler explorerはコンパイラーが出力するアセンブリを表示する web サイトです。便利。
int main() {
int x = 3;
int& y = x;
int z = x;
return 0;
}
main:
push rbp
mov rbp, rsp
mov dword ptr [rbp - 4], 0
mov dword ptr [rbp - 8], 3
lea rax, [rbp - 8]
mov qword ptr [rbp - 16], rax
mov eax, dword ptr [rbp - 8]
mov dword ptr [rbp - 20], eax
xor eax, eax
pop rbp
ret
block-beta
columns 1
A ["先頭"]
B ["rbp-8: x"]
C ["rbp-16: y"]
D ["rbp-20: z"]
スタックを雑にまとめるとこうなりますね。
rbp という先頭アドレスから、いくら離れているかを載せています。
なお、アドレスはバイトごとに管理されるため、rbp-1 は、rbp から 8bit 離れているということになります。
一方で、mov は move という意味です。
mov dword ptr [rbp - 8], 3
なんてrbp - 8に 3 という値を代入(移してる)しているという意味なので、簡単です。
lea はアドレスを取り出すという物です。 64bit コンピューターなので、アドレス長は 64bit
その位置はちょうど参照yになってるところです。 y は x のアドレスを持っています。
int main() {
int x = 3;
int *xp = &x;
}
ポインタで書き直しました。
main:
push rbp
mov rbp, rsp
mov dword ptr [rbp - 4], 3
lea rax, [rbp - 4]
mov qword ptr [rbp - 16], rax
xor eax, eax
pop rbp
ret
やってることはほとんど同じですね。
rust では安全な参照が、c ではポインタがよく使われています。
参照が安全なのは前述の通り、rust ではアドレス以上に所有権などの考慮もしながら扱う物だからです。多分。
アセンブリからしたら型もくそもないけれど、コンパイラの時点で変数が用途通り使われているのを確認できているので問題ないのです。
指定した容器に情報を詰め込んで
今マイバック持参とかあるじゃないですか。あとマイカゴ。
マイカゴって、スーパーのレジ店員に渡すとそのまま品物を中に詰めてくれるので、こちらとしてそのまま車に詰め込んで、持ち帰って終わるだけなので楽なんですよね。
#[derive(Debug)] struct Goods<'str> { _name: &'str str } fn registrar<'str>(mut unpurchased: Vec<Goods<'str>>, mybag: &mut [Option<Goods<'str>>]) -> (usize, Vec<Goods<'str>>) { let mut counter = 0; for i in mybag.iter_mut() { if i.is_none() { *i = unpurchased.pop(); counter += 1; } } (counter, unpurchased) } fn main() { let unpurchased_list = vec![Goods{_name: "pan"}, Goods{_name: "kome"}, Goods{_name: "tofu"}]; let mut my_bag: [Option<Goods>; 2] = [None, None]; let (size, pra_bag) = registrar(unpurchased_list, &mut my_bag); println!("レジ袋: {:?}", pra_bag); println!("マイバッグに入れられた品物: {:?}", my_bag); println!("マイバッグに入れられた品物の数: {}", size); }
というのを想像して書いてみたらこういうプログラムができました。
Cloneを実装してないので商品(Goods)は move のみできます。現実の商品コピーできないからね。
レジ(registrar)にはカゴ(unpurchased_list)とマイバッグ(my_bag)を渡します。
なお、マイバックは一時的に貸しているものであり、帰ってきます。 参照渡しとはそういうことです。
会計が済めば、入り切らなかった商品がレジ袋(pra_bag)に詰められて帰ってきます。
丁寧な店員なので、マイバッグに入った品物の数も答えてくれました。
「あんちゃんが渡してくれた袋に二品つっこめたで」
ポインタのほんの一つの使い方はこんな感じです。
rust では一時的に貸すという表現ができますねぇ。
そのまま渡して返して貰えばいいのでは?
レジ袋って無駄だと騒がれてるじゃん?
C 言語の関数の戻り値ってアドレスが異なるのです。
正しくは、関数の結果を変数にコピーするという動作を行ったはずです。
rust ではあんまり関係ないですが。少なからず戻り値での受け渡しは無駄が生じる可能性があるということです。
また、現実の my_bag 同様、変数の再利用ができます。
変数って作るときにコストが生じます。 特に Box で作るとなると、ヒープ確保にコストがかかります。
java なら GC があるので、GC が回収するオブジェクトが無駄に増えることになります。
変数って単純なようで奥深いです。 rust ではトレイトがあります。
トレイトオブジェクトでリストを管理すれば、変数の扱いを自分なりにカスタマイズできるようになるのです。
とにかく、自分が用意したものを相手に使ってもらいたい時に、ポインタは有用だということなのです。
note
rust では参照です。
関数をやり取りする時
関数を変数として扱うことがあります。
fn func() {}
fn main() {
let f = func;
}rust においてこの構文は、f は関数の参照を持っているという扱いになります。
計算に使用される数値、文字を表現するために使われる文字列。これらは値として管理することができます。
一方で、関数は値というより、式の一つと考えられます。 式が値になるというこんがらがるような状況になります。
しかし関数値というのは存在しません。関数を 「指し示す」 参照が存在するだけです。 参照は「値」です。
関数をさす参照という値を使うことで、引数を通じて他の関数に関数を渡すことができます。
tip
C では関数ポインタが使われます
コールバック関数
それこそがコールバック関数です。
mod my_crate { use std::time::Duration; use std::thread::sleep; pub fn callback(func: impl FnOnce(&str)) { sleep(Duration::from_secs(2)); func("callback"); } } fn func(i: &str) { println!("hello world {}", i); } fn main() { let f = func; my_crate::callback(f); }
my_crate::callbackは、my_crate というクレート(つまりライブラリ)のcallbackという関数のことです。
コードをあえて隠してますが、表示すればモジュールが見えるはずです。
callback という関数は、2 秒待機した後にユーザーが指定した関数を呼び出します。
呼び出される関数はユーザーが自由に設計できます。(ただし引数と戻り値は一致しなければならない)
コールバック関数の出番
- 〇〇した後に呼び出す(処理順序)
主に非同期処理で見られます。 非同期でなくても、マルチスレッドで可能。
処理が終えた時にユーザーの関数を実行するという動作をします。 - 関数の自由度を高めるため
引数、戻り値だけを指定し、ユーザーに処理を考えて欲しいことがあります。 あとで出てきます。
note
イベント駆動する javascript では、イベントとして関数を登録し、ファイルが読み込み終わった時などにイベント発火として関数が呼び出されます。
関数を作る関数
ややこしい概念です。
fn func_builder(msg: &str) -> impl Fn(&str) { let msg = msg.to_string(); move |user| println!("dear {}\n{}", user, msg) } fn main() { let f = func_builder("hello! have a nice day!"); f("nikki"); }
|| {}はクロージャです。 他言語ではアロー関数、ラムダ関数とか呼ばれたりします。
特徴として、値のように関数の中で関数が定義できます。
Fnトレイトは、関数トレイトです。 関数型として変数を管理することができます。
戻り値を関数型にするために使ってます。 先ほどは引数にも使ってました。
コンビネーター
callback 関数は他に、関数を加工する時、関数を組み合わせる時に便利に使われます。
fn can_i_help_you() { println!("いらっしゃいませこんにちは"); } fn booko0f(func: impl Fn()) { for _ in 0..3 { func(); } } fn main() { booko0f(can_i_help_you); }
関数を組み合わせて機能を強くする例です。ブック ⚪︎ フか。
パーサー
こういうやつです。
fn digit_parser(i: &str) -> (&str, Option<i32>) { let n = i.find(|c: char| !c.is_ascii_digit()).unwrap_or(0); if let Ok(res) = i[0..n].parse::<i32>() { (&i[n..], Some(res)) } else { (&i, None) } } fn main() { let x = "123hello"; let (x, y) = digit_parser(x); println!("{:?}, {:?}", x, y); }
文字列から数値だけ抽出します。 その後、数値と文字列を分割して出力します。
rust ではシャドーイングする設計にすると綺麗です。
パーサーコンビネーター
fn digit_parser(i: &str) -> (&str, Option<i32>) { let n = i.find(|c: char| !c.is_ascii_digit()).unwrap_or(0); if let Ok(res) = i[0..n].parse::<i32>() { (&i[n..], Some(res)) } else { (&i, None) } } fn looparser<P, T>(parser: P) -> impl Fn(&str) -> (&str, Option<(&str, T)>) where P: Fn(&str) -> (&str, Option<T>) { move |i| { for n in 0..i.len() { let (i2, res) = parser(&i[n..]); if let Some(res) = res { return (i2, Some((&i[..n], res))) } } (i, None) } } fn main() { let x = "hello123world"; let (x, y) = looparser(digit_parser)(x); println!("{:?}, {:?}", x, y); }
コードが急にカオスになりました。
looparser
名付け適当 digit_parser は「数文字が先頭から続く範囲で数値を取り出します。」
つまり、途中の数値は取り出されません。
fn digit_parser(i: &str) -> (&str, Option<i32>) { let n = i.find(|c: char| !c.is_ascii_digit()).unwrap_or(0); if let Ok(res) = i[0..n].parse::<i32>() { (&i[n..], Some(res)) } else { (&i, None) } } fn main() { let x = "hello123"; let (x, y) = digit_parser(x); println!("{:?}, {:?}", x, y); }
数値が後ろになるだけでパースできなくなりました。 looparser では、パーサーが成功するまで文字列の先頭をずらしながら試行錯誤するという物です。
よって、"hello123world"では、6 文字目から digit_parser が成功し、数値に変換して返すということができるようになりましたとさ。
パーサーという関数を受け入れる関数
looparser では、関数をあたかもParser というオブジェクトのように扱っています。
こういった時にも関数ポインタは必要になるのですね。
コード解説
fn digit_parser(i: &str) -> (&str, Option<i32>) {
let n = i.find(|c: char| !c.is_ascii_digit()).unwrap_or(0);
if let Ok(res) = i[0..n].parse::<i32>() {
(&i[n..], Some(res))
} else {
(&i, None)
}
}i は文字列。 str.find()は、引数にコールバック関数を入れます。
ここでもコールバック関数がっ...
コールバック関数の引数は char にしておきます。 そうすることで、find メソッドがコールバック関数に先頭から文字を一文字づつ入れて、試してくれます。
コールバック関数の戻り値は bool です。 true を返すと、成功(=条件に合う文字)と判定されます。
つまり、find メソッドは先頭から一文字ずつ試していき、条件に会う文字を見つけたらその文字があるインデックスを返すというメソッドになります。
戻り値
戻り値は(&str, Option)という形をとってます。
let base = "123hello";
let (base, res1) = parser1(base);
let (base, res2) = if res1.is_none() {
parser2(base)
} else {
(base, None)
}まぁこんな感じの書き方ができるよねってことで。
クロージャのキャプチャ
fn looparser<P, T>(parser: P) -> impl Fn(&str) -> (&str, Option<(&str, T)>)
where P: Fn(&str) -> (&str, Option<T>)
{
move |i| {
for n in 0..i.len() {
let (i2, res) = parser(&i[n..]);
if let Some(res) = res {
return (i2, Some((&i[..n], res)))
}
}
(i, None)
}
}moveというのは所有権関係の物です。
looparser のスコープにはparserというこれまた関数オブジェクトが存在します。
このparserの所有権を、クロージャに移動することを認める一言になってます。
クロージャ内部では、キャプチャした parser オブジェクトがそのまま使えます。 つまり、looparser でうけっとったコールバック関数を、クロージャ内部で使うことができるということになります。
looparser は戻り値で関数ポインタを渡してきますが、そのクロージャでも looparser が受け取ったコールバック関数が引き続き利用可能です。
note
impl について、これをつけておくとプログラムサイズを犠牲に、どんなものにも対応できるように関数が作られます。
どういうことかって、トレイトは本来、実体しないものです。 サイズがわかりません。
おそらくトレイトが実装されている元のオブジェクトをたどって、どんなオブジェクトも受け入れられるように関数を作る、そういうことだと勝手に理解してます。
なお、引数で impl を使うときはジェネリクスと where で一度定義する必要があります。
今回のまとめ
ポインタからコールバック関数、そしてパーサーコンビネーターまでとりあえず纏めてみました。
本題まで行けてないのが悲しい。
本日の二言
本日が終わるまであと 4 時間です。 急いで書きました。
え?何してたって? 単純に記事のボリュームがデカすぎるという問題もあるのですが、MyParserProject どうしようかなって考えてました。
実はそれをいじってて急遽書いた記事でもあります。
...それだけじゃないだろって?
あのですね。 ブルアカってゲームあるじゃないですか。
最近ワイルドハント芸術学院という学院が追加(※)されまして、そこに所属する二人が予想以上に可愛くてね。
note
いろんな記事曰くワイルドハント芸術学院自体はリリース初期から存在するそうです。
所属するキャラがプレイアブルキャラクターとして追加されたのは正真正銘今回が初です。
魔女っ子よくね? やっぱいいよな。白尾エリめっちゃいいよな?
いや、ワイルドハント芸術学院、能力的には他のキャラで代用できるし、そもそも進化用のノートが独自の枠だから集めるのめんどいし
ぶっちゃけ微妙だよな... 引こうかな...
でもチケット 2 枚残ってるんだよね
...
結果
2敗
🟦🟨🟦🟦🟦
🟦🟦🟦🟦🟦
🟦🟨🟦🟦🟦
🟦🟦🟦🟨🟦
構文解析 part2
今回は一瞬で終了します。 ひとくちメモレベル
本日の一言
ペロロジラのおかげで、自分が持つキャラの中でも神秘キャラが一番弱いことに気づきました。
思えば振動キャラが少ないと思ってたので、そればかり強化してたし、神秘キャラとをほぼ同一視してたのでこうなることは仕方なかったと思います。
現時点では、取り急ぎワカモと臨戦ホシノを強化することにしました。 アビドスのノートほぼ残ってない...
びびりっか
パーサークレートについて
rust には nom というパーサークレートが存在する。
chumsky というパーサークレートも存在する。
使い分け、わからん。
When to use this instead of nom? (chumsky の issue より)曰く、
(要約)
nom はバイナリ向け。 chumsky は文字列向け。
とのこと。
あと、Logos というクレートも存在し、これはLexerと呼ばれるもの。
Understanding the Differences – Lexer vs. Parser Explained
どれも文字列やバイナリ列などのコードを解釈し、オブジェクトやトークンに直すもの、そう理解してる。
Logos を使ってみる
use logos::Logos;
#[derive(Logos, Debug, PartialEq)]
#[logos(skip r"[ \t\n\f]+")] // Ignore this regex pattern between tokens
enum Token {
// Tokens can be literal strings, of any length.
#[token("+")]
Add,
#[regex("[0-9]")]
Number,
}
fn main() {
let mut lex = Token::lexer("1 + 1");
assert_eq!(lex.next(), Some(Ok(Token::Number)));
assert_eq!(lex.next(), Some(Ok(Token::Add)));
assert_eq!(lex.next(), Some(Ok(Token::Number)));
}こんな感じで、大雑把にそれが何なのかを表してくれる。 文字列で出力するようにすれば
fn main() {
let mut lex = Token::lexer("1 + 1");
println!("{:?}, {:?}", lex.next().unwrap(), lex.span());
println!("{:?}, {:?}", lex.next().unwrap(), lex.span());
println!("{:?}, {:?}", lex.next().unwrap(), lex.span());
}Ok(Number), 0..1
Ok(Add), 2..3
Ok(Number), 4..5
example の json を動かしてみる
コードはこれ git clone で持ってきた方が楽。
cargo run --example json -- <filename>.json
で動かせる。
{
"name": "yjsnpi",
"age": 24
}
Object(
{
"\"name\"": String(
"\"yjsnpi\"",
),
"\"age\"": Number(
24.0,
),
},
)
感想(2025/08/29 時点)
ほぼ私が想像するパーサー?
言語はもちろん、json みたいな独自のデータ記述言語を扱う時には Logos を使った方が手っ取り早いかもしれない。
chumsky を使ってみる
use chumsky::{
Parser,
error::Simple,
extra,
prelude::{any, end, just},
};
fn main() {
let base = ":helloworld";
let parser = just::<_, _, extra::Err<Simple<char>>>(':')
.then(any().repeated())
.then(end());
let x = parser.parse(base);
println!("{:?}", x);
}parse というメソッドを使うことでパースされます。
them メソッドでパーサーを連結させることができます。
ドキュメント
ガイド をベースに軽く触れてみました。
repeated について
repeated メソッドを使うことによって、パーサーを繰り返し実行することができるようです。any パーサーは終端文字以外の全てにマッチするようなので、マッチする間は繰り返されます。
ところでこれ、イテレーターに近い動作をします。
IterParser
IterParser repeated メソッドをつけると、実装されたパーサーになります。
と言いつつ、使えるのは fold および collect のようです。 map や filter はrepeated の手前で行うらしい。
感想(2025/08/29 時点)
まだ正気よくわかってない。
nom
だいぶ前から使ってきた。
stream vs complete
最初のページに書かれている通り、一部のパーサーで動作が変わってくる。
alpha0 は 0 以上のアルファベットキャラクターをパースする。正規表現で言う[a-zA-Z]*である。
"abcd"のように仮に全てパースに成功する場合でも、stream は続きがあると想定され、パースが失敗するまで(;などの文字にぶち当たるまで)はエラーを出力する。
コード例
use chumsky::{
IterParser, Parser,
error::Simple,
extra,
prelude::{any, end, just},
};
mod nom_parser {
use nom::{
IResult, Parser,
character::complete::{alpha0, char},
sequence::pair,
};
pub fn parser(i: &str) -> IResult<&str, (char, &str)> {
pair(char(':'), alpha0).parse(i)
}
}
fn main() {
let base = ":helloworld";
let parser = just::<_, _, extra::Err<Simple<char>>>(':')
.then(any().repeated().collect::<String>())
.then(end());
let x = parser.parse(base);
let y = nom_parser::parser(base);
println!("{:?}", x);
println!("{:?}", y);
}ParseResult { output: Some(((':', "helloworld"), ())), errs: [] }
Ok(("", (':', "helloworld")))
下が nom によるパース結果です。 Result は nom の方がシンプルにできてるように見えます。
char はそのままだと型予測ができないので、何かしらの方法で型注釈をしないと使えなかったです。
pair でまとめましたが、この場合はこう書いた方が自然らしい。
let (i, r1) = char(':')(i)?;
let (i, r2) = alpha0(i)?;
Ok(i, (r1, r2))参考サイト
Rust: nom によるパーサー実装が相当丁寧にまとまっていてわかりやすいです。
nom はバイナリ向きか
byte モジュールにバイトデータを扱うための関数があります。
nom は多種多様な用途で使用可能な構造に見えました。
しかし、文字列系の関数については chumsky の方が簡単に使える気がします。
まとめ
chumsky についてもっと深めたい。
nom は多機能なのと、バイナリに向いている気がします。
ところでバイナリ解析とは
バイナリも文字列同様、二進数列です。
文字解析の場合は記号や文字の並び順で解析し、それに従ってオブジェクトを作ります。
バイナリの場合はプロトコルや規格でどこに何があるか、1bit 単位で位置が決まってることがほとんどなので、
それに従って使いやすいオブジェクトに変換していきます。
本日の二言
いやぁまじで草可愛い。
ちっちゃな私聞いてて思わずタグ検索「はじめてのチュウ 重音テト」してしまった。
MIMI さんの PV 好きすぎて。
Minecraft 系
Minecraft の mod や plugin、コマンドなどを扱う時の備忘録を集めてます。
なお、個別プラグインの備忘録は個別で書いている場合があります。
- 基礎編
mod にも plugin にも通用しそうなことを書いてます。 - plugin 編 主に bukkit 系 プラグインの話題を書いています。
- mod 編 主に forge、それと fabric 系の話題を書いています。
基礎編 part1
地味に gradle について理解を深める必要があるため、それを先にやってしまいたいと思います。
🎵 本日の一曲
夏ですね。 暑い、暑い、暑すぎる。
ところで爽快感のある曲はいいですね。 木陰に隠れる琴葉姉妹を見て、そういえば木陰は本当に涼しいことを思い出しました
湿度などによりますが、木陰は嫌な暑さだとは思わないんすよね。 ただ、近くを車が通っていたり、室外機があったりすれば別ですが。
...山しかなくね?そんなとこ。 山は割と涼しい。 つまり木陰が涼しいというより山が涼しい。 qed 署名終了。(強引)
前提について
筆者は mac 環境および linux 環境で作業してます。 最近 windows と縁がないもので...
java について、openjdk がおすすめです。 といってもたくさんありますので、おすすめ書いときます
note
ここでインストールしておく必要はありません。 sdkman でまとめて導入可能です。
sdkman を入れてみる
sdkman
最近人気な、シェルスクリプトを用いて全自動で入れてくれるやつでインストールできるのかぁ。
apt install -y unzip # 必要とのこと
curl -s "https://get.sdkman.io" | bash
sdk install gradle # graldeを入れる
> gradle -v
Welcome to Gradle 8.14.2!
Here are the highlights of this release:
- Java 24 support
- GraalVM Native Image toolchain selection
- Enhancements to test reporting
- Build Authoring improvements
For more details see https://docs.gradle.org/8.14.2/release-notes.html
------------------------------------------------------------
Gradle 8.14.2
------------------------------------------------------------
Build time: 2025-06-05 13:32:01 UTC
Revision: 30db2a3bdfffa9f8b40e798095675f9dab990a9a
Kotlin: 2.0.21
Groovy: 3.0.24
Ant: Apache Ant(TM) version 1.10.15 compiled on August 25 2024
Launcher JVM: 21.0.8 (Ubuntu 21.0.8+9-Ubuntu-0ubuntu124.04.1)
Daemon JVM: /usr/lib/jvm/java-21-openjdk-arm64 (no JDK specified, using current Java home)
OS: Linux 6.10.14-linuxkit aarch64
> which gradle
/root/.sdkman/candidates/gradle/current/bin/gradle
> echo $PATH
/root/.sdkman/candidates/gradle/current/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
イイネ 👍
note
which sdkを試したがなぜだかコマンドが出なかった。 set など調べると、シェルスクリプトの関数として動いているようだ。
なんと java も入る。
sdk install java 21.0.8-zulu
色々触れてみる
gradle initでプロジェクトを生成できる。
WORKDIR=$(mktemp -d);
cd $WORKDIR;
# gradleプロジェクトを初期化する
gradle init
とりあえず環境構築まで
sdkman は革命だね。 次回以降は割と簡単に進むと思います。
以下過去の話
java の入れ方
JAVA_HOME の設定などをお勧めされているのや、PATH を設定しているのをよく見ますが、あれ意味を理解していれば効率よく運用できるはずです。
PATH とは(AI による説明)
- PATH は環境変数のひとつで、OS に「どこにコマンドを探しに行くか」を教える役割を担っています。
- コマンド実行時、PATH に登録されたディレクトリの順序に従って、最初に見つかった同名ファイル・コマンドが使われます。
- PATH が空だと OS は「どこを探せばよいかわからない」ので、どんなコマンドもフルパス指定が必要になります。
例:/bin/ls のように絶対パスで書けば実行可能
でも、単に ls とだけ入力しても "command not found" になります export PATH="$PATH:/your/custom/path"で PATH に使うディレクトリを追加可能。
PATH=$PATHがないと、既存の PATH が消えるので注意
# 個人用実行ファイルを作ってみた
WORKDIR=$(mktemp -d)
cd $WORKDIR
# 実行ファイル作成
cat << EOF > run.sh
#!/bin/sh
echo "hello world"
EOF
chmod +x run.sh # 実行権限設定
./run.sh # 実行可能
export PATH="$PATH:$WORKDIR" # パスに追加してみる
run.sh # 実行可能
echo $PATH # PATHの内容もこれで確認可能
なーるほど。 そうやって使うのね。 完全に理解した。
てか、シェルの変数と環境変数、ごっちゃになりそうだな。なんで export って名前なんだろう。
しかもシェルはアクセス方法が変数、環境変数ともに差がないんだよなぁ。
JAVA_HOME について
最近使ってないからわからなくなった。 考えるのをやめた。思考停止。
つまり不要ってことだ。
direnv を使おう
- direnv
ディレクトリごとに環境変数を変えられるのが特徴。 マインクラフトは java1.12 以降 jre/jdk8 が必要、確か 1.19 以降は jre/jdk17、1.20 以降は jre/jdk21 が必要である。
これは mod 開発時にも影響を及ぼす。 そのときに使えるのが direnv である。
note
ただし、後述する gradle をうまく活用すれば問題ないと思うけれど
Toolchains for JVM projects
...ん?
.......ん????
gradle について
java 版の cargo です。 これを使えば外部コードの連携から、ビルド、テストまで、行ってくれます。 多分優れもの。
tmpにプロジェクトを作ってみましょう。
gradle を導入してみよう。
gradle も バージョン依存激しいです。
とりあえず最新版入れてればなんとかなりますが...
brew install gradle(sdkman を使う場合は sdkman を入れてみるの項目で説明)apt install gradle
この辺のコマンドで入るかと。
caution
流石に適当言ってられないから、docker で無理やりapt install -y gradleしたんだけど、ぼくのしってる挙動とちがうんだけどー!
...
gradle -v
Gradle 4.4.1
古すぎるじゃねぇか!!!
tip
ああ、windows をお使いで?
wslgも参考のこと
これで(Linux 環境が)できた。
基礎編 part2(随時更新予定)
前回 sdkman が使いやすいというお話を致しました。
追記
投稿日とバージョンについて
後述しますが、gradle はバージョンによっての変化が激しいため、先に日程と gradle の最新版の確認をお願いします。
なお、日記さん側でも変化があったら修正するよう心掛けるつもりではありますが、放置する可能性もあるのでよろしくお願いします。
- 投稿日: 2025/07/28
- Gradle の Version:
Gradle 8.14.2
🎵 本日の一曲
PV 可愛すぎる
星界ちゃんとお出かけしたいよね。
gradle で環境構築をしてみる
gradle initを実行すると、最初に
- Application(実行ファイル)
- Library(ライブラリ)
を聞かれる。(あと Basic と Gradle plugin があるがここでは省略) 実際に生成してみて違いを確かめてみた。
アプリケーションの場合
>gradle init
Select type of build to generate:
1: Application
2: Library
3: Gradle plugin
4: Basic (build structure only)
Enter selection (default: Application) [1..4] 1
Select implementation language:
1: Java
2: Kotlin
3: Groovy
4: Scala
5: C++
6: Swift
Enter selection (default: Java) [1..6] 2
Enter target Java version (min: 7, default: 21): 21
Project name (default: tmp.q5kXPDaYCv):
Select application structure:
1: Single application project
2: Application and library project
Enter selection (default: Single application project) [1..2] 1
Select build script DSL:
1: Kotlin
2: Groovy
Enter selection (default: Kotlin) [1..2] 1
Select test framework:
1: kotlin.test
2: JUnit Jupiter
Enter selection (default: kotlin.test) [1..2] 1
Generate build using new APIs and behavior (some features may change in the next minor release)? (default: no) [yes, no]
> Task :init
> Learn more about Gradle by exploring our Samples at https://docs.gradle.org/8.14.2/samples/sample_building_kotlin_applications.html
BUILD SUCCESSFUL in 13s
1 actionable task: 1 executed
>tree
.
├── app
│ ├── build.gradle.kts
│ └── src
│ ├── main
│ │ ├── kotlin
│ │ │ └── org
│ │ │ └── example
│ │ │ └── App.kt
│ │ └── resources
│ └── test
│ ├── kotlin
│ │ └── org
│ │ └── example
│ │ └── AppTest.kt
│ └── resources
├── build
│ └── reports
│ └── configuration-cache
│ ├── 4oniusdp5r7fugbijssf0wr1j
│ │ └── 5q136g6kyf5rmfirte8rxuy4s
│ │ └── configuration-cache-report.html
│ └── ey2md2b405fd5q446rzq48txv
│ └── 74ftzik9peji2a08l95gz9c0j
│ └── configuration-cache-report.html
├── gradle
│ ├── libs.versions.toml
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradle.properties
├── gradlew
├── gradlew.bat
└── settings.gradle.kts
22 directories, 12 files
ライブラリプロジェクトの場合
> gradle init
Select type of build to generate:
1: Application
2: Library
3: Gradle plugin
4: Basic (build structure only)
Enter selection (default: Application) [1..4] 2
Select implementation language:
1: Java
2: Kotlin
3: Groovy
4: Scala
5: C++
6: Swift
Enter selection (default: Java) [1..6] 2
Enter target Java version (min: 7, default: 21): 21
Project name (default: tmp.vVJk4Hd6GU):
Select build script DSL:
1: Kotlin
2: Groovy
Enter selection (default: Kotlin) [1..2] 1
Select test framework:
1: kotlin.test
2: JUnit Jupiter
Enter selection (default: kotlin.test) [1..2] 1
Generate build using new APIs and behavior (some features may change in the next minor release)? (default: no) [yes, no]
> Task :init
> Learn more about Gradle by exploring our Samples at https://docs.gradle.org/8.14.2/samples/sample_building_kotlin_libraries.html
BUILD SUCCESSFUL in 9s
1 actionable task: 1 executed
.
├── gradle
│ ├── libs.versions.toml
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradle.properties
├── gradlew
├── gradlew.bat
├── lib
│ ├── build.gradle.kts
│ └── src
│ ├── main
│ │ ├── kotlin
│ │ │ └── org
│ │ │ └── example
│ │ │ └── Library.kt
│ │ └── resources
│ └── test
│ ├── kotlin
│ │ └── org
│ │ └── example
│ │ └── LibraryTest.kt
│ └── resources
└── settings.gradle.kts
15 directories, 10 files
生成されたソースファイル
cat app/src/main/kotlin/org/example/App.kt
/*
* This source file was generated by the Gradle 'init' task
*/
package org.example
class App {
val greeting: String
get() {
return "Hello World!"
}
}
fun main() {
println(App().greeting)
}
cat lib/src/main/kotlin/org/example/Library.kt
/*
* This source file was generated by the Gradle 'init' task
*/
package org.example
class Library {
fun someLibraryMethod(): Boolean {
return true
}
}
rust 同様、エントリーポイントになる main 関数が存在しない場合は Library となりそうだ。
kotlin.test もちょっと気になる
/*
* This source file was generated by the Gradle 'init' task
*/
package org.example
import kotlin.test.Test
import kotlin.test.assertNotNull
class AppTest {
@Test fun appHasAGreeting() {
val classUnderTest = App()
assertNotNull(classUnderTest.greeting, "app should have a greeting")
}
}
kotlin-test は kotest と改名された?らしい1 2
と思ったけど build.gradle 見てみたら
// Use the Kotlin JUnit 5 integration.
testImplementation("org.jetbrains.kotlin:kotlin-test-junit5")
// Use the JUnit 5 integration.
testImplementation(libs.junit.jupiter.engine)
JUnit やったし。
JUnit の特徴として、アノテーションが挙げられるらしい? kotest はBDD 形式というのが用いられてるとのこと。3
そもそも unit test ってなんだ。
単体テスト。
note
unit は単体、一人、一個、単位などを意味する名刺4
unit ってまとまったみたいな意味を持ってるのかと思ってたわ。
統合テスト、これは英語だと integration test になるらしい。 integration は統合って意味を持つのか。
漢字読み間違えてた。 結合じゃなくて統合か。
rust は統合テストをtestsディレクトリに、単体テストは大抵同じソースコードに書くけど、
kotlin(junit)は統合テストも単体テストもディレクトリが別れてるんだね。
あ、こら、rust が特殊とか言わない!
tip
この記事は決して日記さんがあふぉなことを証明するものではありません! ...多分
できることを知っておく
> gradle task
> Calculating task graph as no cached configuration is available for tasks: task
> Task :tasks
---
## Tasks runnable from root project 'tmp.q5kXPDaYCv'
## Application tasks
run - Runs this project as a JVM application
## Build tasks
assemble - Assembles the outputs of this project.
build - Assembles and tests this project.
buildDependents - Assembles and tests this project and all projects that depend on it.
buildKotlinToolingMetadata - Build metadata json file containing information about the used Kotlin tooling
buildNeeded - Assembles and tests this project and all projects it depends on.
classes - Assembles main classes.
clean - Deletes the build directory.
jar - Assembles a jar archive containing the classes of the 'main' feature.
kotlinSourcesJar - Assembles a jar archive containing the sources of target 'kotlin'.
testClasses - Assembles test classes.
## Build Setup tasks
init - Initializes a new Gradle build.
updateDaemonJvm - Generates or updates the Gradle Daemon JVM criteria.
wrapper - Generates Gradle wrapper files.
## Distribution tasks
assembleDist - Assembles the main distributions
distTar - Bundles the project as a distribution.
distZip - Bundles the project as a distribution.
installDist - Installs the project as a distribution as-is.
## Documentation tasks
javadoc - Generates Javadoc API documentation for the 'main' feature.
## Help tasks
artifactTransforms - Displays the Artifact Transforms that can be executed in root project 'tmp.q5kXPDaYCv'.
buildEnvironment - Displays all buildscript dependencies declared in root project 'tmp.q5kXPDaYCv'.
dependencies - Displays all dependencies declared in root project 'tmp.q5kXPDaYCv'.
dependencyInsight - Displays the insight into a specific dependency in root project 'tmp.q5kXPDaYCv'.
help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
kotlinDslAccessorsReport - Prints the Kotlin code for accessing the currently available project extensions and conventions.
outgoingVariants - Displays the outgoing variants of root project 'tmp.q5kXPDaYCv'.
projects - Displays the sub-projects of root project 'tmp.q5kXPDaYCv'.
properties - Displays the properties of root project 'tmp.q5kXPDaYCv'.
resolvableConfigurations - Displays the configurations that can be resolved in root project 'tmp.q5kXPDaYCv'.
tasks - Displays the tasks runnable from root project 'tmp.q5kXPDaYCv' (some of the displayed tasks may belong to subprojects).
## Verification tasks
check - Runs all checks.
checkKotlinGradlePluginConfigurationErrors - Checks that Kotlin Gradle Plugin hasn't reported project configuration errors, failing otherwise. This task always runs before compileKotlin\* or similar tasks.
test - Runs the test suite.
To see all tasks and more detail, run gradle tasks --all
To see more detail about a task, run gradle help --task <task>
BUILD SUCCESSFUL in 6s
1 actionable task: 1 executed
Configuration cache entry stored.
gradle tasks はタスクというのを表示する。 tasks って自分で追加することもできるらしい。
気になった task 探索 1: javaToolchains
>gradle javaToolchains
Calculating task graph as no cached configuration is available for tasks: javaToolchains
> Task :javaToolchains
+ Options
| Auto-detection: Enabled
| Auto-download: Enabled
+ Azul Zulu JDK 1.8.0_432-b06
| Location: /Library/Java/JavaVirtualMachines/zulu-8.jdk/Contents/Home
| Language Version: 8
| Vendor: Azul Zulu
| Architecture: aarch64
| Is JDK: true
| Detected by: MacOS java_home
+ Azul Zulu JDK 17.0.13+11-LTS
| Location: /Library/Java/JavaVirtualMachines/zulu-17.jdk/Contents/Home
| Language Version: 17
| Vendor: Azul Zulu
| Architecture: aarch64
| Is JDK: true
| Detected by: Current JVM
+ Azul Zulu JDK 21.0.5+11-LTS
| Location: /Library/Java/JavaVirtualMachines/zulu-21.jdk/Contents/Home
| Language Version: 21
| Vendor: Azul Zulu
| Architecture: aarch64
| Is JDK: true
| Detected by: MacOS java_home
+ Azul Zulu JDK 23.0.1+11
| Location: /Library/Java/JavaVirtualMachines/zulu-23.jdk/Contents/Home
| Language Version: 23
| Vendor: Azul Zulu
| Architecture: aarch64
| Is JDK: true
| Detected by: MacOS java_home
+ Microsoft JDK 21.0.7+6-LTS
| Location: /Library/Java/JavaVirtualMachines/microsoft-21.jdk/Contents/Home
| Language Version: 21
| Vendor: Microsoft
| Architecture: aarch64
| Is JDK: true
| Detected by: MacOS java_home
BUILD SUCCESSFUL in 814ms
1 actionable task: 1 executed
Configuration cache entry stored.
ほへぇシステムにある Java 自動で検知してきてくれるんだ。 java_home で探したとも書かれてるね。
気になった task 探索 2: projects
>gradle projects
<Calculating task graph as no cached configuration is available for tasks: projects
> Task :projects
Projects:
------------------------------------------------------------
Root project 'tmp.vVJk4Hd6GU'
------------------------------------------------------------
Root project 'tmp.vVJk4Hd6GU'
\--- Project ':lib'
To see a list of the tasks of a project, run gradle <project-path>:tasks
For example, try running gradle :lib:tasks
BUILD SUCCESSFUL in 374ms
1 actionable task: 1 executed
Configuration cache entry stored.
プロジェクトが設定できるらしい。 試しに lib を lib2 として複製してみる。 これだけだと認識しない。
>cat settings.gradle.kts
/*
* This file was generated by the Gradle 'init' task.
*
* The settings file is used to specify which projects to include in your build.
* For more detailed information on multi-project builds, please refer to https://docs.gradle.org/8.14.2/userguide/multi_project_builds.html in the Gradle documentation.
*/
plugins {
// Apply the foojay-resolver plugin to allow automatic download of JDKs
id("org.gradle.toolchains.foojay-resolver-convention") version "0.10.0"
}
rootProject.name = "tmp.vVJk4Hd6GU"
include("lib")
+ include("lib2")
settings.gradle.ktsにそれっぽいこと(include)が書かれてるので追記。
結果、認識した
>gradle projects
Calculating task graph as configuration cache cannot be reused because file 'settings.gradle.kts' has changed.
> Task :projects
Projects:
------------------------------------------------------------
Root project 'tmp.vVJk4Hd6GU'
------------------------------------------------------------
Root project 'tmp.vVJk4Hd6GU'
+--- Project ':lib'
\--- Project ':lib2'
To see a list of the tasks of a project, run gradle <project-path>:tasks
For example, try running gradle :lib:tasks
BUILD SUCCESSFUL in 639ms
1 actionable task: 1 executed
Configuration cache entry stored.
なお、プロジェクトごとに task は異なる。
ここに書いてあるように、gradle <project-path>:tasksで各プロジェクトの tasks 一覧を取得できる。
gradle tasks --allを実行すると、すべての task を表示できる。
>gradle tasks --all
Calculating task graph as no cached configuration is available for tasks: tasks --all
> Task :tasks
------------------------------------------------------------
Tasks runnable from root project 'tmp.vVJk4Hd6GU'
------------------------------------------------------------
Build tasks
-----------
lib:assemble - Assembles the outputs of this project.
lib2:assemble - Assembles the outputs of this project.
lib:build - Assembles and tests this project.
lib2:build - Assembles and tests this project.
lib:buildDependents - Assembles and tests this project and all projects that depend on it.
lib2:buildDependents - Assembles and tests this project and all projects that depend on it.
lib:buildKotlinToolingMetadata - Build metadata json file containing information about the used Kotlin tooling
lib2:buildKotlinToolingMetadata - Build metadata json file containing information about the used Kotlin tooling
lib:buildNeeded - Assembles and tests this project and all projects it depends on.
lib2:buildNeeded - Assembles and tests this project and all projects it depends on.
lib:classes - Assembles main classes.
lib2:classes - Assembles main classes.
lib:clean - Deletes the build directory.
lib2:clean - Deletes the build directory.
lib:jar - Assembles a jar archive containing the classes of the 'main' feature.
lib2:jar - Assembles a jar archive containing the classes of the 'main' feature.
lib:kotlinSourcesJar - Assembles a jar archive containing the sources of target 'kotlin'.
lib2:kotlinSourcesJar - Assembles a jar archive containing the sources of target 'kotlin'.
lib:testClasses - Assembles test classes.
lib2:testClasses - Assembles test classes.
Build Setup tasks
-----------------
init - Initializes a new Gradle build.
updateDaemonJvm - Generates or updates the Gradle Daemon JVM criteria.
wrapper - Generates Gradle wrapper files.
Documentation tasks
-------------------
lib:javadoc - Generates Javadoc API documentation for the 'main' feature.
lib2:javadoc - Generates Javadoc API documentation for the 'main' feature.
Help tasks
----------
artifactTransforms - Displays the Artifact Transforms that can be executed in root project 'tmp.vVJk4Hd6GU'.
lib:artifactTransforms - Displays the Artifact Transforms that can be executed in project ':lib'.
lib2:artifactTransforms - Displays the Artifact Transforms that can be executed in project ':lib2'.
buildEnvironment - Displays all buildscript dependencies declared in root project 'tmp.vVJk4Hd6GU'.
lib:buildEnvironment - Displays all buildscript dependencies declared in project ':lib'.
lib2:buildEnvironment - Displays all buildscript dependencies declared in project ':lib2'.
dependencies - Displays all dependencies declared in root project 'tmp.vVJk4Hd6GU'.
lib:dependencies - Displays all dependencies declared in project ':lib'.
lib2:dependencies - Displays all dependencies declared in project ':lib2'.
dependencyInsight - Displays the insight into a specific dependency in root project 'tmp.vVJk4Hd6GU'.
lib:dependencyInsight - Displays the insight into a specific dependency in project ':lib'.
lib2:dependencyInsight - Displays the insight into a specific dependency in project ':lib2'.
help - Displays a help message.
lib:help - Displays a help message.
lib2:help - Displays a help message.
javaToolchains - Displays the detected java toolchains.
lib:javaToolchains - Displays the detected java toolchains.
lib2:javaToolchains - Displays the detected java toolchains.
lib:kotlinDslAccessorsReport - Prints the Kotlin code for accessing the currently available project extensions and conventions.
lib2:kotlinDslAccessorsReport - Prints the Kotlin code for accessing the currently available project extensions and conventions.
outgoingVariants - Displays the outgoing variants of root project 'tmp.vVJk4Hd6GU'.
lib:outgoingVariants - Displays the outgoing variants of project ':lib'.
lib2:outgoingVariants - Displays the outgoing variants of project ':lib2'.
projects - Displays the sub-projects of root project 'tmp.vVJk4Hd6GU'.
lib:projects - Displays the sub-projects of project ':lib'.
lib2:projects - Displays the sub-projects of project ':lib2'.
properties - Displays the properties of root project 'tmp.vVJk4Hd6GU'.
lib:properties - Displays the properties of project ':lib'.
lib2:properties - Displays the properties of project ':lib2'.
resolvableConfigurations - Displays the configurations that can be resolved in root project 'tmp.vVJk4Hd6GU'.
lib:resolvableConfigurations - Displays the configurations that can be resolved in project ':lib'.
lib2:resolvableConfigurations - Displays the configurations that can be resolved in project ':lib2'.
tasks - Displays the tasks runnable from root project 'tmp.vVJk4Hd6GU' (some of the displayed tasks may belong to subprojects).
lib:tasks - Displays the tasks runnable from project ':lib'.
lib2:tasks - Displays the tasks runnable from project ':lib2'.
Verification tasks
------------------
lib:check - Runs all checks.
lib2:check - Runs all checks.
lib:checkKotlinGradlePluginConfigurationErrors - Checks that Kotlin Gradle Plugin hasn't reported project configuration errors, failing otherwise. This task always runs before compileKotlin* or similar tasks.
lib2:checkKotlinGradlePluginConfigurationErrors - Checks that Kotlin Gradle Plugin hasn't reported project configuration errors, failing otherwise. This task always runs before compileKotlin* or similar tasks.
lib:test - Runs the test suite.
lib2:test - Runs the test suite.
Other tasks
-----------
lib:compileJava - Compiles main Java source.
lib2:compileJava - Compiles main Java source.
lib:compileKotlin - Compiles the compilation 'main' in target ''.
lib2:compileKotlin - Compiles the compilation 'main' in target ''.
lib:compileTestJava - Compiles test Java source.
lib2:compileTestJava - Compiles test Java source.
lib:compileTestKotlin - Compiles the compilation 'test' in target ''.
lib2:compileTestKotlin - Compiles the compilation 'test' in target ''.
components - Displays the components produced by root project 'tmp.vVJk4Hd6GU'. [deprecated]
lib:components - Displays the components produced by project ':lib'. [deprecated]
lib2:components - Displays the components produced by project ':lib2'. [deprecated]
dependentComponents - Displays the dependent components of components in root project 'tmp.vVJk4Hd6GU'. [deprecated]
lib:dependentComponents - Displays the dependent components of components in project ':lib'. [deprecated]
lib2:dependentComponents - Displays the dependent components of components in project ':lib2'. [deprecated]
+ lib2:hello
lib:mainClasses
lib2:mainClasses
model - Displays the configuration model of root project 'tmp.vVJk4Hd6GU'. [deprecated]
lib:model - Displays the configuration model of project ':lib'. [deprecated]
lib2:model - Displays the configuration model of project ':lib2'. [deprecated]
prepareKotlinBuildScriptModel
lib:processResources - Processes main resources.
lib2:processResources - Processes main resources.
lib:processTestResources - Processes test resources.
lib2:processTestResources - Processes test resources.
BUILD SUCCESSFUL in 467ms
1 actionable task: 1 executed
Configuration cache entry stored.
(せっかくなので lib2 に独自のタスクを設定してみた。)
task を独自で定義する
tasks.register("hello") {
doLast {
println("Hello world!")
}
}
公式サイト を元に定義、というかほぼコピー
register のコールバックとして、doLast を定義してると考えるのがいいのかね?
マインクラフトと gradle
マインクラフトの mod 開発は、大抵 gralde となる。
作るもの、使う前提 mod などによってセットアップが大きく異なる。
paper の場合
gralde をライブラリで初期化し、次のページに書かれている内容を build.gradle.kts に追加する。 Project setup | PaperMC Docs
ちなみに、kotlin で開発できる(と思う)
kotlin にして問題があったら随時ページを更新します。
一例
>gradle init
Select type of build to generate:
1: Application
2: Library
3: Gradle plugin
4: Basic (build structure only)
Enter selection (default: Application) [1..4] 2
Select implementation language:
1: Java
2: Kotlin
3: Groovy
4: Scala
5: C++
6: Swift
Enter selection (default: Java) [1..6] 2
Enter target Java version (min: 7, default: 21): 21
Project name (default: tmp.1mPA8JuPth):
Select build script DSL:
1: Kotlin
2: Groovy
Enter selection (default: Kotlin) [1..2] 1
Select test framework:
1: kotlin.test
2: JUnit Jupiter
Enter selection (default: kotlin.test) [1..2] 1
Generate build using new APIs and behavior (some features may change in the next minor release)? (default: no) [yes, no]
> Task :init
Learn more about Gradle by exploring our Samples at https://docs.gradle.org/8.14.2/samples/sample_building_kotlin_libraries.html
BUILD SUCCESSFUL in 11s
1 actionable task: 1 executed
cat build.gradle.kts
/*
* This file was generated by the Gradle 'init' task.
*
* This generated file contains a sample Kotlin library project to get you started.
* For more details on building Java & JVM projects, please refer to https://docs.gradle.org/8.14.2/userguide/building_java_projects.html in the Gradle documentation.
*/
plugins {
// Apply the org.jetbrains.kotlin.jvm Plugin to add support for Kotlin.
alias(libs.plugins.kotlin.jvm)
// Apply the java-library plugin for API and implementation separation.
`java-library`
}
repositories {
// Use Maven Central for resolving dependencies.
mavenCentral()
// Paper用に追加
maven {
name = "papermc"
url = uri("https://repo.papermc.io/repository/maven-public/")
}
}
dependencies {
// Use the Kotlin JUnit 5 integration.
testImplementation("org.jetbrains.kotlin:kotlin-test-junit5")
// Use the JUnit 5 integration.
testImplementation(libs.junit.jupiter.engine)
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
// This dependency is exported to consumers, that is to say found on their compile classpath.
api(libs.commons.math3)
// This dependency is used internally, and not exposed to consumers on their own compile classpath.
implementation(libs.guava)
// Paper用に追加
compileOnly("io.papermc.paper:paper-api:1.21.8-R0.1-SNAPSHOT")
}
// Apply a specific Java toolchain to ease working on different environments.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named<Test>("test") {
// Use JUnit Platform for unit tests.
useJUnitPlatform()
}
repositories {
}
dependencies {
compileOnly("io.papermc.paper:paper-api:1.21.8-R0.1-SNAPSHOT")
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(21))
}
ここまでおわったらgradle checkを実行しておく
必要そうな gradle プラグインを追加する
shadowというのが必要です。 fat-jar を生成します。
依存関係を含め必要なファイルをすべてjarファイルに保存します。5
導入は簡単ですが、最新版を入れたら動作しなかったので、その辺は調整してください。
/*
* This file was generated by the Gradle 'init' task.
*
* This generated file contains a sample Kotlin library project to get you started.
* For more details on building Java & JVM projects, please refer to https://docs.gradle.org/8.14.2/userguide/building_java_projects.html in the Gradle documentation.
*/
plugins {
// Apply the org.jetbrains.kotlin.jvm Plugin to add support for Kotlin.
alias(libs.plugins.kotlin.jvm)
// Apply the java-library plugin for API and implementation separation.
`java-library`
// shadow jarを導入
id("com.gradleup.shadow") version "8.3.8"
}
最新版を入れた時に発生したエラー
9.0.0-rc2 で発生したエラー
(検証日: 2025/07/28)
Caused by: java.lang.RuntimeException: Failed to remap plugin jar '/<個人情報を含むため省略>/tmp.1mPA8JuPth/lib/build/libs/lib-all.jar'
便利そうな gradle プラグインを追加する
run-taskというのが便利そうなので追加する。
/*
* This file was generated by the Gradle 'init' task.
*
* This generated file contains a sample Kotlin library project to get you started.
* For more details on building Java & JVM projects, please refer to https://docs.gradle.org/8.14.2/userguide/building_java_projects.html in the Gradle documentation.
*/
plugins {
// Apply the org.jetbrains.kotlin.jvm Plugin to add support for Kotlin.
alias(libs.plugins.kotlin.jvm)
// Apply the java-library plugin for API and implementation separation.
`java-library`
// Apply the plugin (run-task用に追加)
id("xyz.jpenilla.run-paper") version "2.3.1"
}
repositories {
// Use Maven Central for resolving dependencies.
mavenCentral()
// Paper用に追加
maven {
name = "papermc"
url = uri("https://repo.papermc.io/repository/maven-public/")
}
}
dependencies {
// Use the Kotlin JUnit 5 integration.
testImplementation("org.jetbrains.kotlin:kotlin-test-junit5")
// Use the JUnit 5 integration.
testImplementation(libs.junit.jupiter.engine)
testRuntimeOnly("org.junit.platform:junit-platform-launcher")
// This dependency is exported to consumers, that is to say found on their compile classpath.
api(libs.commons.math3)
// This dependency is used internally, and not exposed to consumers on their own compile classpath.
implementation(libs.guava)
// Paper用に追加
compileOnly("io.papermc.paper:paper-api:1.21.8-R0.1-SNAPSHOT")
}
// Apply a specific Java toolchain to ease working on different environments.
java {
toolchain {
languageVersion = JavaLanguageVersion.of(21)
}
}
tasks.named<Test>("test") {
// Use JUnit Platform for unit tests.
useJUnitPlatform()
}
repositories {
}
dependencies {
compileOnly("io.papermc.paper:paper-api:1.21.8-R0.1-SNAPSHOT")
}
java {
toolchain.languageVersion.set(JavaLanguageVersion.of(21))
}
// run-task用に追加
// 公式と書き方が異なるので注意
tasks.runServer {
minecraftVersion("1.21.8") // バージョン指定
}
kotlin でコードを書いてみる
paper のサイトに公開されてるページを kotlin ベースに書き直すとこうなる
package org.adw39.examplePlugin
import net.kyori.adventure.text.Component
import org.bukkit.Bukkit
import org.bukkit.event.Listener
import org.bukkit.event.player.PlayerJoinEvent
import org.bukkit.plugin.java.JavaPlugin
class ExamplePlugin: JavaPlugin(), Listener {
override fun onEnable() {
Bukkit.getPluginManager().registerEvents(this, this)
}
@EventHandler
fun onPlayerJoin(event: PlayerJoinEvent) {
event.player.sendMessage("hello!")
}
}
- 関数の定義は rust などに似てる
funを先頭につける。 void 以外の戻り値は、()の後ろに(): <Type>です。 @Overrideはoverrideを先頭につける
しょっちゅう使われるから言語標準で用意されたのかな- java の
getHogehoge、setHogehogeメソッドは、get/set を省略する
いわゆるゲッターセッターってやつです。 kotlin の場合は基本的に省略可能です。
plugin.ymlを忘れない
拡張子yamlは NG6
name: ExamplePlugin
version: 1.0.0
main: org.adw39.examplePlugin.ExamplePlugin
description: An example plugin
author: nikki9750
website: https://adw39.org
api-version: "1.21.8"
runServer を実行する
サーバーが起動したら成功
サーバーの軌道に失敗したら、まず/lib/runに生成されるサーバーディレクトリの、elua.txtを確認すること
参考
基礎編 part2+
前回 sdkman が使いやすいというお話を致しました。
そして、コマンドラインの gradle で、プロジェクトを作成したのでした。
投稿日とバージョンについて
後述しますが、gradle はバージョンによっての変化が激しいため、先に日程と gradle の最新版の確認をお願いします。
なお、日記さん側でも変化があったら修正するよう心掛けるつもりではありますが、放置する可能性もあるのでよろしくお願いします。
- 投稿日: 2025/07/28
- Gradle の Version:
Gradle 8.14.2 - IntelliJ Idea の Version:
IntelliJ IDEA 2025.1.4.1 (Ultimate Edition) - そもそも使ってる OS:
MacOS 15.5(24F74)
🎵 本日の一曲
まほうつかってりめせかをかがみごしにえいえんにみてたい
intelliJ Idea はいいぞ
OSS 版もある IntelliJ Idea。
本来は有償エディタなのですが、機能制限付き(というより、Jetbrains 製のプラグインが使えない?)オープンソース版 IntelliJ Idea は無料で使えます。
また、学生なら有償版も無料で使えます。
JetBrains Student Pack
IntelliJ Idea を入れてみよう。
ダウンロードページ 普通に入れてください。 普通に。
(本題)マインクラフトプラグインを入れる
IntelliJ Idea のプラグインとして存在してます。
前回やった gradle などの設定を大体すべて自動でやってくれる優れものです。
起動時のプロジェクト選択画面、もしくはエディタ右上の歯車アイコンにある「プラグイン」というボタンから、導入できます。
プロジェクトを作ってみる
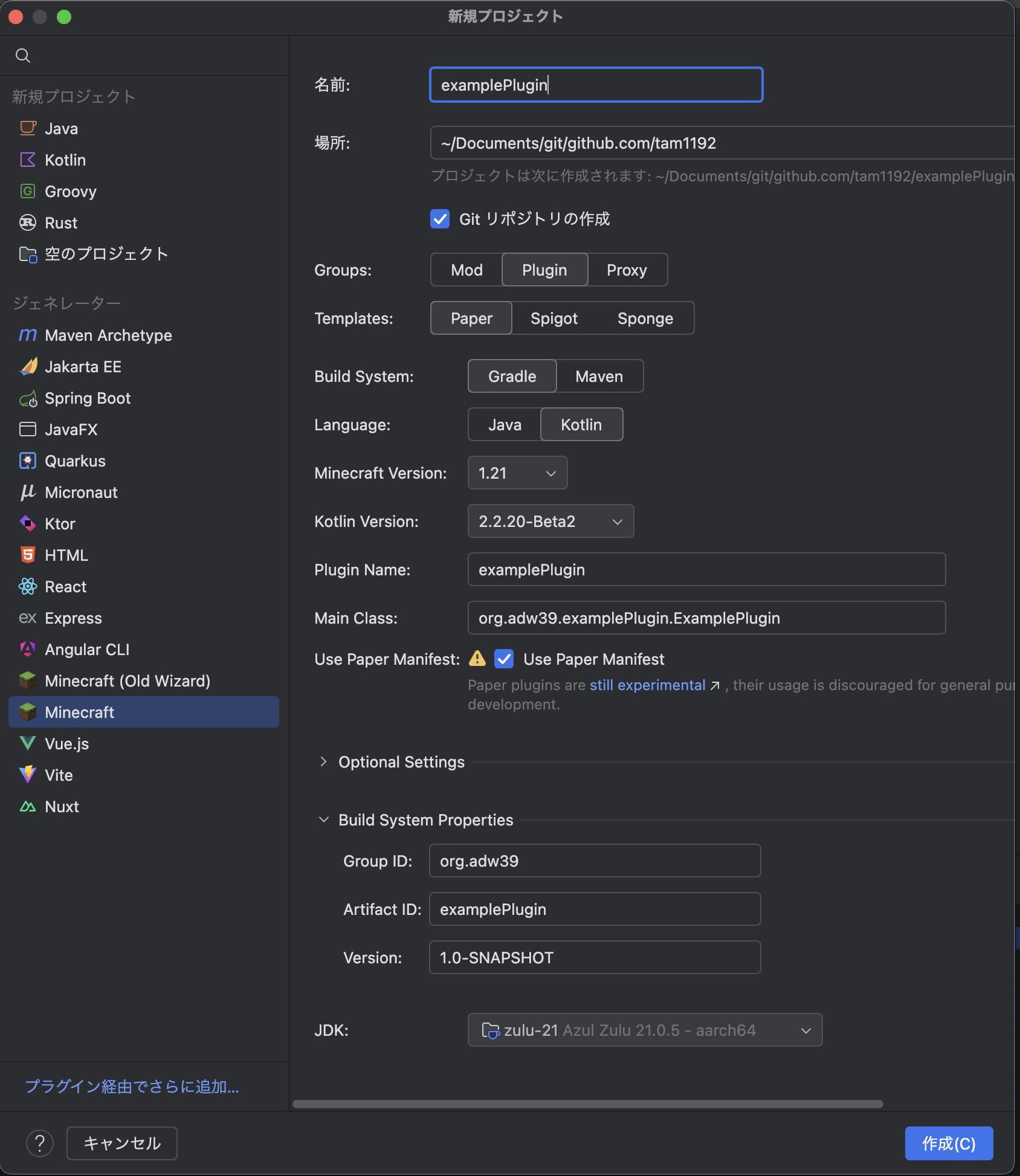
こんな感じで設定できます。 楽です。正直。
paper 編
PaperMCプラグインを作る時の備忘録です。
paper 編 part1 コマンド補完
基本中の基本でありながら早速引っ掛けがあったのでメモ
🎵 本日の一曲
pv がしぬほどかわいい。
CommandExecutor vs TabExecutor
---
config:
class:
hideEmptyMembersBox: true
---
classDiagram
direction TB
class CommandExecutor {
onCommand()
}
class TabExecutor {
onTabComplete()
}
<<Interface>> CommandExecutor
<<Interface>> TabExecutor
TabExecutor --|> CommandExecutor
import org.bukkit.command.Command
import org.bukkit.command.CommandSender
import org.bukkit.command.TabExecutor
class ExampleCommand : TabExecutor {
override fun onTabComplete(
p0: CommandSender,
p1: Command,
p2: String,
p3: Array<out String>?
): List<String?>? {
TODO("Not yet implemented")
}
override fun onCommand(
p0: CommandSender,
p1: Command,
p2: String,
p3: Array<out String>?
): Boolean {
TODO("Not yet implemented")
}
}
TabExecutor を実装すれば、CommandExecutor と TabExecutor 両方を実装することになります。
TabExecutor には、onTabComplete というメソッドがあります。 これはコマンド補完機能を提供するものです。
基本的にはTabExecutorを使おう!
Tab 補完あれこれ
onCommand メソッドに関する情報はたくさんあると思うので、ここでは onTabComplete のメモです
基本的な使い方はこんな感じ
override fun onTabComplete(
sender: CommandSender,
command: Command,
label: String,
args: Array<out String>
): MutableList<String>? {
return when {
args[0] == "add" -> Material.entries.filter { it.isBlock }.map { it.name.lowercase() }.toMutableList()
args.isEmpty() -> "add,del,list".split(",").toMutableList()
else -> null
}
}
kotlin の場合は MutableList で返すことになります。 とりあえず java では ArrayList、rust では mut Vec ですね。
whenが式なのを生かして、when の結果をそのまま return に流してます。
kotlin を使うメリット 1 ですね。
note
rust の使い勝手に近いならそれはメリットですよね!(圧)
onTabComplete が呼ばれるタイミング
実際に調べてみます。
package org.adw39.examplePlugin2
import org.adw39.examplePlugin2.commands.ExampleCommand
import org.bukkit.plugin.java.JavaPlugin
class ExamplePlugin2 : JavaPlugin() {
override fun onEnable() {
getCommand("example")?.setExecutor(ExampleCommand())
}
override fun onDisable() {
// Plugin shutdown logic
}
}
package org.adw39.examplePlugin2.commands
import org.bukkit.command.Command
import org.bukkit.command.CommandSender
import org.bukkit.command.TabExecutor
class ExampleCommand : TabExecutor {
override fun onTabComplete(
p0: CommandSender,
p1: Command,
p2: String,
p3: Array<out String>?
): List<String?>? {
p3?.forEach {
println(it)
}
return null
}
override fun onCommand(
p0: CommandSender,
p1: Command,
p2: String,
p3: Array<out String>?
): Boolean {
return true
}
}
tip
array は配列なので、forEach で中身を分解して出力します。
tip
内部に Logger オブジェクトが存在しますが、println も使用できます。(多分非推奨)
resources/plugin.yml
name: MyPaperPlugin
version: 0.0.1
main: org.adw39.examplePlugin2.ExamplePlugin2
description: An example plugin
author: nikki
website: https://adw39.org
api-version: "1.21.0"
commands:
example:
description: テスト
usage: "/example <arg>"
permission: org.adw39.examplePlugin2.example
note
ファイルの位置は、package 文をみていただくのが早いかと思います。
複雑になり始めたら tree を載せます。
warning
plugin.yaml の編集を忘れずに!!
実行結果
/コマンド名 コマンド引数1 コマンド引数2... と入力しますが、
実装した Executor を**getCommandで登録した時に用いた名前がコマンド名となります。**
コマンド名が入力され、引数を入力する際に TabExecutor が呼び出されます。
引数の入力が変更される度にonTabCompleteが呼び出されます。 Tab が入力された時に呼び出されるわけではない模様
ブロック名で補完させる
worldeditのようなプラグインを作りたくなった場合、ブロック名の補完は必須です。
最も単純な方補は、Material列挙型を使うことです。
note
minecraft:oak_logのような表記を名前空間付き idなどと呼ばれるそうです。
今回は名前空間を省略いたします。
また、ハーフブロックなどはブロックステータスを持つのですが、
こちらも省略します。
Material 列挙隊をみてみよう
- ACACIA_BOAT
- ACACIA_BUTTON
- ACACIA_CHEST_BOAT ...
- LEGACY_RECORD_12 Link icon
と、ブロック id が並んでいます。
また、メソッドにはisAir、isBlockなど、便利そうなものが実装されています。
実際に実装してみる
kotlin では、enum につくentriesが活用できそうです。
これは、一応 getter らしく、()は不要とのこと。 中身はイテレーターになってますです!
isBlockで block に限定し、文字列に直して mutableList で返却すれば良さそうです。
package org.adw39.examplePlugin2.commands
import org.bukkit.Material
import org.bukkit.command.Command
import org.bukkit.command.CommandSender
import org.bukkit.command.TabExecutor
class ExampleCommand : TabExecutor {
override fun onTabComplete(
p0: CommandSender,
p1: Command,
p2: String,
p3: Array<out String>?
): List<String?>? {
println(p3?.getOrNull(0) ?: "")
return if (p3?.size == 1) {
Material.entries.filter { it.isBlock }.map {it.name.lowercase() }.toMutableList()
} else {
mutableListOf("")
}
}
override fun onCommand(
p0: CommandSender,
p1: Command,
p2: String,
p3: Array<out String>?
): Boolean {
val block = p3?.getOrNull(0) ?: return false
p0.sendMessage(block)
return true
}
}
entries はイテレーターですので、filter や map メソッドが活用できます。
it.isBlockはもはや英語として通じてしまいそうで面白いです。
lowercase()にしてるのは、標準実装されているコマンドsetなどが、lowercase で入力するからです。
(あと入力が楽)
実行例
まとめ
コマンド補完は便利だから実装しよう。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
fabric 編
Intelli J の Minecraft プラグインで簡単にプロジェクトを生やすことができます。すばらしい!
fabric 編 part1 仕様が大きく変わっちまったぜ
生まれて 23 年、まさかのブロックすら作ったことないってマ? 作ろうとしたらトラブったので。
🎥 今日の RT
どるるるるる
我サーバーにて
我、個人サーバーやってるナリ
気づいたら使わないブロックだと行って無理やりスポンジが畳に変貌してたナリ
テクスチャもらってきたので、fabric でブロックにしてしまうナリ
warning
※なお、当サイトにあるテクスチャ画像の無断使用は NG でお願いします。
一応。
fabric の wiki を参考にアイテムを追加してみる。
package org.adw39.myfabricmods
import net.fabricmc.api.ModInitializer
import net.minecraft.item.Item
import net.minecraft.registry.Registries
import net.minecraft.registry.Registry
import net.minecraft.util.Identifier
class Myfabricmods : ModInitializer {
companion object {
lateinit var CUSTOM_ITEM: Item
}
override fun onInitialize() {
CUSTOM_ITEM = Item(Item.Settings())
Registry.register(Registries.ITEM, Identifier.of("myfabricmods", "custom"), CUSTOM_ITEM)
}
}
tip
Identifier の属性が Private とエラー!
copilot 曰く1.21 以降はIdentifier.of()でやるんだってさ。 ~~しるかそんなもん~
tip
kotlin では**java と初期化のタイミングが異なり、**lateinit を使う方が賢い場合があります。
なんて TIP を書くのに 30 分。 これくらいならすぐ起動するやろとやってみらー
Caused by: java.lang.NullPointerException: Item id not set
あまりにも有名で、かつシンプルなエラーが帰ってきた。 原因がわからん。
kotlin のせいか?
ドキュメントがあった
Creating Your First Item - fabric documentation
ドキュメントを見つけたらまるでコードが違くてびっくり。バージョン違いでこんくらい変わるの?
急いで kotlin で書き直す。
package org.adw39.myfabricmods
import net.fabricmc.api.ModInitializer
import net.minecraft.item.Item
import net.minecraft.registry.Registries
import net.minecraft.registry.Registry
import net.minecraft.registry.RegistryKey
import net.minecraft.registry.RegistryKeys
import net.minecraft.util.Identifier
class Myfabricmods : ModInitializer {
companion object {
lateinit var item: Item
}
override fun onInitialize() {
val itemKey = RegistryKey.of<Item>(RegistryKeys.ITEM, Identifier.of("myfabricmods", "myfabricmods"))
var settings = Item.Settings()
settings.registryKey(itemKey)
item = Item(settings)
Registry.register(Registries.ITEM, itemKey, item);
}
}
とりあえず 1 つのファイルに無理やり納めてみるとこうなった。
note
まとめると、Item の settings に registryKey が必要になった? ということらしい。
note
ここまでやってできることは、コマンドでアイテムを呼び出すこと
クリエイティブインベントリに追加する
今回は適当に「Redstone」タブに追加することに
ItemGroupEvents.modifyEntriesEvent(ItemGroups.REDSTONE).register {
it.add { item }
}
一瞬で追加できました。
note
ItemGroups みたいに、複数形のやつは enum(列挙型)なのかな?
note
ここまでやってできることは、クリエイティブインベントリでアイテムを呼び出すこと
次回
テクスチャをつけたい。
fabric 編 part2 とりまブロックを追加してみる
冷静にリファレンスを読めば良かったものを...
note
作業環境
- 日付: 2025/08/16
- 言語: kotlin
- バージョン: 1.21.3
minecraft_version=1.21.3
yarn_mappings=1.21.3+build.2
loader_version=0.17.2
kotlin_loader_version=1.13.4+kotlin.2.2.0
# Mod Properties
mod_version=1.0-SNAPSHOT
maven_group=org.adw39
archives_base_name=MyFabricMods
# Dependencies
# check this on https://modmuss50.me/fabric.html
fabric_version=0.114.1+1.21.3
今日のひとこと
一回聞いてすぐ好きになったので共有したくなった。
続きをみる
もうしゅお好き。
MYAAMAI!! な花梨ちゃんすこ
今日のふたこと
ちょっとお試しで、劇場風な感じに説明してみたいと思います。(決して罰ゲームではない)
E さんと I さんによる掛け合い的な説明にします。
マジでしょうもない設定
ちなみにネームスペースで言うところのこんな感じ
mod world {
struct Human();
let nikki = Human::new();
mod nikki_world {
struct People();
let E_san = People::new();
let I_san = People::new();
}
}セキュリティ的に(?)外部参照できない感じなので、E さんも I さんも日記と言う存在を認知できないです。
あと、前回クラス名やパッケージ名が不思議だったため、手作業修正しました。
| 変更前 | 変更後 | 補足 |
|---|---|---|
org.adw39.myfabricmods | org.adw39.my_fabric_mods | -区切りの方が正しいらしい... |
Myfabricmods | MyFabricMods |
ブロック追加してみる
E: プログラム書く E ちゃんやで。
I: 隣で見守る I です。
E: 前回のおさらいでアイテムの追加と、クリエイティブモードのインベントリに追加するところまでやったで
I: 今回は、実際に置けるブロックを作るところまでやるの?
E: せやで。 リファレンスそのままコピペでなんとかなるからすぐ終わるはずや!
I: ほんとかな 心配だな
kotlin を最大限有効活用する
E: あそうだ、その前にやりたいことがあるねん
I: なに?
E: ModInitializer を実装してる MyFabricMods をクラスから kotlin オブジェクトに変更するで
I: 何が変わるの?
E: 正直そこまで変わらないで1
I: そうなの? 調べてみたら、シングルトンを簡単に作れるって書いてあったけど
E: さすが A ちゃんやな!
I: I です。
E: さすが I ちゃんやな! すぐ調べるのは大切や!
I: 一つのインスタンスを使い回すようだね。
E: どれだけ新しくインスタンスを立てても、結局は全て同じインスタンスになるんやで。 インスタンスがごちゃ混ぜにならないから、システムの核心的なところでよくみるで
I: お姉ちゃんは mod の中心部を一つにインスタンスにしたいわけだ
E: せやな。 しかし、Fabric の場合はただの初期化関数に近い気がするから、あまり意味ないかなって思うで1
(変更前)
class MyFabricMods: ModInitializer {
const val MOD_ID = "my_fabric_mods"
val logger: Logger = LoggerFactory.getLogger(MOD_ID)
override fun onInitialize() {
MyBlocks.initialize()
logger.info("Initialized {}", MOD_ID)
}
}
(変更後)
object MyFabricMods: ModInitializer {
const val MOD_ID = "my_fabric_mods"
val logger: Logger = LoggerFactory.getLogger(MOD_ID)
override fun onInitialize() {
MyBlocks.initialize()
logger.info("Initialized {}", MOD_ID)
}
}
I: ほんとだ。 object に変えるだけでいいんだ。
E: これくらいの変更だったら余裕やで。でもちょっと心配だから起動してみよか。
I: 早くブロック追加しよ。
Caused by: net.fabricmc.loader.api.EntrypointException: Exception while loading entries for entrypoint 'main' provided by 'my_fabric_mods'
Caused by: net.fabricmc.loader.api.LanguageAdapterException: java.lang.IllegalAccessException: class net.fabricmc.loader.impl.util.DefaultLanguageAdapter cannot access a member of class org.adw39.my_fabric_mods.MyFabricMods with modifiers "private"
E: うせやろ
I: えー。
E: Private...なんでやろうな?
数分後
I: あの、早くブロック追加しないの?
E: でも気になるから仕方ないんやで
I: そういえば、マインクラフトってjavaで動いてなかったっけ? Kotlin だと都合悪いんじゃない?
E: kotlin と java は互換性あるんやで。だから不思議ちゃんやで
I: ほんとに? fabric-language-kotlinと言うのを内部で使ってるって書かれてるけど
E: プロジェクト作る時に kotlin って選べたから、そのままなんやで
I: fabric.mod.jsonを変更しろって書かれてる気がする、ちょっとみてみよ
...
"entrypoints": {
"fabric-datagen": [
"org.adw39.my_fabric_mods.client.MyFabricModsDataGenerator"
],
"client": [
"org.adw39.my_fabric_mods.client.MyFabricModsClient"
],
"main": [
"org.adw39.my_fabric_mods.MyFabricMods"
]
}
...
I: ほらっ、main のところ。 こうしてって書かれてる気がする
"main": [
{
"adapter": "kotlin",
"value": "org.adw39.my_fabric_mods.MyFabricMods"
}
]
E: ほな、きどうしてみよか
(エラーなく起動)
E: まじか。 さすが A ちゃ、I ちゃんやね
I: 褒めても何も出ないよ
note
以降この設定に変更してます。
2025/08/16、Idea の Minecraft Development プラグインのバージョン2025.2-1.8.6でプロジェクト生成した場合です。
ブロック追加してみる
E: やっとブロック追加するで
I: もう、どうでもいいところでトラブル起こすんだから
E: ごめんて
ブロックの追加の仕方(簡易)
Identifier.of()で id を作成しますRegistryKey.of(RegistryKeys.BLOCK, Identifier)でブロックの RegistryKey を作成しますRegistryKey.of(RegistryKeys.ITEM, Identifier)でアイテムの RegistryKey を作成します
ブロックとアイテムは別の存在で、セットで使うようにこの後設定します。Blockインスタンスを作成しますBlockItemインスタンスを作成しますRegistry.register()でアイテムとブロックをそれぞれ追加しますマインクラフトを起動すると、
/give @p <MOD_ID>:<ITEM_NAME>でブロックが手に入るはずです。
左クリックで設置してみてください。
E: なんや意外と簡単そうやな
I: もうなんかだめそう
(とりあえず書いてみた)
package org.adw39.my_fabric_mods
import net.fabricmc.fabric.api.itemgroup.v1.ItemGroupEvents
import net.minecraft.advancement.criterion.ConsumeItemCriterion.Conditions.item
import net.minecraft.block.AbstractBlock
import net.minecraft.block.Block
import net.minecraft.item.BlockItem
import net.minecraft.item.Item
import net.minecraft.item.ItemGroups
import net.minecraft.registry.Registries
import net.minecraft.registry.Registry
import net.minecraft.registry.RegistryKey
import net.minecraft.registry.RegistryKeys
import net.minecraft.sound.BlockSoundGroup
import net.minecraft.util.Identifier
object MyBlocks {
val tatami = run {
val id = Identifier.of(MyFabricMods.MOD_ID, "tatami")
val blockKey = RegistryKey.of(RegistryKeys.BLOCK, id)
val itemKey = RegistryKey.of(RegistryKeys.ITEM, id)
val blockSetting = AbstractBlock.Settings.create()
.registryKey(blockKey)
.sounds(BlockSoundGroup.GRASS)
val block = Block(blockSetting)
val item = BlockItem(block, Item.Settings().registryKey(itemKey))
Registry.register(Registries.BLOCK, blockKey, block)
Registry.register(Registries.ITEM, itemKey, item)
block
}
fun initialize() {
ItemGroupEvents.modifyEntriesEvent(ItemGroups.BUILDING_BLOCKS).register {
it.add { tatami.asItem() }
}
}
}
E: ファイルは別に切り分けたで
I: クリエイティブインベントリにも追加済みです。
E: テクスチャついてないけど、起動確認するで
E: お、普通に起動したで
I: あっさり起動したね。 でも、一回間違えて BlockItemをItemで初期化してたの覚えてるよ
E: 余計なこと言わんくてええで
テクスチャを張ってみる
I: 私テクスチャ作ったことあるよ
E: そか。 なら簡単に追加できそうやね
I: そなの? バニラなら指定された部分の画像ファイルを変えたり、json ファイルを少しいじるだけだったよ
note
バニラのテクスチャの基礎知識記事を書きました。
テクスチャ編 part1
(実際に張ってみた)
I: なんで画像使いまわしてるの
E: 通信費圧縮のためやで。 いや、実際一ミリも変わってないで
I: 嘘でしょ
I: ...あれ、これ。 modID が item になってない?
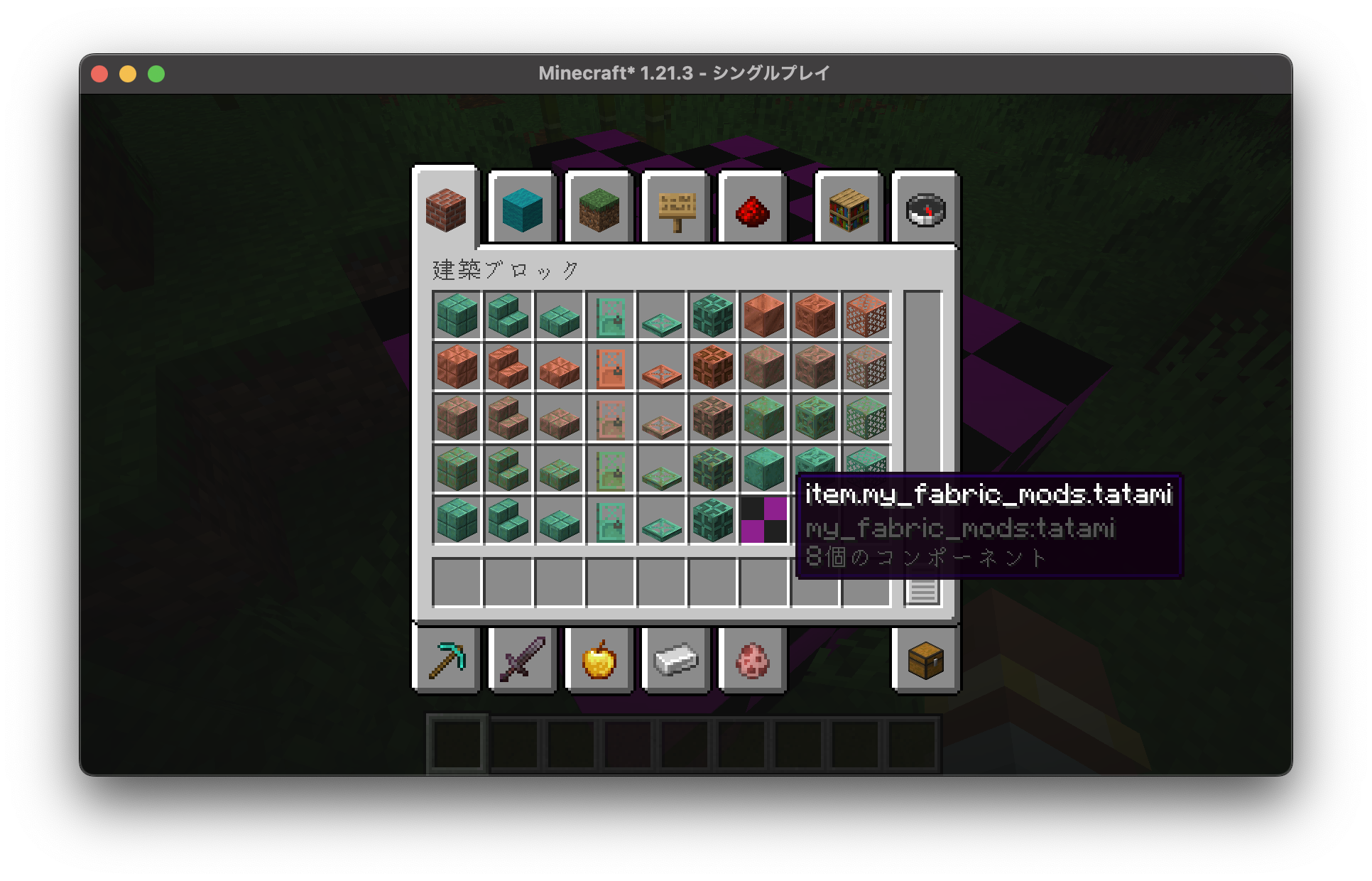
E: ほんまや、コーディングミスったかな
I: テクスチャの場所間違えたかな...?
(調べてみる)
テクスチャを置く場所
src/main/resources/assets/<MOD_ID>より中です
画像ファイルは
正方形で、src/main/resources/assets/<MOD_ID>/textureの中です。block、itemとサブディレクトリが続きます。
言語ファイル設定しましたか?
正方形で、src/main/resources/assets/<MOD_ID>/langの中です。 英語はen_us.json、日本語はja_jp.jsonです。
1.21.x 以降の Registry について
AbstractBlock.Settingsや、Item.Settingsの中にRegistryKeyを埋め込む必要があります。
...
(数時間後)
E: ぜんっぜんわからへん!
I: いっそjava で描き直そうよ...
E: いやや!うちは kotlin って決めたんや!
blockstates 登録しましたか?
ここに json ファイルおかないと表示されへんよ
E: BlockState ってあれやろ? ブロックの状態を示すやつ
I: すごい、まるでそのままだ。
E: そう思って無視してたけど
I: json ファイルを設置しないと表示されないみたいだね。
E: ...
I: ...
src/main/resources/assets/my_fabric_mods/lang/ja_jp.json
{
"item.my_fabric_mods.tatami": "畳"
}
tip
docs だと block だったけど、item にしたら適用されたよ
src/main/resources/assets/my_fabric_mods/blockstates/tatami.json
{
"variants": {
"": {
"model": "my_fabric_mods:block/tatami"
}
}
}
tip
モデルとテクスチャはバニラとあまり変化なかったので省略します
I: あの E: はい
I: 表示されてるんですが
E: すまんな
I: すまんなじゃないでしょ! やったね!
E: 今日は寝れそうやな
まとめ
E: ドキュメントは、ちゃんと最後まできっちり読みましょうっちゅうことや
I: そうだね。
I: 途中からタイポも多かったね
E: めんどくなってコピペに頼ってたで
I: 頻繁にコミットしてたから、やり直しが簡単だったのは良かったね。
E: せやなぁー
E: I ちゃんも、ネームスペースをminecraft:って書いててミスしまくってたで
I: バニラのモデルも使わないと行けなかったから、ちょっと混合してた。
E: ほな、次回はクラフトできるようにしたいで
I: そうだね。サバイバルモードでも使えるようにしたいよね。
注釈とか
日記さんの考えです。言わせてすみません。
日記さんまとめ
どうしてもやりたかった。(読みづらい記事になったことを)反省してる。
動画化?そのうちね。(口癖)
テクスチャ編 part1.
公開日: 2025/08/19
テクスチャ以前に画像編集能力高くないから
warning
この記事にテクスチャ追加方法、変更方法について、直接の方法で記載されていません。
(間接的に書いてますが)
純粋にテクスチャ追加するなら、別記事か、日記さんの次回作にご期待ください。
本日の一言
Aviutl2 でましたね。 wine 経由で入れようとして失敗しました。
Aviutl 好きだったので、Aviutl2 もどうにかして使えるようにしたい。(wine で無理やりやるか、win 機買うか)
テクスチャ編集について
リソースパックとテクスチャパックと言う単語が入り混じってて、昔はテクスチャパックだったらしい。
この記事ではリソースパックに統一します。
ブロックの見た目を画像ファイルとして保存している。
一般的な 3D ゲームと異なり、一面分あればブロックテクスチャとして十分使える。
形式は.png。 立体を表現する、モデルは.jsonで書かれている。
だいぶ単純な仕組みで動作してる。
画像ファイルのサイズについて
標準は16x16(pixel、以下単位は pixel)
重くなるのを覚悟の上、32x32、64x64...1024x1024 サイズと、高品質テクスチャにすることもできる。
編集ソフトについて
- gimp
でええやろ。画像編集は。(適当) - jar ファイルを解凍できるやつ(任意)
7zip とか。 最悪
.jarを.zipにすればいい。
そもそも本体のテクスチャってどこにある?
バニラランチャー使ってないので忘れた
client.jar参考
note
minecraft 本体のパス(multimc 系の場合)
<multimcのパス>/libraries/com/mojang/minecraft/<version>/minecraft-<version>-client.jar
jar ファイルを展開すると、中身は大量の.classファイルで埋め尽くされている。
ファイルブラウザのグループ化、シェルならcdと tab 連打で assets ディレクトリを探そう
assets 以降のパスについて
1.21.3 の場合(tree コマンドの結果)
assets/minecraft/以降で表示
.
├── atlases
├── blockstates
├── font
│ └── include
├── lang
├── models
│ ├── block
│ ├── equipment
│ └── item
├── particles
├── post_effect
├── shaders
│ ├── core
│ ├── include
│ └── post
├── texts
└── textures
├── block
├── colormap
├── effect
├── entity
│ ├── allay
│ ├── armorstand
│ ├── axolotl
│ ├── banner
│ ├── bear
│ ├── bed
│ ├── bee
│ ├── bell
│ ├── boat
│ ├── breeze
│ ├── camel
│ ├── cat
│ ├── chest
│ ├── chest_boat
│ ├── conduit
│ ├── cow
│ ├── creaking
│ ├── creeper
│ ├── decorated_pot
│ ├── end_crystal
│ ├── enderdragon
│ ├── enderman
│ ├── equipment
│ │ ├── horse_body
│ │ ├── humanoid
│ │ ├── humanoid_leggings
│ │ ├── llama_body
│ │ ├── wings
│ │ └── wolf_body
│ ├── fish
│ ├── fox
│ ├── frog
│ ├── ghast
│ ├── goat
│ ├── hoglin
│ ├── horse
│ ├── illager
│ ├── iron_golem
│ ├── llama
│ ├── panda
│ ├── parrot
│ ├── pig
│ ├── piglin
│ ├── player
│ │ ├── slim
│ │ └── wide
│ ├── projectiles
│ ├── rabbit
│ ├── sheep
│ ├── shield
│ ├── shulker
│ ├── signs
│ │ └── hanging
│ ├── skeleton
│ ├── slime
│ ├── sniffer
│ ├── spider
│ ├── squid
│ ├── strider
│ ├── tadpole
│ ├── turtle
│ ├── villager
│ │ ├── profession
│ │ ├── profession_level
│ │ └── type
│ ├── warden
│ ├── wither
│ ├── wolf
│ ├── zombie
│ └── zombie_villager
│ ├── profession
│ ├── profession_level
│ └── type
├── environment
├── font
├── gui
│ ├── advancements
│ │ └── backgrounds
│ ├── container
│ │ └── creative_inventory
│ ├── hanging_signs
│ ├── presets
│ ├── realms
│ ├── sprites
│ │ ├── advancements
│ │ ├── boss_bar
│ │ ├── container
│ │ │ ├── anvil
│ │ │ ├── beacon
│ │ │ ├── blast_furnace
│ │ │ ├── brewing_stand
│ │ │ ├── bundle
│ │ │ ├── cartography_table
│ │ │ ├── crafter
│ │ │ ├── creative_inventory
│ │ │ ├── enchanting_table
│ │ │ ├── furnace
│ │ │ ├── grindstone
│ │ │ ├── horse
│ │ │ ├── inventory
│ │ │ ├── loom
│ │ │ ├── smithing
│ │ │ ├── smoker
│ │ │ ├── stonecutter
│ │ │ └── villager
│ │ ├── gamemode_switcher
│ │ ├── hud
│ │ │ └── heart
│ │ ├── icon
│ │ ├── notification
│ │ ├── pending_invite
│ │ ├── player_list
│ │ ├── popup
│ │ ├── realm_status
│ │ ├── recipe_book
│ │ ├── server_list
│ │ ├── social_interactions
│ │ ├── spectator
│ │ ├── statistics
│ │ ├── toast
│ │ ├── tooltip
│ │ ├── transferable_list
│ │ ├── widget
│ │ └── world_list
│ └── title
│ └── background
├── item
├── map
│ └── decorations
├── misc
├── mob_effect
├── painting
├── particle
└── trims
├── color_palettes
├── entity
│ ├── humanoid
│ └── humanoid_leggings
└── items
名前空間について
assets/<名前空間>となってる。
mod が入れば、ここが変わる。
note
mod のテクスチャを変えたい時(かなりレアなケースだが)は、この名前空間の部分を ModID に置き換えれば Ok。
詳しくはfabric の記事参考
音楽がない
この中に見つからないものは、著作権などの関係上(?)別のファイルに設置されている模様。
models を見てみる
block なら、models/blockである。 アイテムなら、models/itemである。
tip
アイテムもモデルあります
平面モデルというのがありまして
assets/minecraft/models/block/stone.json
{
"parent": "minecraft:block/cube_all",
"textures": {
"all": "minecraft:block/stone"
}
}
王道の石モデル。 モデルと言いながらものすごくシンプルである。
parent(直訳は「親」)にも model が指定されている。 これを探してみよう。
assets/minecraft/models/block/cube_all.json
{
"parent": "block/cube",
"textures": {
"particle": "#all",
"down": "#all",
"up": "#all",
"north": "#all",
"east": "#all",
"south": "#all",
"west": "#all"
}
}
何とこちらもシンプルだった。
assets/minecraft/models/block/cube_all.json
{
"parent": "block/block",
"elements": [
{
"from": [0, 0, 0],
"to": [16, 16, 16],
"faces": {
"down": { "texture": "#down", "cullface": "down" },
"up": { "texture": "#up", "cullface": "up" },
"north": { "texture": "#north", "cullface": "north" },
"south": { "texture": "#south", "cullface": "south" },
"west": { "texture": "#west", "cullface": "west" },
"east": { "texture": "#east", "cullface": "east" }
}
}
]
}
少し細かくなった。
モデルは 1 ブロック 16 ドットあり、ドット単位で操作可能。
テクスチャは 32x32 と細かくできるが、モデルは 16 より細かくできない
assets/minecraft/models/block/cube_all.json
{
"gui_light": "side",
"display": {
"gui": {
"rotation": [30, 225, 0],
"translation": [0, 0, 0],
"scale": [0.625, 0.625, 0.625]
},
"ground": {
"rotation": [0, 0, 0],
"translation": [0, 3, 0],
"scale": [0.25, 0.25, 0.25]
},
"fixed": {
"rotation": [0, 0, 0],
"translation": [0, 0, 0],
"scale": [0.5, 0.5, 0.5]
},
"thirdperson_righthand": {
"rotation": [75, 45, 0],
"translation": [0, 2.5, 0],
"scale": [0.375, 0.375, 0.375]
},
"firstperson_righthand": {
"rotation": [0, 45, 0],
"translation": [0, 0, 0],
"scale": [0.4, 0.4, 0.4]
},
"firstperson_lefthand": {
"rotation": [0, 225, 0],
"translation": [0, 0, 0],
"scale": [0.4, 0.4, 0.4]
}
}
}
ここでは手に持った時のモデルなどを指定している模様。
と、json ファイル内部で変数が使用できたり、親を指定して継承できたりと高機能である。
一方でかなりシンプルに作られているのもわかる。
石のように全方面同じテクスチャならcube_allを使えば良い。
texture を見てみる
model が cube_all だったので、石のテクスチャは一面で済まされている。
lang を見てみる
ここも json 形式。
{
"minecraft:stone": "石ブロック"
}
みたいな形で指定できるらしい。
落とし穴
- blockstates の指定がない
fabric 記事見ていただいた方はわかるかと。 pack.mcmetaがない
これがないとリソースパックとして認識されない。次回説明。item、blockや名前空間(mod の場合)の指定ミス
minecraft:cube_allは mod 制作でブロック追加する時も頻繁に使用するので、名前空間が混在する。
まとめ
最初見た時は驚いた。 .objファイルとかあると思ってたので。
RenderScale はいいぞ
公開日: 2025/08/23
今でっかい記事書いてるので今日はこれで勘弁してください。
4K8K と AI 時代の処理軽量化術について
FSR2.0 や DLSS って知ってますか? 最近のゲームなどではよくみられるようになりました。
これらの技術は解像度の低いグラフィックからアップスケールする際に使われるAI 技術(DLSS)や、エフェクトで誤魔化す技術です。1
つまり、低い解像度でレンダリングして、アップスケールするという技術になります。
マイクラでも同じようなことできないだろうか?.
RenderScaleでは、単純なアルゴリズムで似たようなことを実現可能と思いました。
使ってみた感じ
 通常がこんな感じ
通常がこんな感じ
多少下がるけど、影 mod が 40FPS から 60FPS 超えるようになりました。
アップスケール目的だと思ってた
最初は軽量化 mod だと思って導入してみましたが、実際どうなんでしょうか。
どうやら、スクリーンショットのアップスケールの方が目的に近い気がします。
とはいえ、作者が紹介ページに FSR 対応するかもと書いてましたし、使い方としては間違えてない気がします。
超解像度技術の今後に期待したい
綺麗なディスプレイを使うと、FHD サイズに落とすと違和感を感じます。
違和感のないグラフィックで FPS を向上させようとなると、こう言った技術が使えるわけですね。
え?FHD ディスプレイにすればいいだろって?QoL が...()
参考
サーバー系
自宅で動かしているサーバーの話を書いてます。 プロではないので情報の精度には期待しないでください。(まぁこのサイト全般で言えること...)
どんなサーバーおいてるの?
セキュリティ観点からスペック等は公開しておりません。 また、このサイトであげた情報通りサーバーを構築しているとも限りません。 途中で変わってるかもしれない。
サーバーで運用しているサービスは?
マインクラフト鯖です。 リア友限ですが、いつかは公開鯖もやってみたいよねと思う。
ceph-monってなに?
ceph-mon 私もこの記事を書いている時点ではあまりよくわかってないんですが、 わかる範囲で例えるなら「図書館司書」
ところで、私の好きなゲームの話なのですが、図書館に引きこもりなんですが、本が、とても大好きな子がいるんです。
コミュ障なところがほんと好き。
ちなみに、コスト削減してくれるので結構有能です。
cephの概要
Cephは、複数のサーバーが連携して動作するクラスタシステムで、ストレージを共有・管理できるシステムのこと。 つまり、各サーバーが持つストレージを、一つのストレージとしてみることができます。
オブジェクト
Cephはオブジェクトストレージ。 データ一つ一つがオブジェクトと呼ばれています。
レプリケーション

冗長性を保つため、各サーバーストレージに複製を保存する機能です。 kubernetesでも似た様な技術が見られます。
OSD
Cephでは、ストレージ単体のことをOSD(Object Storage Device)と言います。 OSDはサーバー自体ではなく、サーバー内のストレージデバイスを指すので注意。
Ceph Monitor(ceph-mon)
Ceph Monitor (以下mon) はcephシステムの入口的存在。 役割は以下の通り
- 監視機能:OSDの状態を常に監視
- オブジェクト管理:オブジェクトがどのOSDに記録されているかを記録
ここが消えてしまえば、ストレージにアクセスすることはできません。 そのためmonは冗長化されています。

Map
地図です。データの配置や構造を記録されてます。
- ObjectMap: オブジェクトの位置を記録するMap
- MonMap: 冗長化されているmon同士が、どの様に働いているかを記録するMap
全てのmonは、このMapを同期しあい、ユニークになる様にしています。
図書館で例えると
- オブジェクトは本。
- OSDは書棚。
- monは司書。
書棚には本が置かれています。 そして(優秀な)司書は、本がどこに置かれているのか、 はっきりわかるわけです。 また、司書は仕事として、本の質を確認して回っています。
mapの場合は
Mapは司書が持っているツールです。 ObjectMapは本がどの書棚にあるかを記録 MonMapは司書同志の連絡帳ですね。
Mapの同期が取れてないと、別の司書が本を移した時、 「そこにあると思われていた本がない」といったトラブルにつながるわけです。

MonMapとIP
monmapは図書館で例えている時、連絡帳と書きました。 この連絡帳にはIPが書かれています。
epoch 16
fsid 12345678-abcd-1234-zyxw-9876-abcdefghijklm
last_changed 2025-01-20T12:40:16.621338+0000
created 2024-10-27T05:57:33.339382+0000
min_mon_release 18 (reef)
election_strategy: 1
0: [v2:192.168.1.10:3300/0,v1:192.168.1.10:6789/0] mon.node1
1: [v2:192.168.1.20:3300/0,v1:192.168.1.20:6789/0] mon.node2
dumped monmap epoch 16
これがmonmap。 至ってシンプルです。
epoch <monmapのバージョン>
fsid <cephシステムに使われる固有の識別子, id>
last_changed <最終更新日>
created <作成日>
min_mon_release 18 (reef) <おそらくmonの最低要件バージョン>
election_strategy: 1 <よくわからん...>
0: <monのipと名前>
...
dumped monmap epoch 16
monmapは、内部でバージョン管理されていて、 やろうと思えばロールバックができる構造になってます。 (...やり方知りませんが...)
monmapの取得方法
たくさんあります
cephコマンドが生きてる場合
cephコマンドが使える場合は、
ceph mon dump
で取得可能です。
cephコマンドが生きてない場合
ceph-monコマンドを使います。
そもそもこのコマンドは、monそのものなので
systemctlで立ち上げる場合、内部でコマンドが用いられます。
ceph-mon -i <monの名前> --extract-monmap <出力したい場所, ex: ~/monmap>
次に、monmaptoolを使います。
monmaptool --print <出力した場所, ex: ~/monmap>
その他
ほかにも ceph-monstore-toolを用いる方法もあります。
ceph-monstore-tool <mon storeの場所> get monmap -r
monstore
monstoreとは、monが持つ小さなデータベースです。 MonMapとObjectMapが保管されています。
場所
- microceph:
/var/snap/microceph/common/data/mon/<monの名前> - ceph:
/var/lib/ceph/mon/<monの名前>
monの名前を忘れた時、ここをみるとわかるかもしれません。
monmapを手動書き換えする
ceph-monコマンドで取得したmonmapは、monmaptoolを用いることで
書き換えることが可能です。
monmap関係でトラブルが発生した時はこの方法を用いることで解決できると思います。
また、書き換えたmonmapを再びmonstoreに戻す時は
ceph-mon -i <monの名前> --inject-monmap <出力した場所, ex: ~/monmap>
とすることで対応可能です。 なお、injectしたmonmapのバージョンは、自動的に引き上げられます。
コマンドリファレンス
参考
で、結局お前何やらかしたの?
ceph mon set-addrs <name> <addrs>
こういうコマンドがあります。 このコマンドはアドレスを変えるコマンドです。 うちでmonが動いているサーバーには複数のipがあります。
二個目のipに対応させるため、いい方法を探してたらこのコマンドを見つけたわけです。
もともと3ノードあったのですが、3ノード目で1ノードと同じipを設定したら、 1,3ノードともに動作しなくなりました。
結局、monmaptoolで3ノード目を消して解決しました。
...二週間。 学生でよかったと思った瞬間でした。
openwrt 同士で wireguard を張ってみる
ルーターなどのマシーン同士で wireguard を張ってみます。
🎵 本日の一曲
お洒落なミクうたです。 落ち着いた曲です。
バージョン情報
投稿日: 2025/07/31 openwrt: OpenWrt SNAPSHOT, r28931-90dee1ab306o 実験機器: fortigate 50e
note
2025 年 7 月の snapshot では、パッケージマネージャーが opkg から apk に変更になってます。
この記事でもパッケージマネージャーは apk を使用します。
パッケージインストール
# apk search wireguard
kmod-wireguard-6.6.80-r1
luci-proto-wireguard-25.192.00988~4715c6a
wireguard-tools-1.0.20250521-r1
- kmod: カーネルモジュール
- luci-: web ui 対応
- wireguard-tools: wireguard に必要なコマンドなど
この 3 つをインストール
構成について
今回は openwrt 機二つで、インターネット越しに vpn を張ってみようと思います。
通常のネットワーク(アンダーレイ)
flowchart LR
fg1["Fortigate 50E"] --- n1["インターネット"]
n1---fg2["Fortigate 50E"]
n1@{ shape: rounded}
---
config:
theme: redux
---
flowchart LR
ip1["FD00::0/64"]
node_a["a"]
node_b["b"]
node_a -- 1 --- ip1
ip1 -- 2 --- node_b
style ip1 stroke:none,color:none,fill:transparent
wireguard 内部からみたネットワーク(オーバーレイ)
flowchart LR
fg2["Fortigate 50E"] -- Wireguard --- fg1["Fortigate 50E"]
---
config:
theme: redux
---
flowchart LR
ip1["192.168.1.0/24"]
node_a["a"]
node_b["b"]
node_a -- 1 --- ip1
ip1 -- 2 --- node_b
style ip1 stroke:none,color:none,fill:transparent
鍵について
いわゆる ssl ってやつです。 ssh とほぼ同じ。
Curve25519 となんか聞き馴染みのありそうな鍵アルゴリズムを使ってる1ようですが、ed25519 とは別物のそうです。2
VPN を繋げてみる
gui でできます。
参考
wikipedia
自由記述型
カテゴリ化するのがめんどかった奴らはとりあえずここにあります。
検証するなら tmp 使えや
ファイル整理中にめっちゃ思ったこと。 tmp 使って欲しい。
tmp ってメモリに置かれるから(※OS による)、早い、自動で消してくれる、そして、SSD の寿命を奪わない
まじで人に「ファイルはこうつくります!!!」って見せびらかす時は
tmp 使ってくれ...
tmp とは
unix 系の OS には/tmpが備わってます。
このディレクトリは、再起動時に内容がリセットされる特性を持ってます。
この特性はメモリと同じです。
そのため、tmpfsという、メモリに展開される fs が存在し、使われていたりします。
note
windows では、C:\Users\{username}\AppData\Local\Tempが同じような役割を果たします。
(ただし、再起動時に内容がリセットされるわけではありません。)
(AI より)
特徴
- 再起動時に内容がリセットされる
tmpで使われる fs はtmpfsなことが多いtmpfsはメモリ(swap を含む)にデータを置く io が通常より早い可能性がある
コマンド
mktemp は /tmpにユニークなファイル or ディレクトリ(-d)を作成します。
temp=$(mktemp -d)などで生成するのがおすすめです。
tip
mktemp で生成されるファイル or ディレクトリは完全にランダム名で生成されます。 これにより、使用用途が外から特定されづらくなります。
warning
mktempで作られるファイル or ディレクトリ名には.が含まれているので、一部のプログラムでは動作しなくなる可能性があります。
また、cd $(mktemp -d)は推奨されません。 なぜならディレクトリを見失う可能性があるからです。
ユースケース
プロジェクトの生成を検証する時
例えば、vite でプロジェクトを作るときにどうすればいいか、迷いますよね。 そんなときに tmp です。 tmp に展開する時は、ファイル名を考える必要がありません。 再起動すれば全て消えます。
開発 RTA を行う時
mktempを使えば、プロジェクト名を考える必要性がなくなり、開発 RTA に貢献すると日記さんは考えます。
ダウンロードディレクトリ
ダウンロードしたファイルをダウンロードに放置するのは良くないと思う方は、tmp を使いましょう。
まとめ
tmp はいいぞ
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
このページの生成速度を上げた話
だいぶ早くなりました。
mdbookについて
いまこのページを作るのに使っているツール mdbookはrust製のソフトウェアで、名前の通りマークダウン形式で本(資料)を書けるのが特徴的です。
加えて、GithubActionsを活用し、ページ生成、GithubPagesへの登録まで一括して行なっています。
そのため、私はこのページを保管しているリポジトリにマークダウンファイルを配置し、PRしつつmainブランチにマージすれば、ページが追加されます。
割と便利。
cargo installについて
rust製のソフトウェア、ライブラリは、crates.ioによって登録、管理されています。 cargoというツールを活用することで、プロジェクトにライブラリを追加したり、rust製のアプリケーションをPCにインストールできます。
cargoは、aptなどのパッケージマネージャーと異なり、インストール時にビルドをするため、インストール時間がながくなってしまいがちです。
GithubActionsは、簡単に言えば一時的にlinux環境を借りることができる機能なのですが、処理が終わればその環境はリセットされます。 また、最低限の機能しか内臓されてない(とはいえdockerとかcargoとかは標準である)ので、mdbookをcargoでいちいちインストールする必要があるのです。
生成速度を上げるために
つまり、cargo installを回避すれば、高速化できるということです。
そこで、dockerの力を借りることにしました。
-> tam1192/MyMdbookContainer
あらかじめ、cargo installを済ませたmdbook内臓のdockerイメージを作成しておき、公開しておくことにしたのです。
このコンテナイメージはmdbookと、このページに使うプラグインを追加して、イメージにしております。
イメージの公開先は、ghcr.ioを活用してます。 githubが所有するコンテナリポジトリです。 github Actionsもgithubが所有する機能の一つなので、その繋がりで高速化が期待できそうですね!
結論
ページ生成が速くなりました。
お掃除2506
お掃除がてら数年前の自分を振り返りたいなと思ったので描きました。
命名規則や公開範囲とかについて
副操縦士に聞いたところ、-区切りで書くのが良いらしい。
面白いですね!遊びで試したプロジェクトやメモを整理するなら、カテゴリごとに名前を決めると管理しやすいかもしれません。例えば:
- sandbox-*:試作や遊びで作ったコード
- prototype-*:アイデアを形にしたもの
- experiments-*:技術検証用
- archive-*:過去のプロジェクトやメモの保存庫
- notes-*:設計やアイデアのメモ
例えば、Tailwindの新しいユーティリティを試したなら
sandbox-tailwind-experiments、Nuxt×Ollamaのアイデアならprototype-ai-guiみたいな感じ。あとは用途別に分けるのもいいですね:
fun-projectssmall-toolsrandom-ideas何か気に入るものはありますか?一緒にいい名前考えましょうか!
そもそも遊びのコードをそのまま放置するのは良くない、それこそtmp使えや!ですよ!
とはいえ、残したいと言う気分があるので、ネタに残せるレベルだったら残す方針で。
思い出話
整理しながら懐かしいrepo触ってるので、せっかくだし思い出話をしてしまおうと思います。
vox-ttsシリーズの開発と試行錯誤
vox-ttsは、VoicevoxのREST APIを活用したDiscord TTSボットで、私が最初に「書き切った!」と感じたプログラムのひとつ。Pythonで始め、のちにJSへ移行しました。この過程で得た知見を振り返ります。
開発のきっかけは、VoicevoxがREST API経由で音声合成できると知った瞬間の衝動。「これはやらねばならぬ」とコードを書き始めました。Python (discord.py) を使いましたが、後にJS (discord.js) へ移行。その理由は、ライブラリの不安定さよりも応答速度の改善を期待してた。しかし、最終的にはVoicevoxの生成時間がボトルネックだったため、この変更はそんなに意味がなかったです。
とはいえ、JSを選んだことで、イベント駆動型の設計が活きるようになりました。Discordのような「いつ発生するかわからない処理」に向いていて、非同期処理の管理がしやすい。特にPromise.allが便利で、APIコールの最適化に活用しました。例えば、複数のデータ取得を並列化することで、待機時間を短縮できます。
const [userData, posts, comments] = await Promise.all([
fetch('/api/user').then(res => res.json()),
fetch('/api/posts').then(res => res.json()),
fetch('/api/comments').then(res => res.json()),
]);
console.log(userData, posts, comments);
(Promise.allの一例)
マルチスレッドと比較すると、JSの非同期処理は考えることが少なくて済むのが強み。スレッド管理や共有変数の競合を気にする必要がなく、awaitを必要な箇所だけに書けばいいのが直感的です。
vox-ttsの開発を通じて、PythonとJSそれぞれの特性や非同期処理を深く理解できました。イベント駆動型の設計は、リアルタイム処理を必要とするコードには最適です。
リポジトリへのリンク
- vox-tts.py
- vox-tts.js
- node-voxclient
Voicevoxを使う関数群を分離したやつです。 ...全然記憶にない
- node-voxclient
参考など
experiments-discord-bot.js & node-dirtools
vox-tts.jsを作る前に検証用として作ったbotです。
vox-ttsの項で大体の説明をしてしまったため、ここではリポジトリのリンクに留めます。
リポジトリへのリンク
experiments-blockview.rs: Rustとの出会いと試作コード
Rustに触れ始めたきっかけは、ゲームのmod修正でした。
致命的なバグが放置されていて、誰も修正しようとしていなかったので、「ならば自分で直してみよう」と思ったのが始まり。Rustの本を読みつつ、当時流行っていたAIも活用しながらコードを書き進めました。
最初は試行錯誤の連続で、書いたコードも拙いものでした。unsafeを使いまくる方法を取っていたので、PRを出した際に大量の指摘を受けました。しかし、それが結果的にRustの型システムや所有権の概念を深く理解する良い機会になったと思っています。
Rustで書いた試作コード
Rustを学ぶために書いたコードのひとつに、8色程度の色データを配列に入れ、それを標準出力に四角絵文字で表示するプログラムがあります。例えば:
🟥🟦🟨🟩
実装方法としては、色データをenumで管理し、出力時には対応する絵文字を使う形を採用しました。
一見シンプルですが、後から見返すとswapを使ってデータを入れ替えたり、二次元配列で管理すべきデータを一次元配列に縛ったりと、なかなか無茶な設計をしていたことに気付きました。
とはいえ、この試作を通じてRustの型管理や所有権の扱い、さらにはデータ構造の設計について多くの学びが得られました。
今後はbmpに保存できるようにしたい...(現在やってる)
リポジトリへのリンク
experiments-wasm-vue
名前変えました。 そして書いてたら長くなったのでページ分けました
-> Vue × WASM × Rust—試行錯誤とこれからの展望
item_json_maker: Minecraftリソースパック制作のためのツール
Minecraftのリソースパックを作る際に使用するツールとして、item_json_maker を作成しました。 出番はあまりないかもしれませんが、必要になったときに便利なツールになればと思います。
開発のスタイル
このツールは、HTML・CSS・JSのみで作られており、Vueやその他のフレームワークは使用していません。 Bootstrapを活用しており、classを指定するだけでスタイルを整えてくれるので、その点はとても楽でした。 ただし、Vueを知ってしまうと、プレーンなHTMLが整理されていないように見えてしまう問題があるのも事実。 ファイルを適切に分割することで解決できる部分もありますが、シンプルなツールなのでこの形式でまとめています。
余談
中学生の頃はHTMLとJSを活用して遊んでいました。 特にJSは、使用例を載せているサイトを参考にしながら、自分でサイトを拡張していくのが楽しかったです。 こういう技術を学ぶ過程って、ただ知識を増やすだけでなく、「試してみる」「遊んでみる」ことが大事だと思っています。 今でも新しい技術に触れるときは、ショールームを見ているような感覚でワクワクしますね。
今後
今のところ拡張の予定はありませんが、今後こういったツールを作るなら、VueやWASMも活用してみたいと考えています。 フレームワークを使うことで、より整理されたコードが書けるようになるし、WASMを組み合わせることでパフォーマンス面でも強化できそうですね。 新しい技術を活かす場面が出てきたら、またツールを作ってみようと思います!
リポジトリへのリンク
comAccess: Windowsでシリアルポート通信を可能にするツール
WindowsにはWindows Terminalという非常に使いやすいターミナルが備わっていますが、
シリアルポートに直接接続できないという制約があります。
その不便さを解消するために、Windows APIを駆使してcomポートアクセス用のプログラムを作成しました。
開発の経緯—シリアル通信の難しさ
開発を進める中で、シリアルポートの制御が意外とシビアであることを実感しました。
特にWindows環境では、通信の安定性やデバイスの排他制御など、考慮すべき点が多くあります。
最初はCで書きましたが、cisco機の一部は認識しなかったりとまだまだ改善の余地があります。
この過程で、Teratermの偉大さを改めて感じました。
長年シリアル通信の定番ソフトとして君臨している理由がよく分かりますね。
Rustでの挑戦と課題
実は、Rustを使ってcomAccessを作ろうと試みましたが、こちらは更に通信がうまくいかず、実装に苦戦しました。
Rustには環境に依存しないserialportクレートがあり、これを利用しようとしましたが、
実際に通信が来ない問題に直面しました。
さらに、Cの時同様に、Windowsの排他制御も面倒で、ポートの管理に苦戦。
結果として、Rustでの実装を諦めました。
Windows環境の変化—weztermとの併用
最近、使用する環境がMacに変わったことで、シリアル通信の選択肢が増えました。
Macではscreenコマンドを使えばシリアル通信が可能になります。
とはいえ、weztermというRust製ターミナルも並行して使用しており、
試行錯誤しながら快適な環境を模索しています。
weztermの強みとして、
- フォントの柔軟なカスタマイズ
- 画像表示機能
- 高度なタイル型ウィンドウ管理
などがあり、標準のターミナルとは違った使い勝手がありそうです。
今後、使い込んでいく中で特筆したいポイントが出てきたら、記事にまとめたいと思います。
リポジトリへのリンク
MCAutoShutdownPlugin
Minecraftのプラグイン開発は、比較的手軽に始められるものの、
実際に作ってみると様々な技術的な発見があります。
今回は、人がいないときにMinecraftサーバーを自動でシャットダウンするプラグイン、
MCAutoShutdownPlugin を開発した経験をもとに、学んだことを整理してみます。
開発のきっかけと目的
「いつかMinecraft関係のコードを書くぞ」と思い立ち、比較的シンプルな目的のプラグインを作るところから始めました。
Minecraftのプラグインは、基本的にサーバー環境の拡張を目的としており、
既存のAPIを活用しながら機能を追加できるため、比較的簡単に実装できます。
しかし、簡単だからこそ、満足感が薄いと感じる部分もありました。
クライアントで動くmodと異なり、制約も多いというのが実感です。
デザインパターンとの向き合い方
このプラグインを開発するにあたり、デザインパターンの理解が必要だと感じ、少しだけ理解してきました。 特にシングルトンパターンはよく使われ、Minecraftプラグインのコア部分を扱う際にも頻繁に登場します。
ただし、それ以外のデザインパターンはほぼ使いませんでした。
その理由は単純で、この規模のプラグインでは必要なかったからです。
適切な設計を考えることは重要ですが、無理にパターンを適用するのではなく、
「本当に必要かどうか」を見極めることも大切だと学びました。
今後のプラグイン開発について
この経験を通じて、Minecraftのプラグイン開発の流れを理解できたので、今後も新しいプラグインに挑戦する予定です。
次にプラグインを作る際には、もっと複雑な処理やデザインパターンを意識した設計を試してみたいと考えています。
リポジトリへのリンク
お掃除まとめ
色々書きましたが(...AIが書いてくれましたが)
懐かしいものから、続きを作りたいものもたくさん出てきたので、今後もっと深めていけたらと思いましたとさ。
ループバックアドレスでIP節約
 (ダークモードだと見づらいのは気のせいです。)
(ダークモードだと見づらいのは気のせいです。)
ということで、ループバックアドレス使って極力IP減らしました。
note
この記事は、とある理由でグローバルIPなど特定のIP(以下グローバルIPという)の割り当てを減らしたい人向けに書いております。
自宅など、プライベートアドレスの節約については書いておりません。
プライベートIPとグローバルIP(/32)をうまく併用すれば、グローバルIPを節約しつつネットワークを構成できます。
本記事では、ループバックアドレスや/32, /31の使い方に加え、プライベートIPとの併用によるIP節約テクニックを紹介します。
結論1

/32と/31を使うと無駄なIPが減ります!
無駄なIPって?
ここでは、無駄なIPとは、次のアドレスのことを言う。
- ネットワークアドレス
- ブロードキャストアドレス
おいおいまてよ、二つとも本当に不要なのかい?
と思うかもしれません。 まぁぶっちゃけ不要じゃね?知らんけど。
とにかくこの二つは機材にアサインすることもできないし、
機材にアサインできないってことは、サーバーとして使えるアドレスじゃないし
warning
私はたまに適当なこと言います、気になったら調べてほしい
じゃあ消そう!とはいかない
ネットワークを構成するには、RFCというお約束により、 上記二つのアドレスは一部の例外を除いて必ず発生してしまうのです
無駄なIPが消える例外なネットワーク
そもそも例外なネットワークはまず、ネットワークと言っていいのかわかりません。
ネットワークって複数の機材を繋げあう技術でしょう?
例外1: /31 一対一のネットワーク
コンピューター間を一対一で繋げる場合は、/30と/31が用いられます。
このうち、/30はアドレス空間的に4つのアドレス(32-30=2[bit]=4通り)割り振れて、
/31はアドレス空間的に2つのアドレス(32-31=1[bit]=2通り)割り振れます。
しかし、無駄なアドレス二つを割り振ろうとすると、
/30で使える実際に使えるアドレスは2つになり、
/31に至っては0になります。
実はここで例外が発生します。/31のように、無駄なIPによって実際に割り当てられるアドレスが0になる場合、 無駄なアドレスは発生しなくなるのです。
すなわち、/31は二つのアドレスが使用可能となります。
...実は、/31は長年議論されていたようで、古いルーターですと設定できないみたいです。
例外2: /32 一つのアドレス
/32はもはやアドレス一つを指します。 ネットワークを構成できません。 /31の時のように、例外が発動します。
/32の用途はこのあと例に挙げますが、ネットワークを構成する必要がない、自分自身を示す際に使用できます。
例外まとめ
そもそも例外と言ってますけど、二つのアドレスの意味を考えると
- ネットワークアドレス
/32はそもそもネットワークともいえない
/31は設定する余裕がない - ブロードキャストアドレス
/31も/32もブロードキャストするメリットがない
ということで、必要がなくなるというわけです。
結論1まとめ
冒頭にもあるこの図のように、/31と/32を使えば、隅々にまでアドレスを割り当てることが可能となります。
結論2
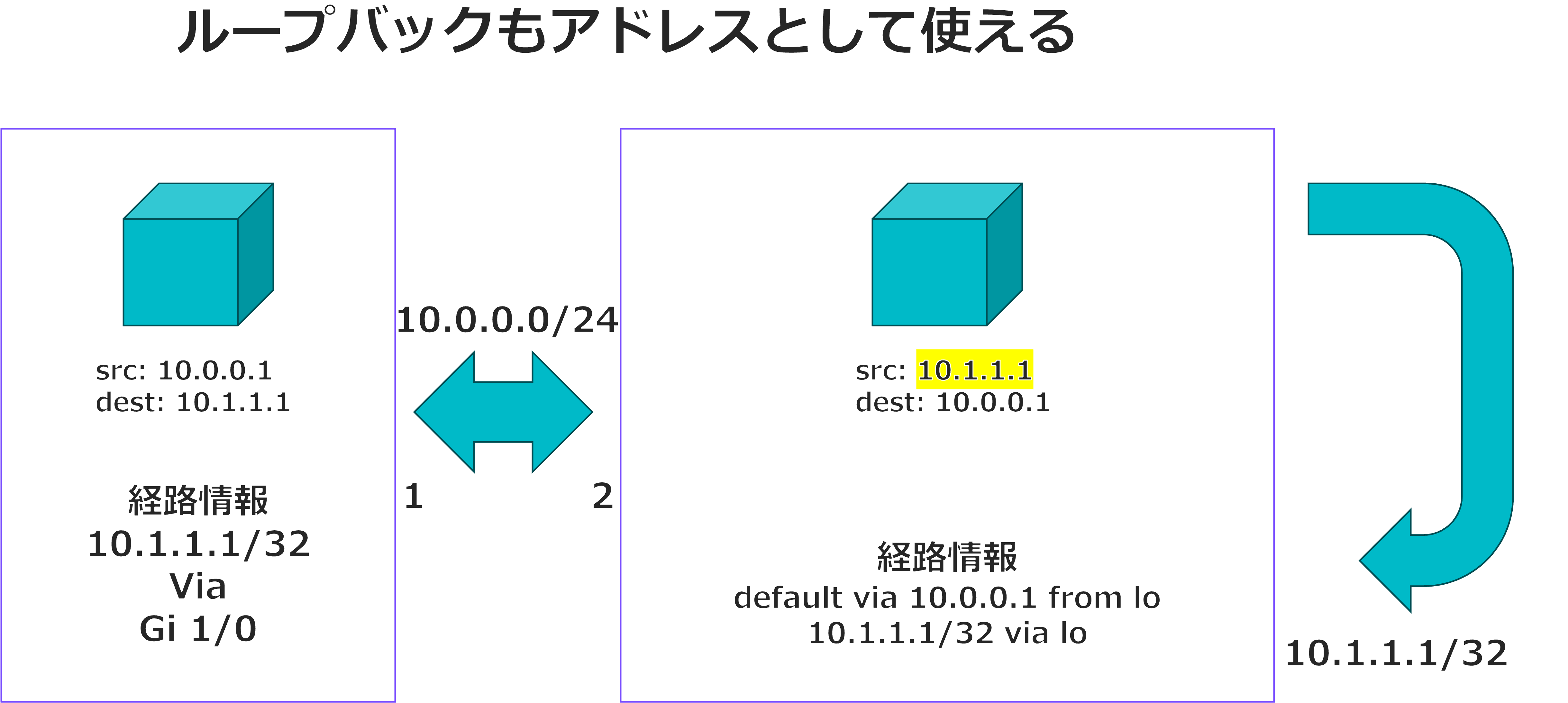
こっちは簡単です。
冒頭のノートに述べた通り、基本はプライベートIPを使用しつつ、/32で割り当て可能なループバックにグローバルIPアドレスを使うことでIPを節約します。
その、ループバックアドレスで通信する方法ですが、ループバックアドレスを上流ルーターに経路通知すれば、通信が可能になるってことです。
warning
懸念点を挙げるとすれば、ループバックアドレスを設定した機材からは、ループバックアドレスを使って外に出るようにしなければならないことです。 図にも黄色蛍光ペンで強調させてますが、パケットのsrcがloopbackアドレスのものにならなければならないということです。
この設定が可能でないと、この手法はとれないことになります。
netplanの場合
netplanの場合はroutesの中でfromが使えます。 これを設定することにより、loアドレスからパケットが送出されるようになります。
network:
version: 2
ethernets:
lo:
addresses:
- 10.1.1.1/32
enp1s0:
dhcp4: false
dhcp6: false
accept-ra: false
addresses:
- 10.0.0.2/24
routes:
- to: default
via: 10.0.0.1
from: 10.1.1.1
nameservers:
addresses:
- 8.8.8.8
- 8.8.4.4
/31はあまり意味がない
L3スイッチなどのポートごとに1つ、さらに相手側(仮想サーバーなど)にも1つIPを割り当てる必要があり、結局2つ消費します。
一方、/32とプライベートIP(例えば 192.168.x.x など)を併用すれば、プライベートIPは枯渇しにくいので、
L3スイッチ側はプライベートIPを割り当て、相手側のループバックにグローバルな/32を割り当てれば済みます。
要するに、/32+プライベートIPでやらないとIP節約につながらないのです。 (一つのサーバーで複数のグローバルIPを使いたいなら別)
まとめ
ループバックアドレスや/32の活用、そしてプライベートIPとの併用によって、
無駄なグローバルIP消費を最小限に抑えることができます。IP枯渇対策の一案としてご参考まで!
...という今更の話題でした。
参考
- Netplan documentation(routing)
- github copilot
PRとかで意見もらえそうなので使ってみました。
こんな記事に使うな
Algorithm.rs について
アルゴリズム勉強のメモを残すのをnotepad.mdとは別に作ってしまった。
ただ、ネタがない。 多分atcoderとかの問題をひねったやつをそのまま書いてたり、 もしくはマジモンのwriteupになったりすると思います。
mdbookをさらに強くしてみた。
まずLatex...数式を導入してみた。
みました。
Latexとの出会いはそんな最近ではなく、数年前から数式のメモをするために使っていました。
...綺麗だね。 自分がペンで書くより綺麗に描画されるから、質の良いノートを取れる気分になるよ。
かさねてと
mdbookとcargo docをかさねてみと
mainブランチで試行錯誤してました。 mdbookとdoc生成をそれぞれ別のjobで行い、 actions/upload-artifact@v4 、 actions/download-artifact@v4で合成しました。
jobを分けたのは、まぁめんどかったからです。
mdbookの中にドキュメントを埋め込む形にしました。 最初にmdbook側のページが出て、パスを深くするとdocが出てきまし。 mdbook側で誘導します。
あんま綺麗にできなかったよね。 研究の余地ありです。
editableでrunnableなコードブロック
mdbookの実力をまだ試してませんでした。 実はnodejsとか、vueとかでもできるらしいですが、
まぁまずはrustだけでいいやろと。
fn main() { let x = 10; //変更してみて println!("{}", x); }
表現の幅が広がりそうです。
外は暑い
本当に暑いです。 エアコンが死ぬんじゃないかってレベルで。
ですが、これは私の体感ですが、去年よりは難易度が少し低いように感じております。
6月って結構灼熱地獄だった覚えがありますが、どうでしたっけ。 2024
サーバーどうしよう
誰もがまず、この問題に辿り着きます。 扇風機を向けておくか。
今年の私は鯖を止め、コーディング集中で、アルゴリズムで乗り越えてみようと思いました。 結局要求スペックが下がれば、その分電力は減るわけですし。
速度より並列化
並列にできるものはどんどんした方が良いよね。 実際には同期とかで難しいですが。
jsのasync/awaitはうまく使えそうな気がします。
しかし、async/awaitは終了を待つことしかできないのが難点です。
2L水は味方
2L水は味方です。 片手に持って通勤しましょう。 重いけど、飲みきれます。 だって暑いから。
携帯電話はもはや電話じゃない
けーたいって最近耳につけることあるか? 汗で画面汚れるから基本イヤホン使うよなって話
本日の 1 曲 🎶
かわいい
ちな、スマホを忘れることは少ないですよね。 suica やクレカを混ぜてるから必需品、メガネの次に肩身離さずいる存在です。
まぁ肝心なメガネを忘れることがあるんですが...
Bluetooth イヤホン
Bluetooth イヤホンは、通話中、死ぬほど音質が悪くなる印象です。 安いからでしょうか?
airpods 買いたい。
IPhone と通話
IPhone や IPad で通話しようとすると、ハウリングを防ぐためか、スピーカーの音質が非常に悪くなります。
この仕様、イヤホン繋げたときに解消する様にして欲しいんすよね。
Bluetooth イヤホンにマイクいらない。
特に安物だと、マイクいりません。 そもそも耳の位置から声を拾っているので...
そう思うんですけど私だけですかね。
まとめ
IPhone を耳につけることはない。 耳にはイヤホンをつけよう。そう思ったのでした。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
スマホで記事書いてみた!
という内容の記事です。
書き心地はいかが?
クソ
スマホ何使ってるの?
iPhone
どうやって書いてるの?
github web版
playground について
プログラミング言語を試せるサイト「Playground」と、mdbook についてメモるために書きました。
🎵 本日の一曲
夏です。暑いです。
rust の playground
シンプルな見た目ですが、割と機能が豊富です。
rustfmt
rustfmt は、実際の PJ ではcargo fmtで実行できるコードフォーマッターです。
Playground でもこれが実行できます。 右上のtools -> rustfmtです。
あのキーバインドが使える
vi,emacsなどが使えます。 内部でace エディタが動いている模様?
右上のconfig -> editorを ace に -> configの内容が代わり、keybindが選べるようになる
mdbook 埋め込み対応
mdbookに埋め込みができる。
# fn main() {
println!("hello");
# }
というコードブロックを書くと、
fn main() { println!("hello"); }
必要な部分だけを見せることができるとか、
fn main() { println!(""); // ここを変更 }
rust,editableとすれば、読者が編集できるようになったりと、独自機能がたくさんついてる。
kotlin の playground
play.kotlinlang.orgにて利用可能。
埋め込みにも対応してる。 (iframe タグで埋め込む)
html/css/js の playground
livecodersが有能だと思う。 これも埋め込み対応。
いろいろな方法で埋め込められるけど、mdbook なら iframe がおすすめかな?
コミットしろよ
この記事は表現が(多少)過激であり、職場または学校、学習で見るのにふさわしくない内容です。
より良い情報はqiita などの記事を参考されることを強く推奨します。
記事をみる

(このコミットは完全に個人プロジェクトで行ったものです)
過去の自分に対する強い怒りをコミットメッセージに込めました。
というのも、このコミットで何をしたのか理解できなかったからです。
もしトイレで席を離れる場合はコミットだけはしましょう
このレベルでコミットはすべきなんです。私はそう思う。
快活で作業してみた
快活に行ってみたという記事です。
note
十割どころか百割感想です。
本日のひとこと
あとでやりたいゲーム
実は Subnautica 一通り終えたから、新しいゲーム探してたけど、これ良さそうじゃない?
アカネチャン実況見てて思った。
マルチ対応してるらしいし、なんか友達持ってるらしいから今度やってみようかと思ってる。
どんなところ?
ネカフェです。 寝カフェでもあります。
少し前まで、18 きっぷと快活の組み合わせが最強だなって思っていました。
夜更かしして翌日新快速乗り過ごすオチである(経験済み)
店舗によって異なる
18 きっぷのおかげでいろんな快活めぐってます。快活目的の旅と言わざる得ない
店舗によって差がないのすごい。
note
てか、大手チェーン店ってどこ行ってもあまり差がないのすごいよなと思ってる。
おかげで実家のような安心感感じられるんだよね。 (...うーんそれはいいことと言えるのだろうか。)
しかし、新横浜店
ここは違った。オフィス街なこともあって、ビジネス向けって感じでした。
ドリンク vs 鍵付き個室
鍵付き個室というのもあります。 ドリンクバーもあります。
法的に鍵付個室に店舗提供の飲食物を持ち込んではならないとのことです。注意したい。
鍵付きを選んでドリンクを犠牲にするか、通常個室でドリンクをつけるか
正直どっちでもありだと思います。鍵付きでも個室外だったら飲めるので。(鍵付き個室もドリンク料含まれてる)
電磁錠
磁力動く鍵が採用されてました。 これすごいですよね。
磁力で扉を吸い付けてロックしているそうです。
流石にやらないですが、どこまで力を込めないとあかないか気になります。
一般個室のうるささ
イヤホンつければ気にならないと思います。
ただ、匂いは少し気になる。
【ブルーアーカイブ】ユウカ ASMR ~頑張るあなたのすぐそばに~
asmr 聴くならノイズキャンセリングイヤホンは欲しいかもしれない。 うーん微妙。
日記さんは結構寛容難聴な方だと思ってるので、いらなかったです。
まとめ
快活で開発しようと思ったけど、RTX シリーズ GPU 付きの PC あるってなったらゲームするに決まってんだろ!いい加減にしろ!
完全作業環境専用 PC しかないワイ、エントロピーセンターをゲーミング PC でやってみたけど楽しかった。(適当)
"tam1192"repo のルール変えました
公開日: 2025/08/20
名前の通りです。
ブランチ名
<動作>/<大カテゴリ>/<ページ名>で作成 <ディレクトリ動作>/<大カテゴリ>/<大カテゴリ>...
動作
- New: 新規作成
- Fix: 内容の修正
- Change: 内容の変更
- Delete: 記事削除
- AddFix: 内容の補填
ディレクトリ動作
- SplitCate: カテゴリ分離 (分離元、分離先でカテゴリ名を入れる。)
- JoinCate: カテゴリ統合 (統合するカテゴリ名全てをブランチ名に入れる)
コミットメッセージ
PR で main にマージする時のルールで、次の通りとする。
<ブランチ名> (空白行) <変更の概要> (空白行) <コミット一覧>
PR のルール
main へのマージは、squash marge を用いること。
その他
- マージ時のメッセージで、rebase などでコミットが乱れてる場合、必要なコミットのみ記入する
- ブランチ作り直す時は、ページ名の後に_アンダースコアをつける。
究極の immutable を追え
公開日: 2025/08/22
そういうお話です。
🎵 本日の一曲
ねこすい
イミュータブルとは?
不変を意味する。
rust の例
rust の変数は、mutをつけないと変更できない。
変更されているように見えるのはシャドーイングされてるだけ。
fn main() { let x = 3; let x = 4; // シャドーイング let mut x = 3; x = 4; // ミュータブル }
kotlin の例
valをつけると immutable になる。 varにするとミュータブルになる。
シャドーイングは推奨されてない。
OS での例
ハーベスターという仮想化基盤では、ベアメタル上の OS がイミュータブルとなってる。
言い換えると、再起動すると中身がリセットされる。
代わりに、Kubernetes の設定を etcd に、一部の設定ファイルのみを可変とすることで、必要最低限の可変が許容されてる
言い換えると、変更できるところだけ残るようになってる。
ルーター機なども rom と ram、nvram、フラッシュメモリと必要に応じてメモリを使い分けている。
メリットはランサムウェアへの耐性が強くなること
不変の世界じゃ、暗号化する(変更する)、消すという作業もできないからね。
イミュータブルが必要な理由
他の人と情報を共有する時は、イミュータブルにしたほうがいい。
情報が広まれば広まるほど、変更が効かなくなるから。
プログラミングで必要な理由
関数の前提として、入力が何らかに処理にかけられ、出力されるである。
一方通行である。 まさか入力で入れた変数が結果として入力から帰ってくるとは思いたくない。
fn add_5(num: &mut i32) { *num += 5; } fn main() { let mut x = 0; add_5(&mut x); println!("{}", x); }
できてしまう。 変数 x を関数に入力させ、 println で x の中身を出力させれば、見事に値が変わってる。 rust ではmut のおかげで値が変わることを目に見えてわかる。
x = { num: 0 };
add_5(x);
console.log(x);
出力はどうなるだろう? 0 を期待したいが、結果は 5 となる。
add_5関数の内容
function add_5(num_obj) {
num_obj.num = num_obj.num + 5;
}
javascript ではオブジェクトの場合参照渡しを行うため、このようなことが実現できてしまう。
javascriptの例というより、mut がない場合をみて欲しかった。
関数に入れた変数が、そのまま出力として内容が書き換えられていたという事例である。
変更は少ない方が信用される
例えば、カラオケの予定を決めたとする。 直前になってキャンセルされたら普通キレる。
一週間前なら諦める。
変更をかけるというのは他の人への影響を考えなければならない
変更は少ない方が、めんどさが減る
変更は少ない方が信頼される、と思う。
SSD にやさしい
一般的に ssd は書き込みに寿命があると言われる。
一方ランダムアクセスは強い。
変更は差分のみの記録とすれば、書き込みを少なくすることができる。
そして、ランサムウェアへの耐性が高くなる
note
暗号化するという差分のみを記録するので、元データは残るため
note
HDD のようにランダムアクセスに弱いと、ディスク中に散らばる差分データを組み合わせるだけで時間がかかる
まとめ
immutable によってシステムの耐性を強化しよう。
...ところでこの記事いる?
新幹線で作業してみた
いろんな環境で作業してるなこいつ
東北新幹線
東北新幹線はよく乗ります。 E5 系やとコンセントが壁側しかないので、電源タップを持ち込み 3 人 2 人で共有するらしい。
車両の先頭側の席は壁についた机と、壁についたコンセントが使えます。 ここだと机の幅が大きいし、コンセントも 1 人で独占できるのがよさそう。
(ただしいわゆる優先席扱いらしいので、取れたら奇跡?)
ヘッドレスト動くの最高だよね。
ネット
福島周辺はインターネットが途切れます。 freewifi ではなく、テザリング使ってました。
山だからねぇ---
東海道新幹線
たまに乗ります。 N700S だと各席にコンセントがあるので便利。
まとめ
列車内での作業はいいぞー
関越道の工事が多くて草
投稿日:2025/08/26
連日の疲れが蓄積されているせいでこのブログを書くところまで手が動かなかったので、これで勘弁してください。
関越って何してたの
新潟行ってました。 正しくは少し遅れたお盆帰省の帰りに新潟よりました。
関越道の工事
8/25 時点で工事の数が多く、車線規制が非常に多かったです。
深夜帯で空いてたから良かったものの、混んでいたらどうなったかと...
左車線、右車線交互に工事してる感じでした。
反省点
下調べして、工事状況とかみておくべきでしたね。
新潟のバイパスってすげぇな
国道 7 号を中心とした、無料バイパスがあります。
70km/h 制限で、高速並のスペックで良かったです。
おわり
明日からはまともな記事を書く予定です。 今日は寝てます。
練ればねれほど疲れる
という記事。
2 時間睡眠
叩き起こされないと無理。
6 時間睡眠
大体十分だと思う。 ただし油断すると眠くなる。
8 時間睡眠
余裕があればこれくらいは寝ときたい指標。
10 時間以上
だんだんと体が痛くなり、だるくなる。
だるくなると寝たくなる。辛い。
集中力もなくなる。 よくない。
まとめ
短時間の睡眠はそもそもできない。
起きれたら、もう十分寝たと言うこと。
二度寝は想定以上に負の影響を持ってる。
最後の夏に毎日投稿してみた件
投稿日:2025/08/31
日記さん今年で学生生活終わるってよ
毎日投稿?
このページを管理しているリポジトリにある main ブランチのコミット履歴をみてみると...
44d63a8 2025-08-30 New/freewrite/寝たら体が痛くなる (#107)
fd4ee69 2025-08-29 New/coding-nikki/parser-2 (#106)
40a5997 2025-08-29 Change/coding-nikki/parser-1 (#105)
c0b5519 2025-08-28 New/coding-nikki/構文解析1 (#104)
0fb5ec0 2025-08-27 New/coding-nikki/crate-introduce/1/Readme.md (#103)
2890b2b 2025-08-26 書き終えた (#102)
71d1f10 2025-08-25 New/freewrite/新幹線で作業してみた
c4b1c51 2025-08-24 New/ひとくちメモ/リポジトリを作り直した件 (#100)
e69b0ed 2025-08-23 New/mc/RenderScaleはいいぞ
df16378 2025-08-23 RenameCate/ひとくちメモ/short-note
d64d3b9 2025-08-22 New/freewrite/究極のimmutableを追え
a7f3851 2025-08-21 New/Games/ブルアカ4.5周年
a351ec9 2025-08-20 New/FW/tam1192_repoのルール変えました
04553a6 2025-08-19 New/mc/テクスチャを貼る (#94)
bd0cc6d 2025-08-18 New/MC/fabric_2_
f7f08ef 2025-08-17 New/freewrite/kaikatu (#91)
504f049 2025-08-16 マインクラフト記事をCoddingNikkiから分離
ae75363 2025-08-16 New/gm/ba/hard (#89)
11cde77 2025-08-15 Fix/fabric/1 (#88)
5492d30 2025-08-15 New/mc/fabric/block作ってみた (#87)
5acce5a 2025-08-14 New/構造体で遊ぶ (#86)
513754c 2025-08-13 new/ひとくちメモ/github組織
09591d2 2025-08-12 書き終えた (#84)
2953f8f 2025-08-11 クリア後追記 (#83)
0dc1c8e 2025-08-11 Merge pull request #82 from tam1192:new/game/simulator/yknk
d873e04 2025-08-11 Merge branch 'main' into new/game/simulator/yknk
37d6e7e 2025-08-10 New/hitomemo/wine (#81)
08a3ec2 2025-08-09 可変変数の可変参照の項目を追加 (#80)
aa7816e 2025-08-09 alertの一部が正しい構文ではなかったため修正 (#79)
b1f40b1 2025-08-09 書きおわっった
aca0ad5 2025-08-09 強い怒りを書き終わった (#78)
f3d7e96 2025-08-08 書き終わった (#75)
ff44692 2025-08-07 書き終わった (#74)
168babb 2025-08-06 書き終わり (#73)
8ff012c 2025-08-06 fix/games/ba/nagituyo
5088b69 2025-08-05 end of content (#71)
7b1e0f3 2025-08-04 New/coding/crossterm (#70)
0a997fe 2025-08-03 Merge pull request #69 from tam1192:new/game/ba/nagituyo
b62cc66 2025-08-03 Merge branch 'main' into new/game/ba/nagituyo
cb76b75 2025-08-03 書き終わった
6f4d8a1 2025-08-03 games/baカテゴリ作成
141adce 2025-08-03 New/ひとくちメモ/おまえは存在しなかったをgitでやる方法 (#68)
6a59583 2025-08-03 新規ページ作成
75e5491 2025-08-03 gamesカテゴリを新規作成
83eb13f 2025-08-02 New/mc/paper/cmd-1 (#67)
ce66491 2025-08-01 New/server-nikki/openwrt/wireguard (#66)
c730d32 2025-08-01 New/book/ipの基礎知識 (#65)
(画像サイズ圧縮のため、git log main --pretty=format:"%h %ad %s" --date=shortの出力で許してね)
こんな感じで大体毎日投稿してました。
途中からコミットメッセージを固定にしたりしてます。
実際に増えた記事
- [プロフィール](./profile.md)
- [コーディング日記](./coding-nikki/Readme.md)
- [MyParserProject](./coding-nikki/my_parser_project/Readme.md)
- [手を動かしながら git を使う](./coding-nikki/手を動かしながらgitを使う/Readme.md)
- [Vue × WASM × Rust—試行錯誤とこれからの展望](./coding-nikki/Vue_×_WASM_×_Rust_試行錯誤とこれからの展望/Readme.md)
+ - [イケてる tui を作ってみる part1](./coding-nikki/crossterm/1/Readme.md)
+ - [イケてる tui を作ってみる part2](./coding-nikki/crossterm/2/Readme.md)
+ - [構造体で遊ぶ](./coding-nikki/fun_struct/Readme.md)
+ - [クレート紹介 part1](./coding-nikki/crate-introduce/1/Readme.md)
+ - [構文解析 part1](./coding-nikki/parser/1/Readme.md)
+ - [構文解析 part2](./coding-nikki/parser/2/Readme.md)
+- [Minecraft 系](./mc/Readme.md)
+ - [基礎編 part1](./mc/1/Readme.md)
+ - [基礎編 part2](./mc/2/Readme.md)
+ - [基礎編 part2+](./mc/2plus/Readme.md)
+ - [paper 編](./mc/paper/Readme.md)
- [paper 編 part1 コマンド補完](./mc/paper/1/Readme.md)
- [fabric 編](./mc/fabric/Readme.md)
- [fabric 編 part1 仕様が大きく変わっちまったぜ](./mc/fabric/1/Readme.md)
- [fabric 編 part2 とりまブロックを追加してみる](./mc/fabric/2/Readme.md)
- [テクスチャ編 part1](./mc/tx1/Readme.md)
- [RenderScale はいいぞ](./mc/RenderScaleはいいぞ/Readme.md)
- [サーバー系](./server-nikki/Readme.md)
- [Ceph-mon って何?](./server-nikki/ceph-monってなに?/Readme.md)
+ - [openwrt 同士で wireguard を張ってみる](./server-nikki/openwrt/wireguard/Readme.md)
- [自由記述型](./freewrite/Readme.md)
- [携帯電話はもはや電話じゃない](./freewrite/携帯電話はもはや電話じゃない/Readme.md)
- [スマホ投稿テスト](./freewrite/スマホ投稿テスト/Readme.md)
- [playground について](./freewrite/playgroundについて/Readme.md)
+ - [コミットしろよ](./freewrite/commit_must/1/Readme.md)
+ - [快活で作業してみた](./freewrite/kaikatu/Readme.md)
+ - ["tam1192"repo のルール変えました](./freewrite/tam1192_repo_2508/Readme.md)
+ - [究極の immutable を追え](./freewrite/究極のimmutableを追え/Readme.md)
+ - [新幹線で作業してみた](./freewrite/new_main_line/Readme.md)
+ - [関越道の工事が多くて草](./freewrite/kanetu/Readme.md)
+ - [練ればねれほど疲れる](./freewrite/long_sleep/Readme.md)
- [ひとくちメモ](./short-note/Readme.md)
- [rust で buffer を作る時は](./short-note/rustでbufferを作る時は/Readme.md)
- [ライフタイムを意識してコードを書く、その 1.rs](./short-note/ライフタイムを意識してコードを書く、その1.rs/Readme.md)
- [mac のパッケージについて](./short-note/macのパッケージについて/Readme.md)
- [(rust の)enum ってどうやって比較すんの](./short-note/enumってどうやって比較すんの/Readme.md)
- [(rust の)from トレイトについて](./short-note/rustのfromトレイトについて/Readme.md)
- [openwrt で ra を受け取る時に注意すること](./short-note/openwrt_ra/Readme.md)
+ - [git で誕生日をずらしてもらう方法](./short-note/gitで誕生日をずらしてもらう方法/Readme.md)
+ - [&mut 型と let mut の違い](./short-note/rust_mut_or_andmut/Readme.md)
+ - [mac の wine と、retina や d3d11 とかの話](./short-note/mac_wine/Readme.md)
+ - [Tailscale を使ってみた](./short-note/tailscale/Readme.md)
+ - [github で組織を形成する](./short-note/githubOrganizations/Readme.md)
+ - [リポジトリを作り直した件](./short-note/remake_repos/Readme.md)
+- [日記本](./book/Readme.md)
+ - [ネットワークってたぶんこんなもん](./book/networkって多分/Readme.md)
+ - [ネットワークってたぶんこんなもん part1](./book/networkって多分/1/Readme.md)
- [HTTP であそぼう](./book/httpであそぼう/Readme.md)
- [HTTP であそぼう part1](./book/httpであそぼう/1/Readme.md)
- [HTTP であそぼう part2](./book/httpであそぼう/2/Readme.md)
- [HTTP であそぼう part3](./book/httpであそぼう/3/Readme.md)
+ - [HTTP であそぼう part3.5](./book/httpであそぼう/3_5/Readme.md)
+- [games](./games/Readme.md)
+ - [simulator](./games/simulator/Readme.md)
+ - [焼肉シミュレーターやってみた](./games/simulator/yknk/Readme.md)
+ - [bluearchive](./games/bluearchive/Readme.md)
+ - [なぎちゃん強くしたら 400 位になったじゃんね ⭐︎](./games/bluearchive/nagituyo/Readme.md)
+ - [チャレンジミッション全クリを目指して](./games/bluearchive/hard/Readme.md)
+ - [4.5 周年](./games/bluearchive/45/Readme.md)
+ - [subnautica やってみた](./games/subnautica/Readme.md)
なぜやってみたの?
ニコニコ動画で毎日投稿している人がいるのは知ってました。すげぇなと思ってみてました。
動画は無理だけで記事だけならいけるんじゃね?って思ってやってみました。
大変だったところ
基本夏休みなので時間はたくさんあります。 しかし、途中でお盆やバイトなどのイベントもあり、この時に毎日投稿を途切らせない方法を考えてました。
一番無難な方法だと思うのですが、記事を貯めておくことでした。
記事は長くすると書くのに時間がかかるし、読むのにも時間がかかります。
少しずつ行ってますが、ひとくちメモなどに切り分けて行くといいのかもしれないです。
良かったこと
とりあえず毎日やることがあったのは良かった。
今後について
今後も適度に更新していきます。
必要と思ったら増やしていきます。
リポジトリ整理に使う git 操作
先日リポジトリ整理記念でこのサイトのページを一個更新しました。 参考になるかわからないですが、整理に使うコマンドでもビボって置こうかなと
note
ビボる: 今考えついた言葉。 備忘録を書く。 メモっておくとなんら変わらない。
warning
当記事では個人運用しているリポジトリに有用な情報を載せています。
複数人で管理するリポジトリについて、全く考慮してないことを注意してください。
今日のひとこと
ぷぺぺぽぴー聴き比べてたんだけど、2024 と 2014 の札幌記念が一番上手だとおもた。
そもそも金管吹こうと思ったことあるけど、あんまりうまく吹けなかった。 しかし、久々に sax 吹いたけど、音出たからびびった。
まだ吹けそう。
40mP さんの曲ひっさびさに聴いた気がする。
メインブランチを綺麗にしたい
即興で作ったリポジトリは基本的にメインブランチが汚いです。私の場合
メインブランチを綺麗にする方法ですが、rebaseを使うよりもorphanブランチで一つずつ作る方が安全でいいのではないだろうかと思いました。
orphan ブランチ
git checkout --orphan new_main
# first commit(init commit)を作っておく
git commit --allow-empty -m "init-commit"
この状態でコミットログをみると
* commit 5aa02c1fcbd01b6b2b2b9fbe8d4ce8274f31042e
init-commit
* commit b7df9b6137012e2a9dc986f506f78f0f21f85bfb
|
| next-commit3
|
* commit a735303da15fee2598b5bef5b3cab78db2ef8eb2
|
| next-commit2
|
* commit 6445f41b7fad4369e70fe74d59ab95d2dcb23b9d
|
| next-commit
|
* commit 9dd2d68c25ed16f037baa7d281963e36949e6732
init-commit
(コマンドはgit log --graph --all、出力から Auther と Date は抜いてます)
線が繋がっていないのでログが途切れている、別の次元にいる状態になります。
note
orphan で作ったブランチに移動した場合、全てのファイルが未追跡状態として残ります。
git clean -fdでリポジトリを綺麗にしてから、作業を始めましょう。
tip
愚かな共有です。 git clean -nfdしてて、消えないなと思ったから、手動でrmしてました。 -nは dryrun です。
消えるファイルがあって怖い場合は dry run をしたり、最悪バックアップするのもありだと思います。安全第一。ご安全に、ヨシ!
何をみてヨシとしたんですか?
新しいブランチでリベースする
新しいブランチでリベースを行うと、歴史が繋がります。
これは first-commitを空コミットに置き換える時に有用 です。
note
英語記事ですが、こちらが詳しいです。
How do I git rebase the first commit?
古いブランチから cherry-pick する
cherry-pick を行えば、古いブランチからコミットを持ってくることができます。
git cherry-pick 1b99fe
# 複数選択可能
git cherry-pick 1b99fe..295444
# --no-commit で、コミット編集もいける
git cherry-pick 1b99fe --no-commit
時間があれば、--no-commitでコミットを編集することもできます。
ステージングされた状態になるため。
--no-commitで複数のコミットをcherry-pickして、コミットを束ねることができます。
整理して思ったこと
warning
この章は それって私の感想ですよね? が含まれます。
整理してて思ったことは何個かあります。 まず、ブランチの使い方です。
マージ方法を考えましょう。
無駄なコミットを束ね、綺麗なコミットメッセージを残すことができるのがsquashマージとなります。
main ブランチはもちろんのこと、dev ブランチなどではコミットメッセージは綺麗な方がいいと思います。 後から見返して何やってたかわかるのが重要なので
「作業もっと分割できそうだな」って思ったらすかさずブランチを作り、squash マージで束ねていきましょう。
まとめすぎてはいけないけど、バラバラだとコミットメッセージ考えるのが大変。
rebase はやらないに越したことがない
ブランチ名
ブランチ名にも規則性をつけましょう。 feature ブランチ(機能追加)、setup ブランチ(プロジェクトの初期セットアップ)、modify ブランチ(調整)、fix ブランチ(修正)。 英語がいい、日本語がいいは正直関係ないと思います。 deepl 優秀だし。
大切なのは目的が定まってることです。 このブランチでどこまでやるか線引きするといいと思います。 そうすれば、最終的にはコミットメッセージがつけやすくなると思います。
note
関数名とか変数名とかも重要なのはこれだと思う。
何ができるのか(関数)、なんのためにあるのか(変数)、名前ではっきりさせたいよね。
まぁこれができたら苦労しないわけで
苦労して初めてわかることもあるので、「俺は日記のようはヘマはしない!」 なんて思わないで、 とにかく適当に管理するといいと思います。 この項目で書いてあるのは「やればわかる」だと思うので。
でも日記さんと同じヘマはしない方がいい。 結構レベル低いこと言ってるなと自覚してる
どうやってコミットを綺麗にするか
前の項目で~~長いお気持ち表明してましたが、~~コミット履歴を綺麗にする話をしました。 これについて、OSS のプロジェクトで使われているガイドラインなど参考にすると良いのかもしれません。
まとめ
地味な作業ほど重要であり、QoL をあげられると信じてる。
山道を走った
投稿日:2025/09/07
車で山道を走った というだけの記事。
本日のひとこと
ほぼ本日のひとことで構成されてる記事だけど。
脱出ゲーム The Hills 2 時間でクリアした脱出ゲーム。 とにかく建物が大きい。 脳が働いてなくて、でも時間ある時に脳トレ程度に良かった。
抜け道の山道に注意
山道の中でも、抜け道になってる山道はやっぱ大変だなと思う。後ろから山のように車が来るし、前もかなり早いし。
慣れてないので自分のペースで走りつつ、支障が出ない範囲で避けたり、コンビニに寄ったりして後ろから山のように来る人たちに抜いてもらうようにしました。
山の中の温泉っていいよね
私が行ったのは秘境地というわけではないけど、川沿いの温泉。
ご飯が美味しかったイメージ。 大きな道路沿いにある定番の銭湯でも目的は達成するけど、山の中にある温泉は、特に外があれば外に出れば、空気が綺麗だと思う。
サウナと水風呂
サウナ入った。 先日からの疲れが溜まってたらしくて途中で体調がやばく避難した。
とりあえず水分取り、休憩室で休んでた。
サウナよく入るけど、徐々に体が弱ってきた。悲しいね。
以上
日曜なので日曜っぽい日記です。
なんかサーバーに繋がらないんだけど! -> 原因は...
という日記並のゴミ記事です。
本日のひとこと
これ描くためだけにページ作っただろ
なんで繋がらなかったんだけど
コンセントが抜けてた
どうすればよかったか
抜けないように管理すべきだった。
AC100V の危険性をもっと強く自覚し、コンセントの配置を改善すべきだった。
warning
もし抜けかけていてまだ通電していた場合、感電リスク、火災リスクがあります
改善
コンセントの位置は変えられないので、壁からの出っ張りを防ぐために (安全に使える)L 字アダプタを嚙ます といった工夫をする
ひとくちメモ/Short notes
数行で終わる程度のメモを書いております。 内容もしょーもないのが多く、ケアレスミスとか、うっかりしてない限り見なくていい内容です。
rust で buffer を作る時は
スタック上
スタック上におくのが一番安定
#![allow(unused)] fn main() { let buf = [0u8; 10]; }
ヒープ上(Vec 使用時)
Vec など、ヒープにおくバッファーがほしい時は
#![allow(unused)] fn main() { let buf = vec![0u8; 10]; }
このように、0 であらかじめ埋めておくこと
NG 例 1 new を使ってしまう
new は容量も決めないし、0 埋めもしないので一番あかんやつ
#![allow(unused)] fn main() { let buf = Vec::new(); }
NG 例 2 with_capacity を使ってしまう
with_capacity で容量だけ決めておいて、初期化してないパターン
#![allow(unused)] fn main() { let buf = Vec::with_capacity(10); }
妙案例 イテレーターを使う
イテレーターで初期化することもできる。
#![allow(unused)] fn main() { let buf = (0..10).map(|_| 0).collect::<Vec<u8>>(); }
vec![]は初期値を clone するのに対して、こちらは map で一つずつ指定していく。
buf は u8 なので問題ないが、clone の動作が特殊な Rc,Arc を使う時はイテレーターを使用することになる。
詳しくは、こちらの記事を参照されたし
サイズ指定が必要な理由と 0 埋めが必要な理由
fn read(buf: &mut [u8]) { buf[0] = b'h'; buf[1] = b'l'; buf[2] = b'l'; buf[3] = b'o'; buf[4] = b'w'; buf[5] = b'\n'; } fn main() { let mut buf = Vec::new(); // 変更してみて。 // let mut buf = Vec::with_capacity(10); read(&mut buf); println!("{:?}", buf); }
これを実行すればわかる。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
mac のパッケージについて
mac のパッケージ管理が結構複雑だと感じたので書きました。
note
ある程度 unix などの知識があることを前提で書いてます。
あと備忘録というかメモなので、主観とかめっちゃ入ってます。
🎵 本日の一曲
そういえば大阪万博行きたいな。 関東民から見て大阪のイメージといえばやっぱ新快速ではないでしょうか。
街中を で飛ばす爽快感がいいですよね。
(多分そこ気にする人はあんまりいない。)
app ファイルについて
app ファイルは、dmg(仮想ディスクイメージ)をダウンロードしてきて、それを Application ディレクトリなどに展開しておけば ok です。
app ファイルは実はディレクトリで、必要なファイルがその中に収まってる。
それ以上操作しなくても、アプリケーションは起動する。 消す際は app ファイルを削除すればいいだけ。
ただ、削除時は見て欲しいファイルが 3 つある。
~/Library/Containers~/Library/Caches~/Library/Application\ Support
明らかに、削除するアプリケーションのやつだったら消していいと思う。容量食うだけやし。
pkg について
インストーラーでインストールするやつ。 今回これについてメモるために急遽書いた。
インストールしたファイルたちはpkgutilで管理可能な模様。
本題ではあるものの、ここではリンクのみに納める。 というのも私も理解しきってないから。
Snow Leopard の新コマンド「pkgutil」でパッケージを削除する
brew について
mac 版パッケージマネージャー。 apt や pacman に例えられるが、だいぶ違う。
ところで、パッケージマネージャとはなんだろうか。 パッケージという単位でソフトウェアやライブラリを管理するプログラムで、パッケージ依存やパッケージ更新などの管理を行う。 パッケージマネージャーは二(+1)種類に分けて考えることができる。
- システムファイルを直接いじるやつ
システムディレクトリで直接パッケージを管理するもの。
パッケージによっては削除するだけでOS が起動しなくなるなどのトラブルが付き纏う。- プラットフォーム固有
apt pacman dnfなど、デフォルトでインストールされてる奴ら - 共通
pipこれもシステムと密接に関係していることが多いのでこちらに分類。
- プラットフォーム固有
- 独立してるやつ
システムファイルとは独立したディレクトリでパッケージを管理するもの。
パッケージを削除しても直接システムには影響しないことが多い。
brew snap pip cargo sdkman! npmなど
brew はシステムファイルとは独立しており、最新版だと/opt/homebrewでパッケージを管理する。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
(rust の)enum ってどうやって比較すんの
初歩的な記事だなぁ?と思ったやってみろ!
🎵 本日の一曲
制服可不ちゃんかわいいね。
同位体メンバーの中でも特に有名なのが可不ちゃんだと思うけれど、可不ちゃんってセイシュン!って雰囲気があまりない気がします。
でも可不ちゃんとセイシュン!したかったなぁ(※決してやましい意味ではない)
enum で比較してみろよ!
え?これだけでしょ?
enum 同位体 { 可不, 星界, 裏命, 狐子, 羽累, } fn main() { println!("{}", 同位体::可不 == 同位体::可不); }
できた?できなかった?
derive でトレイトをつける
ああ、そうだ。 思い出した。
ユーザー定義型(struct/enum)は初期では一切のトレイトがついてないから、自分でつけないといけないんだったな
じゃあ、==演算子に対応するトレイトはなんだっけ...
PartialEqだな
#[derive(PartialEq)] enum 同位体 { 可不, 星界, 裏命, 狐子, 羽累, } fn main() { println!("{}", 同位体::可不 == 同位体::可不); }
よしできた。 てか、日本語も変数名に使えるんだな。(今更)
derive を展開して意味を説明して?って言われた
derive は確かに便利なマクロだが、たまに手動で実装したくなることもあるよな
じゃあ、手動で実装してみよう。
enum 同位体 { 可不, 星界, 裏命, 狐子, 羽累, } impl PartialEq for 同位体 { fn eq(&self, other: &Self) -> bool { self==other } } fn main() { println!("{}", 同位体::可不 == 同位体::可不); }
...なんかコードがオーバーフローしたぞ?
あそっか。 そもそもそのコードは再帰関数を含んでるもんな
enum 同位体 { 可不, 星界, 裏命, 狐子, 羽累, } impl PartialEq for 同位体 { fn eq(&self, other: &Self) -> bool { self.eq(other) // 再帰関数になってる } } fn main() { println!("{}", 同位体::可不 == 同位体::可不); }
...ん? NN? え、じゃあどうやって比較しろと?
enum を一意に比較する
discriminant という関数があるらしい。 これはenum の値を一意に識別できるようだ。
use std::mem; enum 同位体 { 可不, 星界, 裏命, 狐子, 羽累, } fn main() { println!("{:?}", mem::discriminant(&同位体::可不)); println!("{:?}", mem::discriminant(&同位体::星界)); println!("{:?}", mem::discriminant(&同位体::裏命)); println!("{:?}", mem::discriminant(&同位体::狐子)); println!("{:?}", mem::discriminant(&同位体::羽累)); }
これは比較可能なDiscriminantオブジェクトを返してくれる。 これで比較すれば良さそうだ。
enum 同位体 { 可不, 星界, 裏命, 狐子, 羽累, } impl PartialEq for 同位体 { fn eq(&self, other: &Self) -> bool { std::mem::discriminant(self) == std::mem::discriminant(other) } } fn main() { println!("{}", 同位体::可不 == 同位体::可不); }
できた!
std::mem の紹介
std::memは少し高度な用途で使う。 名前の通り、メモリ操作に特化している。
drop: 手動で変数を drop する
// 引用: https://doc.rust-lang.org/std/ops/trait.Drop.html struct HasDrop(i32); impl Drop for HasDrop { fn drop(&mut self) { println!("Dropping HasDrop {}!", self.0); } } fn main() { let x = HasDrop(0); let y = HasDrop(1); std::mem::drop(x); // xを手動で初期化する println!("hello"); }
swap: 内容を入れ替える
fn main() { let mut x = 10; let mut y = 20; println!("x: {}, y: {}", x, y); std::mem::swap(&mut x, &mut y); println!("x: {}, y: {}", x, y); }
単純な関数に見えてしまうが、この関数の存在は、ここでは書ききれないほど大きい。
まず、両方の型が同じであればどの型でも使用できる
note
pub const fn swap<T>(x: &mut T, y: &mut T) {
// SAFETY: `&mut` guarantees these are typed readable and writable
// as well as non-overlapping.
unsafe { intrinsics::typed_swap_nonoverlapping(x, y) }
}こいつはポインタを操作して入れ替える。 わざわざメモリを初期化しないので動作が早いのだ
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
(rust の)from トレイトについて
from トレイトについて書き綴ります。
🎵 本日の一曲
元気で可愛くて好き
From トレイトってなんだよ
From
From トレイトは、ある型に対し、別の型からその型を作る方法を定義できるようにするものです。そのため、複数の型の間で型変換を行うための非常にシンプルな仕組みを提供しています。標準ライブラリでは、基本データ型やよく使われる型に対して、このトレイトが多数実装されています。
from 以外だと、as というのが存在します。 これはキャストに近いやつですね。
from は自分が作った型(struct, enum)に対してキャストする手段を提供するものです。
トレイトにジェネリクスがあるという意味
from はトレイトにジェネリクスがついています。
impl From<&str> for MyStruct {
fn from(s: &str) {}
}
impl From<i32> for MyStruct {
fn from(s: i32) {}
}実装時は上記のように、ジェネリクスに型をぶち込みます。(i32, str など)
そうすると、from メソッドの引数の型がそれに合わせて変わります
型が違えば同じ型に From トレイトを複数適用可能です。
このような方法で、型によって処理の異なる、同名なメソッドを実装できます。
トレイトってすごいよね。
トレイトは、他言語でいうインターフェイスとよく例えるのですが、機能はそれ以上です。
あと、同時にジェネリクスも強いですよね。
以上
すまない! 毎日投稿を実現したくて急遽書いた! 内容が薄いから今度追記します...
openwrt で ra を受け取る時に注意すること
えぇ...と思った。
🎵 本日の一曲
7/31、8 周年だそうです。 ...もうそんなに経ったのか
ことの発端
IPv6 アドレスは、手動で受け取るより、ra などで受け取った方が楽だと思う。
多分固定アドレスだけど、固定じゃない場合を想定して、ね。
NTT 回線をご利用の場合は、電話なしだと ra での受信となる。有名なやつ
我が家は忌々しい、来る電話の 90%が詐欺かアンケートな電話を解約してしまったため、アドレスは ra での受け取りとなってます。
openwrt でアドレスを受け取ろうと思ったのですが、思うようにうまくいかなかったので備忘録として書きます。
環境
- 実機: fortigate 50e
- openwrt ver: Snapshot(OpenWrt SNAPSHOT r28931-90dee1ab30)
前提知識
openwrt で ra で prefix を受け取る時
RA でも DHCPv6 インターフェイスで行う必要がある。 が結論です。 しかも詳細設定で IPv6 プレフィックスの委任を有効化する必要があります
この手順を踏まないとアドレスがきませんでした。
FW の設定も注意
fw で設定する時、ICMPv6 を通すようにすることを忘れないようにしてください!!
また、インターフェイスにあるゾーンでは完璧に設定ができないので、必要に応じて手動でルールを追加してください!!
以上
もう 19 時過ぎててやばいやばい
git で誕生日をずらしてもらう方法
クリスマスに誕生日が被ると、プレゼントが一つになるそうです。
🎵 本日の一曲
音無あふさんと足立さんがより一層好きになった一曲
かわいい
やりたいこと
メインブランチ main と、作業中ブランチ work があり、work にてファイル A,B を新規作成している状態と仮定する。
work を main に marge する時、ファイル B の内容がブランチの趣旨とあまりにも差が開いているため、新たなブランチ work2 とし、marge することにした。
gitGraph
commit id:"first-commit"
branch work
checkout work
commit id:"change file a and b"
tip
この図を元に説明します。
説明のため、コミットメッセージをコミット id の代わりとして利用しています。
warning
この記事では、日記さん基本ぼっちだから積極的にgit push -fをします。
しかし、本来これは注意すべきコマンドです。 もし共同作業をしている場合はメンバーと調整しながらやるべきです。
warning
コピペはやめなさい。 コピペする前提でこの記事は書かれていません。
ちなみにクソ眠い中書いています。
rebase&reset をする
rebase -i <commit_id> で rebase をかける。
A,B が同じコミットchange file a and b で編集されていた。 これを切り離したい。
rebase -i first-commit
reset する
コミットが確定された状態になってるので、reset でステージング前に戻す。 vscode の gui 上で作業していたが、操作はコマンドラインのほうが安全だと思った。
tip
reset、rebase 時に指定するコミット id は一つ手前のコミットで
stash を活用してみる
初めて使ってみた。 git stash popというコマンドがあることから、スタックみたいな動作をしてるように感じた。
ステージング(git add .)して、スタッシュ(git stash add)とすると、ステージングされていた全てのファイルが一度消える。
git stash applyでファイルを戻すことができる。この状態でファイル b を削除し、通常通りの手順でコミットを行う。
その後、git stash popでファイル b を復元する。
[!TIP] >
git stash addの後ろに引数は不要
[!NOTE] >
popだとスタッシュから消えてしまうが、applyだとスタッシュに残り続けるらしい。
この手順を取った背景として、mdbook を使っており、SUMMARY.mdの内容をファイルの存在に合わせて変更をかけたかったから。
tip
つまり、ファイルを編集するようなことはなく、ステージング有無で調整できるならstash は不要
gitGraph
commit id:"first-commit"
branch work
checkout work
commit id:"change file a"
commit id:"change file b"
ブランチを新規作成
mainブランチに移動して、
git checkout -b work2 でブランチを作成します。
tip
あるコミットから分岐したい場合はgit checkout -b work2 <分岐する手前のcommit_id>で可能です。
gitGraph
commit id:"first-commit"
branch work
checkout work
commit id:"change file a"
commit id:"change file b"
branch work2
cherry-pick してみる
change file bをwork2に移動するために、cherry-pick を使用します。
work2ブランチに移動して、git cherry-pick change file bでコミットを持ってこれます。
gitGraph
commit id:"first-commit"
branch work
checkout work
commit id:"change file a"
commit id:"change file b"
checkout main
branch work2
checkout work2
commit id:"change file b2"
work ブランチから change file b コミットを削除する
git reset --hard change file bでコミットを削除しましょう。
gitGraph
commit id:"first-commit"
branch work
checkout work
commit id:"change file a"
checkout main
branch work2
checkout work2
commit id:"change file b2"
終わり
おわり
&mut 型と let mut の違い
ふと気になってしまったため
🎵 今日に一曲は、ひとくちメモでは廃止します
ストックする曲数が減ってしまったため、廃止します。
mut について
イミュータブルをミュータブルにするあれです。
let式にmutという語をつけると、値を束縛した変数がミュータブル(変更可能)となります。
&mut 型について
fn main() { // 生の値 let mut i = 32; println!("{}", i); // 可変参照の値 let m = &mut i; *m = 64; println!("{}", i); }
&mutは、可変参照であることを示す。 *は参照外し記号である。
*を&mutに用いると、その一瞬だけ、生の値が見えるようになる。
let m = &mut i; // mはiの可変参照
let x = *m; // xとiは別物になる別の変数で束縛すると、clone したという扱いとなり、別の値になってしまう。
let m = &mut i; // mはiの可変参照
*m = 64;ここでは、
i = 64と同義となる。
note
本来参照が不要なところで使用しているため。
参照が必要なところでこれを行うと、値を move してしまい、元のスコープで継続して使用できなくなってしまう
可変参照の制約
// 可変参照の値
let m = &mut i;
let n = &mut i; // mが無効になる
*m = 64; // mは無効なのでエラー可変参照は、言語の制約によって参照が一つまでに制限される。 よって、上記のように宣言するのは NG だし
#![allow(unused)] fn main() { // 可変参照の値 let m = &mut i; *m = 64; println!("{}", i); // mの参照がまだ残ってるので、新たに参照が作れない *m = 128; }
別の関数を呼び出すことによって、参照を無効化してしまう恐れもある。
コンパイラー曰く「m の参照が残ってるので新たに参照が作れない」となるらしい。
可変変数の可変参照
fn main() { let mut x:i32 = 0; let mut y:i32 = 0; let mut z:f64 = 0.0; let mut edit: &mut i32 = &mut x; *edit = 3; edit = &mut y; *edit = 6; edit = &mut z; *edit = 9.0; println!("x: {}, y: {}, z: {}", x, y, z); }
これが一番ややこしい例です。可変変数に可変参照を束縛しているという状態です。
edit 変数は i32 型の可変参照を持つため、x,y と参照を変えながら、各値を変えています。
しかし、z は f64 型なので、コンパイルエラーとなります。
fn main() { let mut x:i32 = 0; let mut y:i32 = 0; let mut edit: &mut i32 = &mut x; *edit = 3; edit = &mut y; *edit = 6; println!("x: {}, y: {}", x, y); }
z を取り除くと、コンパイルに成功します。
なお、こういうのもありということです。
fn main() { let mut x:i32 = 0; let mut y:i32 = 0; let edit: &mut i32 = &mut x; *edit = 3; let edit: &mut i32 = &mut y; *edit = 6; println!("x: {}, y: {}", x, y); }
edit が可変でなくとも参照が可変なので、値の変更が可能です。
とてもややこしい。
mac の wine と、retina や d3d11 とかの話
iPhone でゲームができるなら、Mac でもゲームができるんですねぇ。
warning
この記事では、wine 関係の情報と、RetinaMode 有効化について書いております。
wine 導入の話は暇だったら別記事で後日書きます。
なぜ mac でゲームをするか
理由はない。浪漫だ。
決して mac 切り替えと同時に windows 機の寿命が切れたわけではない
真面目な理由
ゲーム機を専用で用意するほどゲームをやるわけではないです。 しかし、forest とか raft とか、ああいった遭難系サバイバルゲームはやると面白いので、たまにやりたくなったわけです。
ゲーム機は steam にあるバカゲーいわゆるインディーゲーとかがあまりないですし、
(そもそも〇〇オンラインとかが高そう)
コーディングとか普段使いは mac の方がいいですし。
何より windows ゲーを windows 以外の OS で動作させてみたいという癖があるので、
こんなことしてます。
wine
windows アプリケーションを windows 以外の OS で動作させるには二通りの手段が思い付きます。
- 仮想化
バーチャルマシンとかいうやつ。
gpu 資源の共有が簡単にはできないので、どうしても仮想マシン側のグラフィック処理が劣る。(つまり重い)
そもそも OS が二つ動くから、メモリ二倍必要。
ただし、純粋な windows が動くため、トラブルが少ない。 - wine
変換レイヤーというやつ。仮想化ではない。
windows のアプリケーション、をあたかも unix(linux)アプリケーションとして動かすことができてしまう。
OS 側から見れば、純粋な unix(linux)アプリケーションなので、gpu 資源などの共有が簡単。(できるとは言ってない)
仮想化は、IOMMU やら SR-IOV などの発展によって gpu の資源問題は解決に近づいているらしい。
しかし、仮想マシンはどっちにしろ重い。wine は変換レイヤーに処理コストが多少かかるが、それでもマシ。
問題はDirectX
DirectX
グラフィック API の一つ。 windows 専用
linux だと OpenGL/Vulkan、Darwin(MacOS,IOS,IPadOS など) だと Metal。
これらの変換レイヤーが近年になって登場している。
proton: DirectX -> Vulkan
GPTK: DirectX -> Metal
mac には proton がない
登場しないかな。
上記の通り、proton は wine に加え、DirectX を Vulkan に変換するレイヤーDXVKを持っています。
互換性も向上している模様1
そのため、スムーズにゲームができると想像できます。(私はやったことない)
mac 非対応
対応してると思ってたんだよね。unix(darwin) だし。
linux と darwin は側が似てるだけで中身全然異なるんだよね
GPTK: Game Porting Toolkit
Apple シリコン上で Windows 実行可能ファイルを評価する
シェーダコードを Metal に変換する
と公式ページに書かれている通り、windows ゲームを変換する方法を提供してくれております。
この中にD3DMetalが含まれているそうです。
note
おそらくゲーム開発者向けの kit
MacOS 向けの開発をスムーズに始められるように
D3DMetal と wine の統合
これらを統合したアプリケーションは、確認した中で複数存在しました。
特に、Kegworksは、さまざまな wine のバージョンを試せるため、おすすめ。
corssover という選択肢もあるけれど、普通に高い。
tip
DXMTは D3DMetal と異なり、オープンソースで似たようなことを行うプロジェクト
Retina に対応させる。
せっかく綺麗なディスプレイを搭載してるので(Macbook 系は)、
Retina にも対応させましょう。
wine 付属の regedit で
HKEY_CURRENT_USER\Software\Wine\Mac Driver
この中に、文字列値を追加
値の名前:
RetinaMode
データ:
Y
tip
なければキーを追加してくだされ
これで wine を再起動すると、Retina 対応になります。(解像度が mac のディスプレイと同じになる)
wine 設定(winecfg)の画面設定から DPI を上げておくことを推奨します。
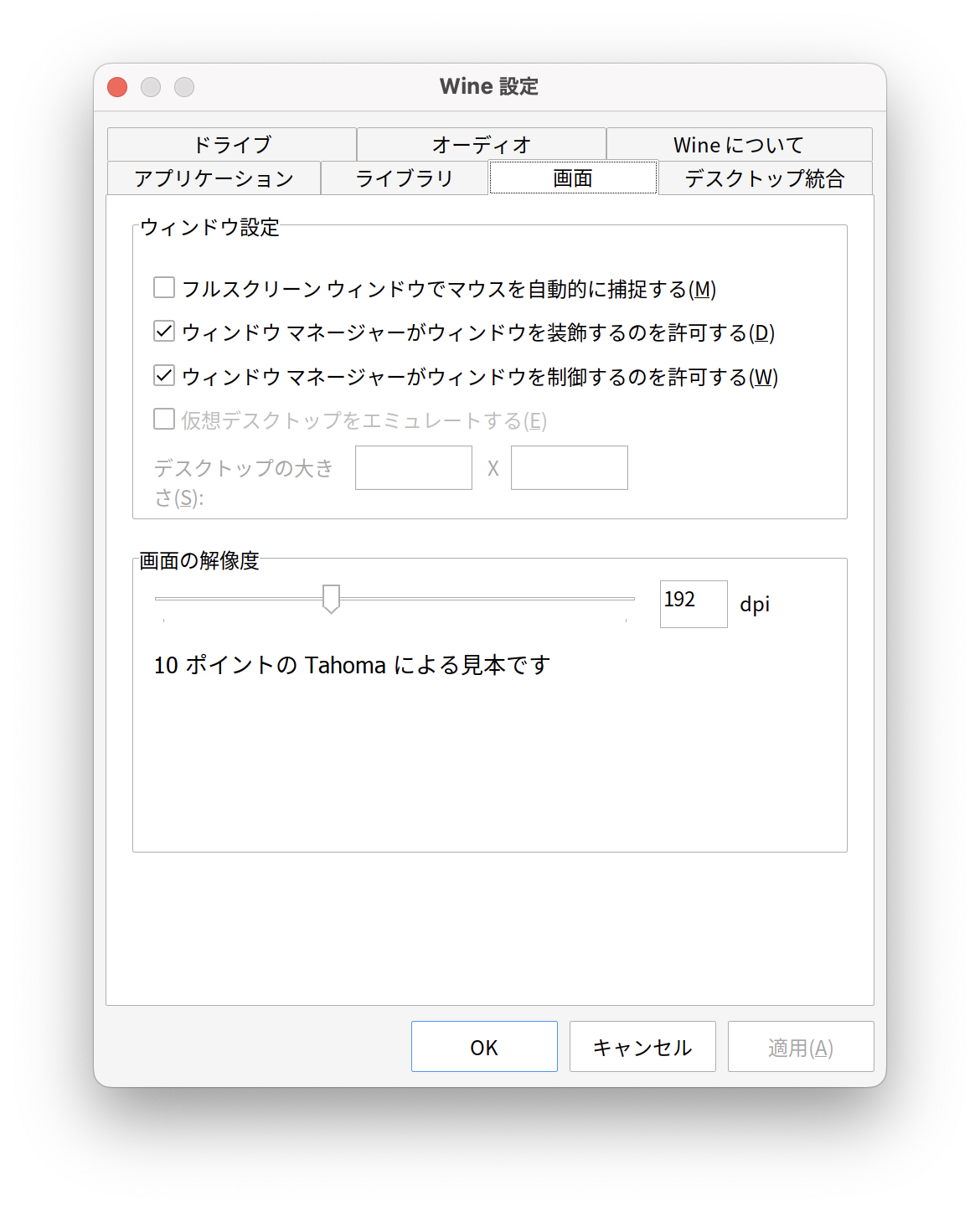
tip
日本語化する際のフォントですが、fakejapanese 系のやつが結構豆腐を消してくれるイメージがあります。
参考
Tailscale を使ってみた
便利の一言。
warning
この記事ではインストール方法、具体的な使用方法を記載していません!!
Tailscale ってなんや?
いわゆる VPN ってやつです。
---
config:
theme: redux
---
flowchart RL
subgraph cs["Client Side"]
app["App<br>ex: safari edge"]
cvpn["VpnApp"]
end
subgraph vs["Server Side"]
sapp["App<br>ex: nginx mysql"]
end
svpn["VpnServer"] == Vpn Tunnel === cvpn
sapp -- Internet --- svpn
cvpn -- LAN<br>Host Router --- app
原理はともかく、トンネルと呼ばれる仮想専用線で、ある部分(上の図だと「VpnServer」)まで直接データをやりとりするやつです。
トンネルにはオプションで暗号化を施すことができ、上の図だと「VpnApp」から「VpnServer」の間まで暗号化されます。
note
Tailscale などの最新 VPN は標準で暗号化され、無効化できません。
VPN のメリット
- 専用線より安い
そもそも専用線とは、自社や NTT のダークファイバーなどを用いて、拠点間を直接結ぶものが一つ挙げられます。
外部と接しないためにセキュリティーが高いというメリットがあります。1
しかし、維持費が高い。
VPN は暗号化処理を施すことで、専用線同等のセキュリティを確保できます。 - 内部ネットワークを繋げられる
専用線のメリットではありますが、内部専用のネットワークを繋げられます。
通常の通信の場合は、サーバーごとにグローバル IP アドレスの取得が不可避ですが、内部ネットワークであればプライベート IP アドレスで通信することができます。
warning
VPN のセキュリティは、暗号化処理によって変わります。
日記さんは、SSH や HTTPS で使われる OpenSSL を用いるwireguard、openvpnなどは安全だとよく耳にします。
tip
プライベート IP の枯渇という別の問題は一旦目を逸らすこととする
VPN のデメリット
- 侵入経路の糸口に繋がる
これが非常に厄介。内部ネットワークは**信頼のもと成り立つことが多いので、**一度侵入されると回復が非常に困難です。
侵入経路は簡単に、2 パターンあります- 認証基盤が脆い
VPN には暗号化に加えてユーザー認証があります。 ログイン処理。
このおかげで 内部と直接つながる VPN への侵入を防げるのですが、 脆いと侵入されるのは簡単に想像できますよね。 - 外からきたひとが勝手に VPN を使い、そこから侵入
内部ネットワークへつながるトンネルを勝手に作ることになるので、VPN の使用を禁じる組織は多いそうです。
- 認証基盤が脆い
- トラブルが連鎖する
専用線同様のリスクとして、一つの拠点が陥落すると、複数の拠点が同時に陥落するという問題があります。
内部ネットワークを繋げるというのは、拠点を繋げることと同じで、守るべき部分が増えてしまいます。 - ラグくなる
通信暗号化処理を挟むので、通信速度が落ちます。ping 悪化します。
note
VPN の使用を禁じるのは難しい。
最近の VPN だと、HTTPS などと同様な通信にしか見えないという特性を持ちます。2 これは、OpenSSL が IP とポート番号を除いたほどんどの情報を暗号化してしまうからです。(OSI レイヤーだと L5 以降。 IPSec なら L3 以降、つまりポートも隠れる)
結果的に VPN の通信をブロックすることが難しいです。 もはや利用者の良心に頼るしかない
Tailscale の凄さ
Tailscale は色々と強いです。
- NAT 問題を回避できる
プライベート IP アドレスは NAT によって変換されてしまうため、外部から直接通信ができないです。
Tailscale は、ゲーム機などで用いられてる技術を VPN に応用し、このトラブルに対処します。3 - (ほとんどの場合は)P2P で通信できる
クライアント間で VPN を繋ぐことができます。 サーバーよりも物理的距離が縮まり、早くなるケースがあります。4 - 必要な通信のみを VPN に通すことができる
個人的にはこれが熱い。 対外部通信は外部へ、対内部通信は VPN を通すと言ったことができます。
設定例とか
-
内部 DNS を設定する
PC の名前を変えれば ok。- windows
- macOS/IOS/iPadOS 等: 設定/一般/情報/名前 で変更可能
- Linux など: /etc/hostname などで変更可能
例えば、adwpc と名付ければ、同じ tailscale に所属するもの同士、adwpc とアドレスを入力すれば通信できます。
-
exitnode を設定する
一般的な VPN と同じように動作するものです。- 使われる側
tailscale set --advertise-exit-node=true
tailscale up --advertise-exit-node=true
ただし、linux ではnet.ipv4.ip_forwardを有効化しないとダメらしい
admin consoleで exitnode の有効化も必要5 - 使う側
windows や mac、iOS などではExitNode を選択可能。選択できるのは使われる側の設定を全て行った時
- 使われる側
-
特定 IP の広告
tailscale は標準では内部ネットワーク(LAN)を晒さない。晒すのはあくまで自分の端末のみ。
IP を晒したいなら、--advertise-routes xxx.xxx.xxx.xxx/nnと設定すれば、晒せる。
note
Firewall の設定は、大抵の場合自動で行ってくれます。
tailscale あるある
あるあるネタです。
-
プライベート IP アドレスが使えない!!
大抵は--accept-routes, --exit-nodeが true の時です。 これは上記 exitnode と、特定 IP の広告を受け入れてる時です。
IP が被ったりして、通信ができなくなることがあります。 -
通信ができない!! tailscale の ACL 関係の問題や、ライセンス的な問題のことが多いと思います。
後者ですが、tailscale は課金ありなので、ライセンスも確認してください。
終わり
便利だね。
参考・補足
参考
補足
ここでのセキュリティとは、盗聴リスクの低減、外部からの侵入によるウイルス注入、情報漏洩など
主に NGN 網内折り返しの通信の場合。 nuro であっても、nuro 使用者同士であれば早くなる模様。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
github で組織を形成する
github Organizations の作り方メモ
1: https://github.com/settings/organizationsにアクセスする
Organizations 一覧が表示されます。
ユーザーアイコン/Settings/Access.Organizations からでもアクセス可
2: New Organizations で作成
料金選択が出てきます。 いつか比較したい。
名前、代表メアド、ロボ確します。
note
Addon にある github copilot はオプションです。 有能だけど高いから注意。
できること
複数人で git を使って作業する時はほしいやつ。
リポジトリを作り直した件
公開日:2025/08/24
適当にリポジトリを作るのはよくない。
経緯
http であそぼうは、リポジトリよりも先に本を書いており、コード自体も一時プロジェクトとして tmp で作成してました。
ところが、当初の目的と反して記事的にもプロジェクト的にも大きくなったので、急遽リポジトリの作成をしました。
first-commit として、できてたコードをそのまま上げてしまったので、のちに後悔しましたとさ。
ブランチきれないじゃん!
http であそぼうでは、クレートを試験するために別のプロジェクトとして httparse、reqwest を試そうとしました。
- ex/reqwest ブランチ
- ex/httparse ブランチ
first-commit が空であれば、そこから分岐して終わりだった。
ところが first-commit が埋まってたのでブランチ初めのコミットが「既存ファイル削除」となってしまったのですね。
note
ちなみに、全く別のリポジトリにしなかったのは、リンク誘導が楽だからとか、リポジトリ名考えるのがめんどかったからです。
note
いつも通りぼっち保守リポジトリであるので、rebase による副作用は考えなかったです。
また、issue などの機能には手をつけてなかったので、最悪リポジトリ削除という選択肢もあり得てます。(てか結論そうした)
first-commit を分離する -> 失敗した
仕方なくgit rebase -i --rootで first-commit を分離しようとしました。
git reset
git reset
git reset --mixed
...
reset されねぇ!
reset って手前のコミットの状態に戻すコマンドだと思うのですが、手前のコミットが存在しないので不可能なのです。
update-ref する
qiita曰く、update-refを行えば近いことができる模様。
そう思ってました。
rebase に失敗した
rebase に失敗しました。
正しくは過去のコミットの削除に失敗しました
rebase ってコミットを修正後、新しく作り直す(一番後ろに修正後のコミットを追加、のちに修正前のコミットを削除)するのですが、追加されたのちに削除できずエラーとなりました。
update-ref が絡んでそうなエラーが出てましたね。
結局リポジトリ削除
結局リポジトリを削除して、必要な履歴を cherry-pick で引っこ抜いてきました。
まとめ
せめて first-commit は空、もしくは Readme オンリーにしようと思いました。
今回の用途は特殊すぎるけど、普通に rebase する時も大変そうだったので。
wipコミットをしてみた
名前通りです
WIPとは
Work In Progressという意味です。
要はまだ途中だよ!っていってます。
WIPコミット?
コミットの先頭に[WIP]をつけるだけです。
pushしないよう注意しながら運用します。
完成したら
WIPを外し、amendでコミットに差分を追加します.
まとめ
途中で作業を止める時には便利かも?
zsh使いやすくした 1回目
コマンド入力めんどい
本日の一言
ナマステト / 重音テトSVという曲を見つけてしまい、思わずクリックしてしまった。
aliasで使いやすくする
zshって結構カスタマイズしたいことがあって、.zshrcを編集します。
vi ~/.zshrc source ~/.zshrc 別に普通に入力すればいいだけなんですが、めんどかったので前者をvrc、後者をsrcに短縮します。
(~/.zshrcの先頭あたり)
# EDITOR環境変数を設定してます
export EDITOR="/usr/bin/vi"
alias vrc="$EDITOR ~/.zshrc"
alias src="source ~/.zshrc"
source ~/.zshrcで完成。 次回以降はvrcとsrcが使用可能になります。
頻繁に使うディレクトリのショートカットを作る
aliasでやってもいいですが、zshの機能でもっと簡単にできました。
hash -d <ショートカット名>=<ディレクトリ>というのがあり、これは~<ショートカット名となります。
ディレクトリで使用可能となり、cdコマンドの入力が楽になります。
hash -d t=/tmp は cd ~tとなります。~tだけでも飛べます。
(zshでは、cdコマンドは省略ができる)
vrc
# EDITOR環境変数を設定してます
export EDITOR="/usr/bin/vi"
alias vrc="$EDITOR ~/.zshrc"
alias src="source ~/.zshrc"
# hashを追加
hash -d t=/tmp
srcコマンドで適用すればok
まとめ
これでキー入力スピード勝負を持ち込まれた時に自信持って負けられます。
...🤔
pid1 に割り込む奴
お久しぶりです。
本日の一言
だいぶ涼しくなりましたね。私は冬の方が好きです。
こういう光景も冬ならではですよね。
最近、「イラスト統一祭」っていう面白い祭りやってました。 その中で神曲見つけました。
pid1 に割り込みたくなる時もある
とはどういうことか。
Docker では、PID1 プロセスの標準出力をそのままログとして保存する仕組みがあります。
しかし、PID1 以外のソフトウェア(例えば pid1 がシェルスクリプトであり、スクリプト中に本来必要なプログラムを動作させる時)のログを残すにはどうすれば良いでしょうか
proc を使う
/procは仮想的なファイルです。実在しません。
proc は linux 特有の仕組みです。proc ディレクトリの中にある数字のディレクトリは、pid となっています。
中身にあるもの: environ
environ というファイルには、環境変数が表示されます。
環境変数にパスワード設定すると、ルートユーザーから容易にバレるわけです。まぁルートユーザーなんでね。
中身にあるもの: fd
fd というディレクトリですが、正式名称はファイルディスクリプターというそうです。
中を開くとこれまた数字のディレクトリがたくさんあります。
ファイルディスクリプター
よく、0 は標準入力、1 は標準出力、2 はエラー出力などと聞きます。 ディレクトリの数字はそれです。
しかし、実際のソフトウェアではその常識は通用しません。
l-wx------ 1 www-data www-data 64 Sep 23 17:20 2 -> /var/log/nginx/error.log
l-wx------ 1 www-data www-data 64 Sep 23 17:20 3 -> /var/log/nginx/error.log
l-wx------ 1 www-data www-data 64 Sep 23 17:20 4 -> /var/log/nginx/access.log
nginx だと、2 が error.log へ、4 は access.log へと、自由に設定できます。
docker のロガー
docker のロガーは、pid1 の fd1 をログとして残すそうです。
まとめ
コンテナ内で
echo hello > /proc/1/fd/1
とすれば、docker のログにhelloという文字列が残る
日記本
mdbook 使ってるのに本がないとはなんだと思ったため。
ネットワークってたぶんこんなもん
ネットワークって多分こんなもん。 ふわふわな知識を披露晒しあげる本です。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
特に当シリーズは日記さんのふわっとした知識だけで書くシリーズなので、ご指摘本気でお待ちしております 💦
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
ネットワークってたぶんこんなもん part1
IP の基礎的な部分です。 ちなみに資料はほとんど使い回し。
🎵 本日の一曲
ぎたーそろすきー
ネットワークってなんだろう
死ぬほどいろんなもので例えて説明するせいで、真面目に説明したことない。
真面目に説明する
真面目じゃない説明はあと回し
ネットワークは、網状に作られたもの1を指す。
その一つにコンピューターネットワークがある。これ以降ネットワークとは、コンピューターネットワークを指すこととする。
ネットワーク技術は、複数のコンピューター間を接続する技術のことである。
コンピューターとは PC やスマートフォンはもちろんこと、ルーターやスイッチ、テレビ、近年では洗濯機や冷蔵庫なども該当する。
ここでは、計算ができる、データ処理ができることに加え、ネットワークに参加できる機器をコンピュータもしくはノードと呼ぶ。
LAN
家庭内や会社内といった 単独の組織内で用いられるネットワークを Local Area Network(LAN) と呼ぶ。
私有ネットワークでもあり、ほとんどの初学者は LAN を中心に触れ、学ぶことになる。
この本も、主に LAN についての解説を中心に行う。
WAN
LAN の対義語として機能する。 異なる組織間をつなげたり、異なる国間をつなげる際に用いられるネットワークを Wide Area Network(WAN)と呼ぶ。 ISP などと呼ばれる回線事業者が管理するネットワークである。
通信技術
コンピューターは、メーカーによって異なるアーキテクチャ、設計思想で製造されており、ひとえに共通化が難しいものである。 Apple 社の mac シリーズは、過去に二度もアーキテクチャを変更したが、互換性を保つために Rosseta というプログラムを用意してきた。
互換性とは、プログラムが異なるシステムで、異なるアーキテクチャのハードウェアを用いても動作することを言う。
互換性を意識しないプログラムは、システムやハードウェアが限定されてしまうこととなる。つまり、利便性が損なわれてしまうことになる。
しかし、多くのコンピューターに対応させることは、その分の開発リソースを割かなければならず、結果的に開発費が増えてしまう。
tip
システムやハードウェアも互換性は重要である。 Rosseta のように、メーカーが直にシステムの互換性を持たせることによって、
システムやハードウェアの価値を高めることにつながる。
ネットワークに置いても重要な問題であり、通信方式に互換性がなければ、異なるメーカのハードウェア間では通信できない恐れがある。
通信においては、通信プログラムが互換性を持つのではなく、通信プロトコルによって全てのメーカ・ハードウェアに共通化を促している。
情報通信におけるプロトコルは、議定書のように書類で管理される。
ほどんどのプロトコルは、ハードウェアのプロトコルは ISO や IEEE、ソフトウェアのプロトコルは RFC によって管理されている。
note
議定書は protocol の和訳。 他には仕様、規定など2
ネットワークって多分こんなもん part1
真面目に解説して疲れたので以下適当に知ってること書きます。
IPv6
次世代の Internet Protocol。 これに置き換えようと色々頑張ってる。
IPv4 の 4 倍の長さを持つアドレス(32bit -> 128bit)
アドレスが長く割り当てずらい欠点を克服するために、RA と DHCPv6 という仕組みが存在してる。
prefix と suffix
IPv6 アドレスは、IPv4 アドレスと同じく、ルーティングに使われる。
このルーティングというのは、アドレスの左から右にかけて、細かくなっていく
似たようなものとして郵便番号がある。 郵便番号も、左から右にかけて情報が細かくなる
IP アドレスの最後に/で区切り、v4 なら 0-32、v6 なら 0-128 の間の数字をつける表記がある。
これは、先頭からの bit 数を示してる この bit 数で、アドレスの前半、後半を分けて考えることができる。
tip
v4 はサブネットマスクという表記法もあるが、本質的に一緒なので省略。
例えば、
1 つ目、192.168.1.0/16という表記の v4 アドレスがあるとすれば、
192.1681.0
と分けることができる。
2 つ目、192.168.2.0/16という表記の v4 アドレスがあるとすれば、
192.1682.0
と分けることができる。
3 つ目、10.0.2.0/16という表記の v4 アドレスがあるとすれば、
10.02.0
と分けることができる。
このうち、左側が一致していれば、同じグループのネットワークに所属していると見なすことができる。
つまり、1 つ目と 2 つ目は同じネットワークに所属してる。
一方、右側が一致していても、同じグループとはみなせない
つまり、1 つ目と 3 つ目はもちろん、2 つ目と 3 つ目も同じグループではない
今まで/16でやってきたけど、次に見慣れた/24に変える。 1 つ目と 2 つ目を比較しよう
| 表記 | 前半 | 後半 |
|---|---|---|
192.168.1.0 | 192.168.1 | 0 |
192.168.2.0 | 192.168.2 | 0 |
bit 数を増やすと、1 つ目と 2 つ目が別のグループになってしまった。
言い方を変えると、もっと細かくみたということになる。大雑把、外から見れば 1 つめも 2 つめも同じグループだったが、
詳細に、内から見れば 1 つめと 2 つめは違うグループとなる
実際のルーティングも、外になるほど大雑把にルーティングし、内になるほど細かくルーティングする
参考
wikipedia
HTTP であそぼう
HTTP を理解しつつ、HTTP サーバーを地道に作ります。
基礎知識
rust について
この記事では rust を主に取り扱います。 しかし説明は不要です。 というのもこのページを見る人が rust を知らないわけがないです。
http について
この記事では http を主に取り扱います。 しかし説明は不要(ry) 決してめんどくさいわけではありません。
markdown って HTTP 色付けできるんだぁ
GET / HTTP/1.1
Content-Type: text/html; charset=utf-8;
<!DOCTYPE html>
<html>
<head>
<title>こんにちは</title>
</head>
<body>
<h1>こんにちは</h1>
<p>私は日記と申します。</p>
</body>
</html>
discord だと HTML 部分も色付けされてた記憶があるので、mdbook は対応していると思ったのですが... まぁこれでも十分です。
この記事のメインコンテンツについて
rust 関係の話題より HTTP 系の話題の方がメインです。 rust 関係はこの後死ぬほど追求できるので。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
作ったコードを置いてます
githubにて作ってきたコードをまとめたものを置いてます。
よかったら参考に...できるかな
HTTP であそぼう part1 (★★☆)
作業しながら備忘録として書いてるので、基本内容は適当、思いつきです。 参考にしないでね。
本日の 1 曲 🎶
自分がこの記事を書いた時代がわかるように、これから本日の一曲という項目を書いていきます。唐突に追加しました。 今最も聞いてる曲で選曲してます。
PV の立花ちゃんがかわいいね。
★ について (★★★)
★ はこの記事の中でとりあえず読んで欲しいところに 3、自分用のメモレベルで 1 をつけてます。
なので、★1 の内容が理解できなくても問題ないです! 書いてるやつが悪い。
一方 ★3 は頑張って書きましたので読んで欲しいな〜
本題 (★★★)
とりあえずサッと書いてみた。 (★☆☆)
use std::{
collections::HashMap,
fmt::Display,
io::{Read, Write},
net::{IpAddr, SocketAddr, TcpListener},
sync::{Arc, Mutex, mpsc::channel},
thread,
};
mod route;
fn main() {
let listener = TcpListener::bind("0.0.0.0:80").unwrap();
loop {
if let Ok(data) = listener.accept() {
let (stream, addr) = data;
let mut stream = stream;
// read data
let (buf, _) = {
let mut buf = [0u8; 1024];
match stream.read(&mut buf) {
Ok(size) => (buf, size),
Err(err) => {
eprintln!("{}", err);
return;
}
}
};
let data = String::from_utf8_lossy(&buf);
let mut lines = data.lines();
let (method, path, _) = {
// GET / HTTP/1.1
let line = lines.next().unwrap(); // first Line
let mut parts = line.split_whitespace();
// parse method
let method = HttpMethod::from(parts.next().unwrap_or(""));
// parse path
let path = HttpPath::from(parts.next().unwrap_or(""));
// parse version
let version = parts.next().unwrap_or("");
(method, path, version)
};
let headers = {
let mut header = HashMap::<&str, &str>::new();
// parse headers
loop {
if let Some(line) = lines.next() {
let mut parts =
line.split(':').map(|s| s.trim()).filter(|s| !s.is_empty());
let key = match parts.next() {
Some(k) => k,
None => break, // no more headers
};
let value = match parts.next() {
Some(v) => v,
None => break, // no more headers
};
if parts.next() != None {
break;
}
header.insert(key, value);
} else {
break;
}
}
header
};
let _ = stream.flush();
}
}
}
#[derive(Debug, Clone, PartialEq, Eq)]
enum HttpMethod {
Get,
Post,
Put,
Delete,
}
impl Display for HttpMethod {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
match self {
HttpMethod::Get => write!(f, "GET"),
HttpMethod::Post => write!(f, "POST"),
HttpMethod::Put => write!(f, "PUT"),
HttpMethod::Delete => write!(f, "DELETE"),
}
}
}
impl HttpMethod {
fn from_str(s: &str) -> Option<Self> {
match s.to_lowercase().as_str() {
"get" => Some(HttpMethod::Get),
"post" => Some(HttpMethod::Post),
"put" => Some(HttpMethod::Put),
"delete" => Some(HttpMethod::Delete),
_ => None,
}
}
}
impl From<&str> for HttpMethod {
fn from(s: &str) -> Self {
HttpMethod::from_str(s).unwrap_or(HttpMethod::Get)
}
}
#[derive(Debug, Clone, PartialEq, Eq)]
struct HttpPath<'a>(&'a str);
impl<'a> HttpPath<'a> {
fn from_str(s: &'a str) -> Option<Self> {
let mut c = s.chars();
// Check if the first character is a slash
if c.next() != Some('/') {
return None;
}
// 許可文字以外を検知したらNoneを返す
// findの戻り値=Noneなら許可文字のみ
if c.find(|c| !(c.is_ascii_alphanumeric() || *c == '/' || *c == '-' || *c == '_')) == None {
Some(HttpPath(s))
} else {
None
}
}
}
impl<'a> From<&'a str> for HttpPath<'a> {
fn from(s: &'a str) -> Self {
HttpPath::from_str(s).unwrap_or(HttpPath("/"))
}
}書いてて思ったのですが、AI ってすげぇやAI 保管ウゼェ!!
いや、ほんとこれ大量に処理リソース食う=お金かかるのにこれいうのはまじで申し訳ないんですが、慣れるまでの間は大変です。
自分が想定している以上のコードまで書いてくれて、私が置いてきぼりになる。
機長置いていかないでもろて... アンチアイスオフにしないでよね
とはいえ普通に便利です。
warning
このコード深夜テンションで一気に書いてしかも動作テストしてないクソコードなので期待しないでください
HTTP ヘッダーの形について (★★★)
nc コマンドで取得してみると...
nc -l 80
curl http://localhost/
この結果(nc 側に表示される)は次のとおり
GET / HTTP/1.1
Host: localhost
User-Agent: curl/8.7.1
Accept: */*
一方、MDN などで調べると返信はこんな感じになります。
HTTP/1.1 200 Ok
Content-Type: text/html; charset: utf-8;
<!DOCTYPE html>
<html>
<head>
<title>hello world</title>
</head>
<body>
<h1>hello world</h1>
</body>
</html>
これを撃ち返してやれば
hello world
というサイトが表示されるでしょう
ちなみに、nc は出力以外にも入力に対応しているので、リクエスト(GET / HTTP/1.1)と届いたら、それを返すだけでページを返せます。
note
全て書き終わったら、^c もしくは^d で nc を一度終了させて、送信させます。 いかない場合もあるかも。
HTTP ヘッダー関係を構造体にしてしまおう (★★☆)
上記コードを少し変えて、しっかり構造体にしちましょう。
---
config:
class:
hideEmptyMembersBox: true
---
classDiagram
direction TB
class HttpRequest {
HttpMethod method
HttpPath path
HttpVersion version
HashMap header
Vec body
}
class HttpPath {
}
class HttpMethod {
GET
POST
DELETE
PUT
}
class HttpVersion {
Http10
Http11
Http20
Http30
}
HttpPath --* HttpRequest
HttpMethod --* HttpRequest
HttpVersion --* HttpRequest
この形にするのが無難かな?
path
Path は関連 RFCによると
unreserved = ALPHA / DIGIT / "-" / "." / "_" / "~"
が使えるらしいです。 ALPHA は a-z と A-Z、DIGIT は 0-9 です。 つまり、new 時点でこの文字でしか作れないように制約をつけましょう。
use std::fmt; #[derive(Debug, Clone, PartialEq, Eq)] struct HttpPath<'a>(&'a str); impl<'a> HttpPath<'a> { // 許可された文字列のみで作る fn from_str(s: &'a str) -> Option<Self> { // 文字単位に分解します let mut c = s.chars(); // 先頭は/になると見込んで if c.next() != Some('/') { return None; } // findメソッドで許可されていない文字があるか検索しましょう // なかったら成功です。 if c.find(|c| { // a-zA-Z0-9/\-_以外を探す !(c.is_ascii_alphanumeric() || *c == '/' || *c == '-' || *c == '_') }) == None { Some(HttpPath(s)) } else { None } } } // Fromトレイトもつけて、文字列から簡単に変換できるようにしましょう impl<'a> From<&'a str> for HttpPath<'a> { fn from(s: &'a str) -> Self { HttpPath::from_str(s).unwrap_or(HttpPath("/")) // デフォルト値は / } } // 文字列で取得できるように、Displayを実装しておきましょう impl<'a> fmt::Display for HttpPath<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", self.0) } } fn main() { // 検証してみよう assert_eq!(HttpPath::from("/").to_string(), "/".to_string()); assert_eq!(HttpPath::from("/aaa/bbb/ccc").to_string(), "/aaa/bbb/ccc".to_string()); assert_eq!(HttpPath::from("").to_string(), "/".to_string()); assert_eq!(HttpPath::from("こんにちは!").to_string(), "/".to_string()); println!("all success! 成功!"); }
コード的には最初の難関。 文字に分解して find で not 検索を行うからね。
頭捻らないと出てこない。日記さんは他のところでパーサーやってたので感覚的にはわかるけど。
method
調べるのがめんどかったので、主要四つにしましょう。
GET
POST
DELETE
PUT
これを扱える enum を作れば良いです。 文字列でも生成可能にしましょう。
use std::fmt; #[derive(Debug, Clone, PartialEq, Eq)] enum HttpMethod { Get, Post, Put, Delete, } impl HttpMethod { fn from_str(s: &str) -> Option<Self> { // 大文字/小文字を考慮しない。(小文字に統一) match s.to_lowercase().as_str() { "get" => Some(HttpMethod::Get), "post" => Some(HttpMethod::Post), "put" => Some(HttpMethod::Put), "delete" => Some(HttpMethod::Delete), _ => None, } } } impl From<&str> for HttpMethod { fn from(s: &str) -> Self { HttpMethod::from_str(s).unwrap_or(HttpMethod::Get) } } // 文字列で取得できるように、Displayを実装しておきましょう impl fmt::Display for HttpMethod { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", match self { Self::Get => "GET", Self::Post => "POST", Self::Put => "PUT", Self::Delete => "DELETE", }) } } fn main() { // 検証してみよう assert_eq!(HttpMethod::from("get").to_string(), "GET".to_string()); assert_eq!(HttpMethod::from("post"), HttpMethod::Post); assert_eq!(HttpMethod::from("put"), HttpMethod::Put); assert_eq!(HttpMethod::from("delete"), HttpMethod::Delete); assert_eq!(HttpMethod::from(""), HttpMethod::Get); println!("all success! 成功!"); }
version
簡易的に作る時は無視するところですね。
これも基本的には enum で ok。 TLS/SSL と違って更新頻度が低いので、1.0, 1.1, 2.0, 3.0 があれば ok です。
(1.0 もいらないかも。)
use std::fmt; #[derive(Debug, Clone, PartialEq, Eq)] enum HttpVersion { Http10, Http11, Http20, Http30, } impl HttpVersion { fn from_str(s: &str) -> Option<Self> { // 大文字/小文字を考慮しない。(小文字に統一) match s.to_lowercase().as_str() { "http/1.0" => Some(HttpVersion::Http10), "http/1.1" => Some(HttpVersion::Http11), "http/2.0" => Some(HttpVersion::Http20), "http/3.0" => Some(HttpVersion::Http30), _ => None, } } } impl From<&str> for HttpVersion { fn from(s: &str) -> Self { HttpVersion::from_str(s).unwrap_or(HttpVersion::Http10) } } // 文字列で取得できるように、Displayを実装しておきましょう impl fmt::Display for HttpVersion { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", match self { Self::Http10 => "HTTP/1.0", Self::Http11 => "HTTP/1.1", Self::Http20 => "HTTP/2.0", Self::Http30 => "HTTP/3.0", }) } } fn main() { // 検証してみよう assert_eq!(HttpVersion::from("Http/1.0").to_string(), "HTTP/1.0".to_string()); assert_eq!(HttpVersion::from("http/1.1"), HttpVersion::Http11); assert_eq!(HttpVersion::from("HTTP/2.0"), HttpVersion::Http20); assert_eq!(HttpVersion::from("HTTP/3.0"), HttpVersion::Http30); assert_eq!(HttpVersion::from(""), HttpVersion::Http10); println!("all success! 成功!"); }
...つかバージョンは変更対応しんどいだけやし文字列でええやろと思った。
ちなみにこの記事は実況記事です。 この先コメントなどによってはコード計画が変わる可能性があります。
header
一番しんどいところです。 特に使う部分(Content-Type や Accept、Host など)は別の関数から、簡易的にアクセスできるようにしていいと思います。 KeyValue 方式なので、それに従い HashMap を活用しましょう。 とりあえず 1 行をパースして hashmap に追加するところまで作ってみよう。
ちなみに、header と body の間には 1 行の空白行があります。 これは上手く使えそうですね! 私は上手く使えてるかわからんけど。
fn line_parse_http_header(s: &str) -> Option<(&str, &str)> { // 最初の:を探す let i = s.find(':')?; Some((&s[0..i], &s[i+1..].trim())) // :でk/vを切り分けて終わり } fn main() { assert_eq!( line_parse_http_header("Content-Type: text/plain"), Some(("Content-Type", "text/plain"))); assert_eq!( line_parse_http_header("Content-Type:"), Some(("Content-Type", ""))); assert_eq!( line_parse_http_header("Content-Type: Content-Type: text/plain"), Some(("Content-Type", "Content-Type: text/plain"))); assert_eq!( line_parse_http_header("Content-Type: "), Some(("Content-Type", ""))); assert_eq!( line_parse_http_header(" "), None); assert_eq!( line_parse_http_header("<html><head><title>hello</title></head><body></body></html>"), None); assert_eq!( line_parse_http_header("<html><head><title>:</title></head><body></body></html>"), Some(("<html><head><title>", "</title></head><body></body></html>"))); println!("all success! 成功!"); println!(""); println!("補足"); println!("最後のコードではHtmlがそのままHeaderとしてパースされている"); println!("残念ながら、この実装でも、そのデータが完璧にHeaderである保証はできない。"); println!("しかし、正規的なHTTPパケットであればheadとbodyの間に1行の隙間がある。"); println!("これを使い、とりあえずhtmlコードがパースされる心配はないようにする"); }
当然ながら header は 1 行だけではないので、複数行に対応しましょう。
use std::collections::HashMap; fn line_parse_http_header(s: &str) -> Option<(&str, &str)> { // 最初の:を探す let i = s.find(':')?; Some((&s[0..i], &s[i+1..].trim())) // :でk/vを切り分けて終わり } fn main() { // 行ごとに処理するイテレーターを取得 let buf = "Content-Type: plain/html \r\nHost: localhost\r\n\r\n<!DOCTYPE html>\r\n"; let mut lines = buf.lines(); let mut data: HashMap<&str, &str> = HashMap::new(); loop { let line = lines.next().unwrap_or(""); match line_parse_http_header(line) { Some((k, v)) => { _ = data.insert(k, v); }, None => break, } } println!("{:?}", data); }
結合してみる
これだけでよし
use std::{collections::HashMap, fmt}; #[derive(Debug, Clone, PartialEq, Eq)] struct HttpPath<'a>(&'a str); impl<'a> HttpPath<'a> { // 許可された文字列のみで作る fn from_str(s: &'a str) -> Option<Self> { // 文字単位に分解します let mut c = s.chars(); // 先頭は/になると見込んで if c.next() != Some('/') { return None; } // findメソッドで許可されていない文字があるか検索しましょう // なかったら成功です。 if c.find(|c| { // a-zA-Z0-9/\-_以外を探す !(c.is_ascii_alphanumeric() || *c == '/' || *c == '-' || *c == '_') }) == None { Some(HttpPath(s)) } else { None } } } // Fromトレイトもつけて、文字列から簡単に変換できるようにしましょう impl<'a> From<&'a str> for HttpPath<'a> { fn from(s: &'a str) -> Self { HttpPath::from_str(s).unwrap_or(HttpPath("/")) // デフォルト値は / } } // 文字列で取得できるように、Displayを実装しておきましょう impl<'a> fmt::Display for HttpPath<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", self.0) } } #[derive(Debug, Clone, PartialEq, Eq)] enum HttpMethod { Get, Post, Put, Delete, } impl HttpMethod { fn from_str(s: &str) -> Option<Self> { // 大文字/小文字を考慮しない。(小文字に統一) match s.to_lowercase().as_str() { "get" => Some(HttpMethod::Get), "post" => Some(HttpMethod::Post), "put" => Some(HttpMethod::Put), "delete" => Some(HttpMethod::Delete), _ => None, } } } impl From<&str> for HttpMethod { fn from(s: &str) -> Self { HttpMethod::from_str(s).unwrap_or(HttpMethod::Get) } } // 文字列で取得できるように、Displayを実装しておきましょう impl fmt::Display for HttpMethod { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", match self { Self::Get => "GET", Self::Post => "POST", Self::Put => "PUT", Self::Delete => "DELETE", }) } } #[derive(Debug, Clone, PartialEq, Eq)] enum HttpVersion { Http10, Http11, Http20, Http30, } impl HttpVersion { fn from_str(s: &str) -> Option<Self> { // 大文字/小文字を考慮しない。(小文字に統一) match s.to_lowercase().as_str() { "http/1.0" => Some(HttpVersion::Http10), "http/1.1" => Some(HttpVersion::Http11), "http/2.0" => Some(HttpVersion::Http20), "http/3.0" => Some(HttpVersion::Http30), _ => None, } } } impl From<&str> for HttpVersion { fn from(s: &str) -> Self { HttpVersion::from_str(s).unwrap_or(HttpVersion::Http10) } } // 文字列で取得できるように、Displayを実装しておきましょう impl fmt::Display for HttpVersion { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", match self { Self::Http10 => "HTTP/1.0", Self::Http11 => "HTTP/1.1", Self::Http20 => "HTTP/2.0", Self::Http30 => "HTTP/3.0", }) } } fn line_parse_http_header(s: &str) -> Option<(&str, &str)> { // 最初の:を探す let i = s.find(':')?; Some((&s[0..i], &s[i+1..].trim())) // :でk/vを切り分けて終わり } #[derive(Debug, Clone, PartialEq, Eq)] struct HttpRequest<'a> { method: HttpMethod, path: HttpPath<'a>, version: HttpVersion, header: HashMap<&'a str, &'a str>, body: String, } impl<'a> HttpRequest<'a> { fn from_str(s: &'a str) -> Option<Self> { // 行取得で行う let mut lines = s.lines(); // 1行目を取得する let mut parts = { let line = lines.next().unwrap_or(""); line.split_whitespace() // スペース単位で分割させる }; let method = HttpMethod::from(parts.next().unwrap_or("")); let path = HttpPath::from(parts.next().unwrap_or("")); let version = HttpVersion::from(parts.next().unwrap_or("")); // 余分にあったら無効とする if parts.next().is_some() { return None; } // 2行目(以降)を処理する let mut header: HashMap<&str, &str> = HashMap::new(); loop { let line = lines.next().unwrap_or(""); match line_parse_http_header(line) { Some((k, v)) => { _ = header.insert(k, v); }, None => break, } } // headerの処理をする let body = lines.collect::<String>(); Some (HttpRequest{ method, path, version, header, body }) } } // 文字列で取得できるように、Displayを実装しておきましょう impl<'a> fmt::Display for HttpRequest<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{} {} {}\r\n", self.method, self.path, self.version)?; for (k, v) in &self.header { write!(f, "{}: {}\r\n", k, v)?; } write!(f, "\r\n{}", self.body) } } #[derive(Debug, Clone, PartialEq, Eq)] struct HttpResponse<'a> { version: HttpVersion, status: (u32, &'a str), // レスポンスは番号とメッセージで返す header: HashMap<&'a str, &'a str>, body: String, } // 文字列で取得できるように、Displayを実装しておきましょう impl<'a> fmt::Display for HttpResponse<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{} {} {}\r\n", self.version, self.status.0, self.status.1)?; for (k, v) in &self.header { write!(f, "{}: {}\r\n", k, v)?; } write!(f, "\r\n{}", self.body) } } fn main() { let packet = "GET / HTTP/1.1\r\nHost: localhost\r\nAccept: */*\r\n\r\n"; let request = HttpRequest::from_str(&packet).unwrap(); println!("{}", request); }
HttpRequest と HttpResponse の構造体を定義、うち Request は文字列からの生成と出力に対応させた。
パースの知識 (★★★)
今回文字列のパースがメインだったため、パースの知識を書いておきます。
lines()と split()と chars() (★★☆)
文字列メソッドであるこれらの関数について、簡単にまとめておきましょう。
まず、いずれもこれらの関数はイテレーターを返します。 イテレーターは、オブジェクト指向で頻繁に出てくるデザインパターンの一つです。
内容は至ってシンプル。 Iterトレイトをつけてnext()メソッドを実装できれば OK です。
---
config:
class:
hideEmptyMembersBox: true
---
classDiagram
direction TB
class Iter {
next()
}
class ExampleClass {
Index
next()
}
<<Interface>> Iter
note for ExampleClass "試しに実装してみる構造体です"
ExampleClass ..|> Iter
struct ExampleClass { index: u64, max: u64, // 上限を決めておく } impl Iterator for ExampleClass { type Item = u64; // 76個ぐらいメソッドあるけど、これだけ実装しておけばOK! fn next(&mut self) -> Option<Self::Item> { let res = self.index; if res > self.max { return None; } self.index += 1; // 次のためにindexをずらしておく Some(res) } } fn main() { let ec = ExampleClass{index: 0, max: 10}; for i in ec { println!("{}", i); } }
この例は実質 Range を作ってます。
next()が実装できれば残りの 75 個ができると書いてありますが...
結局next()で解決するので実装は不要です。
(findは next を繰り返しながら条件一致を探す。 filterは next を繰り返しながら条件に一致するものだけを収集する。)
note
rust のイテレーターについては、死ぬほどお世話になってますこの記事がおすすめです。
Rust のイテレータの網羅的かつ大雑把な紹介
index か、文字か(★★★)
前の項目でイテレーターの紹介をし、さりげなくfind()というメソッドの紹介をしました。
改めて、find()は項目を探す関数なのですが... イテレーターと文字列(str, String)に、同名のメソッドが存在してる!!!
ややこしいですね。 しかも両方とも、しょっちゅう使います。
chars()にしてfind()にすることもあれば、文字列のままfind()で検索、文字の index を探すこともあります
let base = "hello";
let index = 3; // インデックス
let object = 'l'; // 文字ここで重要なのは、 index を得るか、文字の存在を得るか、 です
- index を得る(文字列の
find()を使う)
例えば:のような区切り文字を取得するときに使用できます。
:の前後で分割するという使い方できます。 戻り値は数値(Option<usize>)です! - 文字の存在を得る(イテレーターの
find()を使う)
例えば、許可文字以外の文字を検知し、弾くというときに使用できます。
戻り値は文字(Option<char>)です!
どちらの find も、基本的には左側から探します。 そして、 一番最初に見つけたものを返します。
tip
イテレーターの場合、rev()によって逆順(右側から)にすることも可、文字列の場合はrfindメソッドで対応可能
fn main() { { let base = "33-4"; let index = base.find('-').unwrap_or(0); assert_eq!((&base[0..index], &base[index+1..]),("33","4")); println!("33-4 を 33と4に分解できました"); } { let base = "33-4"; let res = base.chars().find(|c| c.is_ascii_control()).is_none(); assert!(res); println!("33-4 にascii制御文字はありません"); } }
note
ascii 制御文字: 改行文字(\n)とか、ターミナルでよく入力するであろう^c(Ctrl+c)こと
filter vs find (★★☆)
これは主にイテレーターで使うものです。 filter は許容文字以外を消すことができます。
しかし、許容文字以外を許可しない、バリデーションを行う用途には向いていないと日記さんは考えます。
というのも、送り主の許可なく解釈を変えるのはよくないからです。
よく、人とやりとりするとき、言葉の意味を都合よく解釈することがあるのですが、とてもよくありません。
検索して言葉の意味を調べることができますが、相手が意味を誤用していたり、方言的な意味で一般とは異なることもあります。
なので、わからない場合は素直に聞き返した方が楽ではあります。 (...まぁ、すぐに ggrks と言われるからできないんだけどさ)
ということで、相手の入力に誤りがある場合、素直にNoneなど、パースに失敗したことを伝えた方がいいのです。
ではフィルターをどこで使えばいいのでしょうか?
fn main() { let base = " helloworld"; // スペースを排除する let res = base.chars().filter(|c| !c.is_ascii_whitespace()).collect::<String>(); println!("{}", res); println!(""); println!("このように、バリデーションではなく、余分な部分を排除するなどの用途に向いてます!"); }
tip
先頭と最後のスペースを排除するなら文字列のメソッドtrim()がおすすめです。 trim_start() と trim_end() もあります!
まとめと次回 (☆☆☆)
今回は文字列の処理を行いました。
次回は、これらを使ってシングルスレッドサーバーを作ってみようと思います。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
作ったコードを置いてます
githubにて作ってきたコードをまとめたものを置いてます。
よかったら参考に...できるかな
HTTP であそぼう part2
前回記事を作り込みすぎて後悔しました。 今回からフットワーク軽めで書きたいと思います。
本日の 1 曲 🎶
同位体 5 人の合唱曲。 かっこよすぎる。
★ について (★★★)
★ はこの記事の中でとりあえず読んで欲しいところに 3、自分用のメモレベルで 1 をつけてます。
なので、★1 の内容が理解できなくても問題ないです! 書いてるやつが悪い。
一方 ★3 は頑張って書きましたので読んで欲しいな〜
本題 (★★☆)
前回、HTTP の構文解析(パース)を行いました。
これを使えば、受信したデータを HTTP をオブジェクトに直すことができ、データにアクセスが可能です。
とりあえず、これを使って通信を実現してみましょう。
擬似通信オブジェクトを作ってみる (★★☆)
擬似通信オブジェクト、つまり通信はしないが通信してるように見せかけるオブジェクトです。
具体的には Read トレイトと Write トレイトを実装したオブジェクトです。
主な用途は記事やテスト用です。
use std::{
collections::VecDeque,
io::{Read, Result, Write},
net::{SocketAddr, ToSocketAddrs},
thread,
};
#[derive(Debug, Clone, PartialEq, Eq)]
pub struct TcpListener {
addr: SocketAddr,
requests: VecDeque<&'static [u8]>,
}
impl TcpListener {
pub fn bind<A>(addr: A) -> Result<TcpListener>
where
A: ToSocketAddrs,
{
let addr = addr.to_socket_addrs()?.next().ok_or(std::io::Error::new(
std::io::ErrorKind::InvalidInput,
"No address found",
))?;
Ok(TcpListener {
addr,
requests: VecDeque::new(),
})
}
pub fn local_addr(&self) -> Result<SocketAddr> {
Ok(self.addr)
}
pub fn add_request(&mut self, request: &'static [u8]) {
self.requests.push_back(request);
}
pub fn accept(&mut self) -> Result<(TcpStream, SocketAddr)> {
loop {
if let Some(request) = self.requests.pop_front() {
let stream = TcpStream {
read_data: request,
write_data: Vec::new(),
is_flushed: false,
};
return Ok((stream, self.addr));
}
thread::sleep(std::time::Duration::from_millis(100));
}
}
}
#[derive(Debug, Clone, PartialEq, Eq)]
pub struct TcpStream<'a> {
read_data: &'a [u8],
write_data: Vec<u8>,
is_flushed: bool,
}
impl TcpStream<'_> {
pub fn new() -> TcpStream<'static> {
TcpStream {
read_data: &[],
write_data: Vec::new(),
is_flushed: false,
}
}
pub fn get_write_data(&self) -> Option<&[u8]> {
if self.is_flushed {
Some(&self.write_data)
} else {
None
}
}
}
impl Read for TcpStream<'_> {
fn read(&mut self, buf: &mut [u8]) -> Result<usize> {
let bytes = self.read_data;
let len = bytes.len().min(buf.len());
buf[..len].copy_from_slice(&bytes[..len]);
Ok(len)
}
}
impl Write for TcpStream<'_> {
fn write(&mut self, buf: &[u8]) -> Result<usize> {
if self.is_flushed {
return Err(std::io::Error::new(
std::io::ErrorKind::WriteZero,
"Stream is flushed, cannot write",
));
}
self.write_data.extend_from_slice(buf);
Ok(buf.len())
}
fn flush(&mut self) -> Result<()> {
println!("Flushing data: {:?}", self.write_data);
Ok(())
}
}長大なコードですが、その大半はAI 補完trait を実装すれば終わります。
内容の説明は至ってシンプルで、標準モジュールに存在するTcpLisnerとTcpStreamを最低限レベルで模しただけです。
そのため、accept()メソッドで通信を受信、read()やwrite()がそのまま使えます。
accept()で受信するデータを、キュー方式に対応した Vec VecDeque に格納しており、格納手段を提供するために add_request() メソッドを追加しております。
これは実際のTcpLisnerとは異なるメソッドです。
accept()は、現実の動作を模すために、キューからデータが消えてもデータを待ち続けます。
キューにデータが存在しない状態でaccept()を実行すると、永遠に待つことになりますので注意。
テスト用にget_write_data()メソッドを提供してます。 これはflush()後でないとNoneを返します!
実際に使ってみる
あまりにも内容が薄かったので、流石に善処することとします。 (この記事は一回更新しました。) 実際に動かすとこんな感じです。
(request を来るとき cl -> sv)
// listenerを開く
let mut listener = TcpListener::bind("127.0.0.1:80").unwrap();
let data = b"GET / HTTP/1.1\r\nhost: localhost\r\naccept: */*\r\n\r\n";
listener.add_request(data);
// (本来はループ分) 通信がきたらstreamが出てくる。
let (mut stream, _) = listener.accept().unwrap();
// データを受け取ってみる
let mut buf = [0u8;1024];
let size = stream.read(&mut buf).unwrap();
let buf = &buf[0..size];
println!("{}", String::from_utf8_lossy(&buf));
// assert_eqで確かめる
assert_eq!(buf, data);(response 送るとき sv -> cl)
// listenerを開く
let mut listener = TcpListener::bind("127.0.0.1:80").unwrap();
listener.add_request("\r\n".as_bytes());
// (本来はループ分) 通信がきたらstreamが出てくる。
let (mut stream, _) = listener.accept().unwrap();
// データを送ってみる
let data = "HTTP/1.1 200 Ok\r\nContent-Type: text/plain\r\n\r\nhello!\r\n";
_ = stream.write(data.as_bytes());
_ = stream.flush(); // 忘れずに!
assert_eq!(stream.get_write_data().unwrap(), data.as_bytes());実際に動作するコード
use std::{ collections::VecDeque, io::{Read, Result, Write}, net::{SocketAddr, ToSocketAddrs}, thread, }; #[derive(Debug, Clone, PartialEq, Eq)] pub struct TcpListener { addr: SocketAddr, requests: VecDeque<&'static [u8]>, } impl TcpListener { pub fn bind<A>(addr: A) -> Result<TcpListener> where A: ToSocketAddrs, { let addr = addr.to_socket_addrs()?.next().ok_or(std::io::Error::new( std::io::ErrorKind::InvalidInput, "No address found", ))?; Ok(TcpListener { addr, requests: VecDeque::new(), }) } pub fn local_addr(&self) -> Result<SocketAddr> { Ok(self.addr) } pub fn add_request(&mut self, request: &'static [u8]) { self.requests.push_back(request); } pub fn accept(&mut self) -> Result<(TcpStream, SocketAddr)> { loop { if let Some(request) = self.requests.pop_front() { let stream = TcpStream { read_data: request, write_data: Vec::new(), is_flushed: false, }; return Ok((stream, self.addr)); } thread::sleep(std::time::Duration::from_millis(100)); } } } #[derive(Debug, Clone, PartialEq, Eq)] pub struct TcpStream<'a> { read_data: &'a [u8], write_data: Vec<u8>, is_flushed: bool, } impl TcpStream<'_> { pub fn new() -> TcpStream<'static> { TcpStream { read_data: &[], write_data: Vec::new(), is_flushed: false, } } pub fn get_write_data(&self) -> Option<&[u8]> { if self.is_flushed { Some(&self.write_data) } else { None } } } impl Read for TcpStream<'_> { fn read(&mut self, buf: &mut [u8]) -> Result<usize> { let bytes = self.read_data; let len = bytes.len().min(buf.len()); buf[..len].copy_from_slice(&bytes[..len]); Ok(len) } } impl Write for TcpStream<'_> { fn write(&mut self, buf: &[u8]) -> Result<usize> { if self.is_flushed { return Err(std::io::Error::new( std::io::ErrorKind::WriteZero, "Stream is flushed, cannot write", )); } self.write_data.extend_from_slice(buf); Ok(buf.len()) } fn flush(&mut self) -> Result<()> { println!("Flushing data: {:?}", self.write_data); Ok(()) } } fn main() { // 送るとき { // listenerを開く let mut listener = TcpListener::bind("127.0.0.1:80").unwrap(); let data = b"GET / HTTP/1.1\r\nhost: localhost\r\naccept: */*\r\n\r\n"; listener.add_request(data); // (本来はループ分) 通信がきたらstreamが出てくる。 let (mut stream, _) = listener.accept().unwrap(); // データを受け取ってみる let mut buf = [0u8;1024]; let size = stream.read(&mut buf).unwrap(); let buf = &buf[0..size]; println!("{}", String::from_utf8_lossy(&buf)); // assert_eqで確かめる assert_eq!(buf, data); } { // listenerを開く let mut listener = TcpListener::bind("127.0.0.1:80").unwrap(); listener.add_request("\r\n".as_bytes()); // (本来はループ分) 通信がきたらstreamが出てくる。 let (mut stream, _) = listener.accept().unwrap(); // データを送ってみる let data = "HTTP/1.1 200 Ok\r\nContent-Type: text/plain\r\n\r\nhello!\r\n"; _ = stream.write(data.as_bytes()); _ = stream.flush(); // 忘れずに! assert_eq!(stream.get_write_data().unwrap(), data.as_bytes()); } }
buf の取り扱いについて
少し前に buf の取り扱いで注意するべき内容を載せた記事を書きましたが、おさらい。
- スタック上におくの
- 0 埋めしておく
#![allow(unused)] fn main() { let buf = [0u8; 10]; }
その記事はこちら
なお、この擬似 buffer を使っても当然、その問題は起きるので注意です!
// (本来はループ分) 通信がきたらstreamが出てくる。
let (mut stream, _) = listener.accept().unwrap();
// データを受け取ってみる
let mut buf = Vec::new(); // 動作しない!
let size = stream.read(&mut buf).unwrap();
let buf = &buf[0..size];
println!("{}", String::from_utf8_lossy(&buf));tip
上の「実際に動作するコード」は編集できるので、
試してみてください!
まとめ
擬似的に再現可能な TCPListener と TCPSocket を作った。 テストなどで応用が効きそうだ。
最近可不ェインが不足していることがわかった。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
作ったコードを置いてます
githubにて作ってきたコードをまとめたものを置いてます。
よかったら参考に...できるかな
HTTP であそぼう part3
お世話になってます。 日記は書いてないけど日記と申します。 毎日投稿すれば実質日記ですよね? (極力)毎日投稿するために内容は薄めです。
本日の 1 曲 🎶
恒例のやつです。
紡乃世さんはやっぱ明るい方が好き。 ヤンデレ動画も好きやけども...
★ について (★★★)
★ はこの記事の中でとりあえず読んで欲しいところに 3、自分用のメモレベルで 1 をつけてます。
なので、★1 の内容が理解できなくても問題ないです! 書いてるやつが悪い。
一方 ★3 は頑張って書きましたので読んで欲しいな〜
本題 (★★☆)
前回作った擬似 TCP 関数により、こういうサイトや、PlayGround、test コードで手にとる様な感覚で通信を取り扱える様になりました。 今回は、1,2 でやったことを一旦混ぜてみて、どういったことができるのかを再確認します。
ファイルの整理 (★☆☆)
>tree src
src
├── http_util
│ ├── method.rs
│ ├── mod.rs
│ ├── path.rs
│ ├── request.rs
│ ├── utils.rs
│ └── version.rs
├── lib.rs
└── vnet -> ../../2/code/src/vnet
~~response は少し待って欲しい。~~一応やりました。
とりあえず 40 分くらいかけてファイルを整理してみました。 40 分か。
というのも、テストも大量に増やしてみたからです。ドキュメント書こうとすると 2 時間ぐらい取られそうですね。
自分か感じる以上にものを書くのは時間がかかるということです。まぁ手書きよりかはましですが...
実際の HTTP リクエストをみてみる (★★★)
主に mac 版 safari と curl コマンドのリクエストを書きました。
note
curl のリクエスト文
GET / HTTP/1.1
Host: localhost
User-Agent: curl/8.7.1
Accept: */*
note
safari のリクエスト文
GET / HTTP/1.1
Host: localhost
Sec-Fetch-Dest: document
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Safari/605.1.15
Upgrade-Insecure-Requests: 1
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Accept-Language: ja
Priority: u=0, i
Accept-Encoding: gzip, deflate
Connection: keep-alive
safari のリクエスト分は、ヘッダーが長いですね。
使ってるのは M4 mac なのですが、Intel Mac となっているのが興味深いですね。 KHTML は KDE プロジェクトのやつですね。
また、firefox 開発元の Mozilla/5.0 というの興味深いです。 User-Agent は何でアクセスしているかではなく、なんのフレームワークに対応しているか書かれていると感じますね。
Accept-Language: ja によって表示言語が送信されます。 しかし、実際にはそれだけでなく、IP アドレスや、位置情報など、さまざまな手段で言語を確定させます。
Accept-Encoding: gzip, deflate はファイル圧縮技術ですね。 送受信するファイルのサイズを小さくできるので、通信費圧縮に貢献しそうです。
tip
まだ HTTP の頃、ziproxy と呼ばれる proxy ソフトが存在した。 これは通信費圧縮のために、中間サーバーでパケットを圧縮するものです。
Connection: keep-alive はHTTPの keepAlive 設定です。 TCP の KeepALive ではありません。 TCP の KeepALive ではないというのは重要な問題を含んでいます。
KeepALive を実装しないといけない
...そのうちやりますね。
問題が生じた (★☆☆)
ファイルを分けるとこのページで実行するファイルを作るのが大変!!! ってことです。
実行時はrust の playgroundを使うのですが、まぁ大変になります。
これを回避する方法は見つけられませんでした。 諦めて、全結合したコードを使います。 通信費かかると思うけど許して...
Minify Rust Code – Rust Minifier でコード圧縮するから!!
通信を再現してみる(★★☆)
本題です。 実はこれを書くのに 2 日ぐらいかけました。
とりあえず、せっかくファイルを整理しましたが、無理やり抽出してここで実行できるようにしてみましたので試してみてね。
mod http_util { mod path { use std::fmt::{self, Debug}; pub struct HttpPath<'a>(&'a str); impl<'a> Debug for HttpPath<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "HttpPath({})", self.0) } } impl<'a> PartialEq for HttpPath<'a> { fn eq(&self, other: &Self) -> bool { self.0 == other.0 } } impl<'a> Clone for HttpPath<'a> { fn clone(&self) -> Self { HttpPath(self.0) } } impl<'a> HttpPath<'a> { pub fn from_str(s: &'a str) -> Option<Self> { let mut c = s.chars(); if c.next() != Some('/') { return None; } if c.find(|c| { !(c.is_ascii_alphanumeric() || *c == '/' || *c == '-' || *c == '_' || *c == '.' || *c == '=' || *c == '?' || *c == '&' || *c == '%' || *c == '#') }) == None { Some(HttpPath(s)) } else { None } } } impl<'a> From<&'a str> for HttpPath<'a> { fn from(s: &'a str) -> Self { HttpPath::from_str(s).unwrap_or(HttpPath("/")) } } impl<'a> fmt::Display for HttpPath<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", self.0) } } } mod method { use std::fmt; pub enum HttpMethod { Get, Post, Put, Delete, } impl fmt::Debug for HttpMethod { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "HttpMethod({})", self) } } impl PartialEq for HttpMethod { fn eq(&self, other: &Self) -> bool { core::mem::discriminant(self) == core::mem::discriminant(other) } } impl Clone for HttpMethod { fn clone(&self) -> Self { match self { Self::Get => Self::Get, Self::Post => Self::Post, Self::Put => Self::Put, Self::Delete => Self::Delete, } } } impl HttpMethod { pub fn from_str(s: &str) -> Option<Self> { match s.to_lowercase().as_str() { "get" => Some(HttpMethod::Get), "post" => Some(HttpMethod::Post), "put" => Some(HttpMethod::Put), "delete" => Some(HttpMethod::Delete), _ => None, } } } impl From<&str> for HttpMethod { fn from(s: &str) -> Self { HttpMethod::from_str(s).unwrap_or(HttpMethod::Get) } } impl fmt::Display for HttpMethod { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!( f, "{}", match self { Self::Get => "GET", Self::Post => "POST", Self::Put => "PUT", Self::Delete => "DELETE", } ) } } } pub mod version { use std::fmt; pub enum HttpVersion { Http10, Http11, Http20, Http30, } impl fmt::Debug for HttpVersion { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "HttpVersion({})", self) } } impl Clone for HttpVersion { fn clone(&self) -> Self { match self { Self::Http10 => Self::Http10, Self::Http11 => Self::Http11, Self::Http20 => Self::Http20, Self::Http30 => Self::Http30, } } } impl PartialEq for HttpVersion { fn eq(&self, other: &Self) -> bool { core::mem::discriminant(self) == core::mem::discriminant(other) } } impl HttpVersion { pub fn from_str(s: &str) -> Option<Self> { match s.to_lowercase().as_str() { "http/1.0" => Some(HttpVersion::Http10), "http/1.1" => Some(HttpVersion::Http11), "http/2.0" => Some(HttpVersion::Http20), "http/3.0" => Some(HttpVersion::Http30), _ => None, } } } impl From<&str> for HttpVersion { fn from(s: &str) -> Self { HttpVersion::from_str(s).unwrap_or(HttpVersion::Http10) } } impl fmt::Display for HttpVersion { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!( f, "{}", match self { Self::Http10 => "HTTP/1.0", Self::Http11 => "HTTP/1.1", Self::Http20 => "HTTP/2.0", Self::Http30 => "HTTP/3.0", } ) } } } pub mod request { use super::{utils::*, *}; use std::{collections::HashMap, fmt}; pub struct HttpRequest<'a> { pub m: HttpMethod, pub p: HttpPath<'a>, pub v: HttpVersion, pub h: HashMap<&'a str, &'a str>, pub b: String, } impl PartialEq for HttpRequest<'_> { fn eq(&self, other: &Self) -> bool { self.m == other.m && self.p == other.p && self.v == other.v && self.h == other.h && self.b == other.b } } impl Clone for HttpRequest<'_> { fn clone(&self) -> Self { Self { m: self.m.clone(), p: self.p.clone(), v: self.v.clone(), h: self.h.clone(), b: self.b.clone(), } } } impl fmt::Debug for HttpRequest<'_> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { f.debug_struct("HttpRequest") .field("method", &self.m) .field("path", &self.p) .field("version", &self.v) .field("header", &self.h) .field("body", &self.b) .finish() } } impl<'a> HttpRequest<'a> { pub fn from_str(s: &'a str) -> Option<Self> { let mut ls = s.lines(); let mut ps = { let l = ls.next().unwrap_or(""); l.split_whitespace() }; let m = HttpMethod::from_str(ps.next().unwrap_or(""))?; let p = HttpPath::from_str(ps.next().unwrap_or(""))?; let v = HttpVersion::from_str(ps.next().unwrap_or(""))?; if ps.next().is_some() { return None; } let mut h: HashMap<&str, &str> = HashMap::new(); loop { let ls = ls.next().unwrap_or(""); match line_parse_http_header(ls) { Some((k, v)) => { _ = h.insert(k, v); } None => break, } } let b = ls.collect::<String>(); Some(Self { m, p, v, h, b }) } } impl<'a> fmt::Display for HttpRequest<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{} {} {}\r\n", self.m, self.p, self.v)?; for (k, v) in &self.h { write!(f, "{}: {}\r\n", k, v)?; } write!(f, "\r\n{}", self.b) } } } pub mod response { use super::{utils::*, *}; use std::{collections::HashMap, fmt}; pub struct HttpResponse<'a> { pub v: HttpVersion, pub s: (u16, &'a str), pub h: HashMap<&'a str, &'a str>, pub b: String, } impl PartialEq for HttpResponse<'_> { fn eq(&self, other: &Self) -> bool { self.v == other.v && self.s == other.s && self.h == other.h && self.b == other.b } } impl Clone for HttpResponse<'_> { fn clone(&self) -> Self { Self { v: self.v.clone(), s: self.s.clone(), h: self.h.clone(), b: self.b.clone(), } } } impl fmt::Debug for HttpResponse<'_> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { f.debug_struct("HttpResponse") .field("version", &self.v) .field("status", &self.s) .field("header", &self.h) .field("body", &self.b) .finish() } } impl<'a> HttpResponse<'a> { pub fn from_str(s: &'a str) -> Option<Self> { let mut ls = s.lines(); let mut ps = { let l = ls.next().unwrap_or(""); l.split_whitespace() }; let v = HttpVersion::from_str(ps.next().unwrap_or(""))?; let sc = ps.next().and_then(|s| s.parse::<u16>().ok())?; let sm = ps.next().unwrap_or(""); if ps.next().is_some() { return None; } let mut h: HashMap<&str, &str> = HashMap::new(); loop { let l = ls.next().unwrap_or(""); match line_parse_http_header(l) { Some((k, v)) => { _ = h.insert(k, v); } None => break, } } let body = ls.collect::<String>(); Some(Self { v, s: (sc, sm), h, b: body, }) } } impl<'a> fmt::Display for HttpResponse<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{} {} {}\r\n", self.v, self.s.0, self.s.1)?; for (k, v) in &self.h { write!(f, "{}: {}\r\n", k, v)?; } write!(f, "\r\n{}", self.b) } } } pub mod utils { pub fn line_parse_http_header(s: &str) -> Option<(&str, &str)> { let i = s.find(':')?; Some((&s[0..i], &s[i + 1..].trim())) } } pub use self::{ method::HttpMethod, path::HttpPath, request::HttpRequest, response::HttpResponse, version::HttpVersion, };}mod vnet { use std::{ collections::VecDeque, io::{Read, Result, Write}, net::{SocketAddr, ToSocketAddrs}, thread, }; pub struct TcpListener { a: SocketAddr, r: VecDeque<&'static [u8]>, } impl PartialEq for TcpListener { fn eq(&self, other: &Self) -> bool { self.a == other.a && self.r == other.r } } impl Clone for TcpListener { fn clone(&self) -> Self { Self { a: self.a.clone(), r: self.r.clone(), } } } impl std::fmt::Debug for TcpListener { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { f.debug_struct("TcpListener") .field("addr", &self.a) .field("requests", &self.r) .finish() } } impl TcpListener { pub fn bind<A>(addr: A) -> Result<TcpListener> where A: ToSocketAddrs, { let a = addr.to_socket_addrs()?.next().ok_or(std::io::Error::new( std::io::ErrorKind::InvalidInput, "No address found", ))?; Ok(TcpListener { a, r: VecDeque::new(), }) } pub fn local_addr(&self) -> Result<SocketAddr> { Ok(self.a) } pub fn add_request(&mut self, request: &'static [u8]) { self.r.push_back(request); } pub fn accept(&mut self) -> Result<(TcpStream, SocketAddr)> { loop { if let Some(rd) = self.r.pop_front() { let s = TcpStream { rd, wd: Vec::new(), fd: false, }; return Ok((s, self.a)); } thread::sleep(std::time::Duration::from_millis(100)); } } } pub struct TcpStream<'a> { rd: &'a [u8], wd: Vec<u8>, fd: bool, } impl PartialEq for TcpStream<'_> { fn eq(&self, other: &Self) -> bool { self.rd == other.rd && self.wd == other.wd && self.fd == other.fd } } impl Clone for TcpStream<'_> { fn clone(&self) -> Self { Self { rd: self.rd, wd: self.wd.clone(), fd: self.fd.clone(), } } } impl std::fmt::Debug for TcpStream<'_> { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { f.debug_struct("TcpStream") .field("read_data", &self.rd) .field("write_data", &self.wd) .field("is_flushed", &self.fd) .finish() } } impl TcpStream<'_> { pub fn new() -> TcpStream<'static> { TcpStream { rd: &[], wd: Vec::new(), fd: false, } } pub fn get_write_data(&self) -> Option<&[u8]> { if self.fd { Some(&self.wd) } else { None } } } impl Read for TcpStream<'_> { fn read(&mut self, buf: &mut [u8]) -> Result<usize> { let b = self.rd; let l = b.len().min(buf.len()); buf[..l].copy_from_slice(&b[..l]); Ok(l) } } impl Write for TcpStream<'_> { fn write(&mut self, b: &[u8]) -> Result<usize> { if self.fd { return Err(std::io::Error::new( std::io::ErrorKind::WriteZero, "Stream is flushed, cannot write", )); } self.wd.extend_from_slice(b); Ok(b.len()) } fn flush(&mut self) -> Result<()> { println!("Flushing data: {:?}", self.wd); self.fd = true; Ok(()) } }} use std::io::{Read, Write}; fn main() { // setup let mut listener = vnet::TcpListener::bind("127.0.0.1:8080").unwrap(); listener.add_request("GET / HTTP/1.1\r\nHost: localhost\r\n\r\n".as_bytes()); let (mut stream, _) = listener.accept().unwrap(); // read let mut read_buf = [0u8; 512]; _ = stream.read(&mut read_buf).unwrap(); let binding = String::from_utf8_lossy(&read_buf); let request = http_util::HttpRequest::from_str(&binding).unwrap(); println!("{}", request); // write let response = http_util::HttpResponse::from_str( "HTTP/1.1 200 Ok\r\nContent-Type: text/plain\r\n\r\nhelloworld!\r\n", ) .unwrap(); _ = stream.write(response.to_string().as_bytes()); _ = stream.flush(); println!( "{}", String::from_utf8_lossy(stream.get_write_data().unwrap()) ) }
簡易的な web サーバーを立ててみる(★★★)
やっと本題だよ。
先ほどの HTTP パケットを見ればわかるように、サーバーにはたくさんの情報が送られます。
サーバーは、送られた情報を元に**ユーザーが求めているのは何か?**というのを考え、答えなければなりません。
note
求めているものはページはもちろん、フォーマット(html なのか、json なのか)は?、言語は?、ブラウザの環境は? などなど
今回 3 つのページをやりとりします。
GET / HTTP/1.1の場合
このファイルを返します
GET /profile HTTP/1.1の場合
このファイルを返します
それ以外の場合
みんな大好きあれを返します
実際にコードにしてみる
mod http_util { mod path { use std::fmt::{self, Debug}; pub struct HttpPath<'a>(&'a str); impl<'a> Debug for HttpPath<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "HttpPath({})", self.0) } } impl<'a> PartialEq for HttpPath<'a> { fn eq(&self, other: &Self) -> bool { self.0 == other.0 } } impl<'a> Clone for HttpPath<'a> { fn clone(&self) -> Self { HttpPath(self.0) } } impl<'a> HttpPath<'a> { pub fn from_str(s: &'a str) -> Option<Self> { let mut c = s.chars(); if c.next() != Some('/') { return None; } if c.find(|c| { !(c.is_ascii_alphanumeric() || *c == '/' || *c == '-' || *c == '_' || *c == '.' || *c == '=' || *c == '?' || *c == '&' || *c == '%' || *c == '#') }) == None { Some(HttpPath(s)) } else { None } } } impl<'a> From<&'a str> for HttpPath<'a> { fn from(s: &'a str) -> Self { HttpPath::from_str(s).unwrap_or(HttpPath("/")) } } impl<'a> fmt::Display for HttpPath<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", self.0) } } } mod method { use std::fmt; pub enum HttpMethod { Get, Post, Put, Delete, } impl fmt::Debug for HttpMethod { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "HttpMethod({})", self) } } impl PartialEq for HttpMethod { fn eq(&self, other: &Self) -> bool { core::mem::discriminant(self) == core::mem::discriminant(other) } } impl Clone for HttpMethod { fn clone(&self) -> Self { match self { Self::Get => Self::Get, Self::Post => Self::Post, Self::Put => Self::Put, Self::Delete => Self::Delete, } } } impl HttpMethod { pub fn from_str(s: &str) -> Option<Self> { match s.to_lowercase().as_str() { "get" => Some(HttpMethod::Get), "post" => Some(HttpMethod::Post), "put" => Some(HttpMethod::Put), "delete" => Some(HttpMethod::Delete), _ => None, } } } impl From<&str> for HttpMethod { fn from(s: &str) -> Self { HttpMethod::from_str(s).unwrap_or(HttpMethod::Get) } } impl fmt::Display for HttpMethod { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!( f, "{}", match self { Self::Get => "GET", Self::Post => "POST", Self::Put => "PUT", Self::Delete => "DELETE", } ) } } } pub mod version { use std::fmt; pub enum HttpVersion { Http10, Http11, Http20, Http30, } impl fmt::Debug for HttpVersion { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "HttpVersion({})", self) } } impl Clone for HttpVersion { fn clone(&self) -> Self { match self { Self::Http10 => Self::Http10, Self::Http11 => Self::Http11, Self::Http20 => Self::Http20, Self::Http30 => Self::Http30, } } } impl PartialEq for HttpVersion { fn eq(&self, other: &Self) -> bool { core::mem::discriminant(self) == core::mem::discriminant(other) } } impl HttpVersion { pub fn from_str(s: &str) -> Option<Self> { match s.to_lowercase().as_str() { "http/1.0" => Some(HttpVersion::Http10), "http/1.1" => Some(HttpVersion::Http11), "http/2.0" => Some(HttpVersion::Http20), "http/3.0" => Some(HttpVersion::Http30), _ => None, } } } impl From<&str> for HttpVersion { fn from(s: &str) -> Self { HttpVersion::from_str(s).unwrap_or(HttpVersion::Http10) } } impl fmt::Display for HttpVersion { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!( f, "{}", match self { Self::Http10 => "HTTP/1.0", Self::Http11 => "HTTP/1.1", Self::Http20 => "HTTP/2.0", Self::Http30 => "HTTP/3.0", } ) } } } pub mod request { use super::{utils::*, *}; use std::{collections::HashMap, fmt}; pub struct HttpRequest<'a> { pub m: HttpMethod, pub p: HttpPath<'a>, pub v: HttpVersion, pub h: HashMap<&'a str, &'a str>, pub b: String, } impl PartialEq for HttpRequest<'_> { fn eq(&self, other: &Self) -> bool { self.m == other.m && self.p == other.p && self.v == other.v && self.h == other.h && self.b == other.b } } impl Clone for HttpRequest<'_> { fn clone(&self) -> Self { Self { m: self.m.clone(), p: self.p.clone(), v: self.v.clone(), h: self.h.clone(), b: self.b.clone(), } } } impl fmt::Debug for HttpRequest<'_> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { f.debug_struct("HttpRequest") .field("method", &self.m) .field("path", &self.p) .field("version", &self.v) .field("header", &self.h) .field("body", &self.b) .finish() } } impl<'a> HttpRequest<'a> { pub fn from_str(s: &'a str) -> Option<Self> { let mut ls = s.lines(); let mut ps = { let l = ls.next().unwrap_or(""); l.split_whitespace() }; let m = HttpMethod::from_str(ps.next().unwrap_or(""))?; let p = HttpPath::from_str(ps.next().unwrap_or(""))?; let v = HttpVersion::from_str(ps.next().unwrap_or(""))?; if ps.next().is_some() { return None; } let mut h: HashMap<&str, &str> = HashMap::new(); loop { let ls = ls.next().unwrap_or(""); match line_parse_http_header(ls) { Some((k, v)) => { _ = h.insert(k, v); } None => break, } } let b = ls.collect::<String>(); Some(Self { m, p, v, h, b }) } } impl<'a> fmt::Display for HttpRequest<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{} {} {}\r\n", self.m, self.p, self.v)?; for (k, v) in &self.h { write!(f, "{}: {}\r\n", k, v)?; } write!(f, "\r\n{}", self.b) } } } pub mod response { use super::{utils::*, *}; use std::{collections::HashMap, fmt}; pub struct HttpResponse<'a> { pub v: HttpVersion, pub s: (u16, &'a str), pub h: HashMap<&'a str, &'a str>, pub b: String, } impl PartialEq for HttpResponse<'_> { fn eq(&self, other: &Self) -> bool { self.v == other.v && self.s == other.s && self.h == other.h && self.b == other.b } } impl Clone for HttpResponse<'_> { fn clone(&self) -> Self { Self { v: self.v.clone(), s: self.s.clone(), h: self.h.clone(), b: self.b.clone(), } } } impl fmt::Debug for HttpResponse<'_> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { f.debug_struct("HttpResponse") .field("version", &self.v) .field("status", &self.s) .field("header", &self.h) .field("body", &self.b) .finish() } } impl<'a> HttpResponse<'a> { pub fn from_str(s: &'a str) -> Option<Self> { let mut ls = s.lines(); let mut ps = { let l = ls.next().unwrap_or(""); l.split_whitespace() }; let v = HttpVersion::from_str(ps.next().unwrap_or(""))?; let sc = ps.next().and_then(|s| s.parse::<u16>().ok())?; let sm = ps.next().unwrap_or(""); if ps.next().is_some() { return None; } let mut h: HashMap<&str, &str> = HashMap::new(); loop { let l = ls.next().unwrap_or(""); match line_parse_http_header(l) { Some((k, v)) => { _ = h.insert(k, v); } None => break, } } let body = ls.collect::<String>(); Some(Self { v, s: (sc, sm), h, b: body, }) } } impl<'a> fmt::Display for HttpResponse<'a> { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{} {} {}\r\n", self.v, self.s.0, self.s.1)?; for (k, v) in &self.h { write!(f, "{}: {}\r\n", k, v)?; } write!(f, "\r\n{}", self.b) } } } pub mod utils { pub fn line_parse_http_header(s: &str) -> Option<(&str, &str)> { let i = s.find(':')?; Some((&s[0..i], &s[i + 1..].trim())) } } pub use self::{ method::HttpMethod, path::HttpPath, request::HttpRequest, response::HttpResponse, version::HttpVersion, };}mod vnet { use std::{ collections::VecDeque, io::{Read, Result, Write}, net::{SocketAddr, ToSocketAddrs}, thread, }; pub struct TcpListener { a: SocketAddr, r: VecDeque<&'static [u8]>, } impl PartialEq for TcpListener { fn eq(&self, other: &Self) -> bool { self.a == other.a && self.r == other.r } } impl Clone for TcpListener { fn clone(&self) -> Self { Self { a: self.a.clone(), r: self.r.clone(), } } } impl std::fmt::Debug for TcpListener { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { f.debug_struct("TcpListener") .field("addr", &self.a) .field("requests", &self.r) .finish() } } impl TcpListener { pub fn bind<A>(addr: A) -> Result<TcpListener> where A: ToSocketAddrs, { let a = addr.to_socket_addrs()?.next().ok_or(std::io::Error::new( std::io::ErrorKind::InvalidInput, "No address found", ))?; Ok(TcpListener { a, r: VecDeque::new(), }) } pub fn local_addr(&self) -> Result<SocketAddr> { Ok(self.a) } pub fn add_request(&mut self, request: &'static [u8]) { self.r.push_back(request); } pub fn accept(&mut self) -> Result<(TcpStream, SocketAddr)> { loop { if let Some(rd) = self.r.pop_front() { let s = TcpStream { rd, wd: Vec::new(), fd: false, }; return Ok((s, self.a)); } thread::sleep(std::time::Duration::from_millis(100)); } } } pub struct TcpStream<'a> { rd: &'a [u8], wd: Vec<u8>, fd: bool, } impl PartialEq for TcpStream<'_> { fn eq(&self, other: &Self) -> bool { self.rd == other.rd && self.wd == other.wd && self.fd == other.fd } } impl Clone for TcpStream<'_> { fn clone(&self) -> Self { Self { rd: self.rd, wd: self.wd.clone(), fd: self.fd.clone(), } } } impl std::fmt::Debug for TcpStream<'_> { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { f.debug_struct("TcpStream") .field("read_data", &self.rd) .field("write_data", &self.wd) .field("is_flushed", &self.fd) .finish() } } impl TcpStream<'_> { pub fn new() -> TcpStream<'static> { TcpStream { rd: &[], wd: Vec::new(), fd: false, } } pub fn get_write_data(&self) -> Option<&[u8]> { if self.fd { Some(&self.wd) } else { None } } } impl Read for TcpStream<'_> { fn read(&mut self, buf: &mut [u8]) -> Result<usize> { let b = self.rd; let l = b.len().min(buf.len()); buf[..l].copy_from_slice(&b[..l]); Ok(l) } } impl Write for TcpStream<'_> { fn write(&mut self, b: &[u8]) -> Result<usize> { if self.fd { return Err(std::io::Error::new( std::io::ErrorKind::WriteZero, "Stream is flushed, cannot write", )); } self.wd.extend_from_slice(b); Ok(b.len()) } fn flush(&mut self) -> Result<()> { println!("Flushing data: {:?}", self.wd); self.fd = true; Ok(()) } }} use std::{io::{Read, Write}, collections::HashMap}; // 今回はページをあらかじめハードコードしておく const MAIN_PAGE: &str = "<h1>Hello world!</h1>"; const PROFILE_PAGE: &str = "<h1>profile</h1>"; const ERROR_PAGE: &str = "<h1>404 Not Found</h1>"; fn main() { // setup let mut listener = vnet::TcpListener::bind("127.0.0.1:8080").unwrap(); // この順番でリクエストを4回送る listener.add_request("GET / HTTP/1.1\r\n\r\n".as_bytes()); // ホームページ listener.add_request("GET /profile HTTP/1.1\r\n\r\n".as_bytes()); // profileページ listener.add_request("GET /error HTTP/1.1\r\n\r\n".as_bytes()); // エラーページ listener.add_request("GET /e233 HTTP/1.1\r\n\r\n".as_bytes()); // エラーページ // 4回分のパケットをリクエストを受け取る for _ in 0..4 { let (mut stream, _) = listener.accept().unwrap(); // リクエストを受け取る let mut read_buf = [0u8; 512]; _ = stream.read(&mut read_buf).unwrap(); let request = String::from_utf8_lossy(&read_buf); let request = http_util::HttpRequest::from_str(&request).unwrap(); // パスごとにページを切り替える let (page, status_code, status_msg) = match (request.m, request.p.to_string().as_str()) { (http_util::HttpMethod::Get, "/") => (MAIN_PAGE, 200, "Ok"), (http_util::HttpMethod::Get, "/profile") => (PROFILE_PAGE, 200, "Ok"), _ => (ERROR_PAGE, 404, "Not Found"), }; // レスポンスを作る let response = http_util::HttpResponse{ v: http_util::HttpVersion::Http11, s: (status_code, status_msg), h: HashMap::new(), b: page.to_string(), }; println!("{}", response); // bytesに直して送信する let response = response.to_string(); let response = response.as_bytes(); _ = stream.write(response); _ = stream.flush(); // 忘れずに println!(""); //出力整形用 } }
Flushing dataが実際に送信されたと仮定した表示となります。 実際にはブラウザに届き、表示処理がなされているはずです。
前回から少しコードが変更になってて、response と request の中身をいじれるようにしました。 というのも隠す必要がなかったからです。 プロパティ名が短縮されてるのはコード圧縮時にやりました。
note
...何も考えずにライフタイム注釈(<'a>)を使用しまくったのは失敗でした。
また、通信を再現する関数も、正直今回以外出てくる自信はありません。 本来は、スレッド別でシミュレーションできるようにしっかり作るべきでしたね...
なにより、コードブロックにコードを納めるのが大変。 次回はこれをわかりやすく表現する方法を考えないとな...
今回の項目は色々と失敗点が多く出てきました。 今後は徐々にこれを解決したいと思います。
まとめ
このページ書くだけで 2 日かけました。 長かった。
何より勢いでコードを書くのは失敗を伴いますね。 まぁ若干反省。
とはいえ、これを実際の TCP/IP に置き換えれば通信ができそうです。 それを次回確認しましょう。
ご意見募集中
当サイトのリポジトリにて、issue 募集中です!
- 投稿には github アカウントが必要です。
- テンプレート用意してます。 ぜひ活用してください。
作ったコードを置いてます
githubにて作ってきたコードをまとめたものを置いてます。
よかったら参考に...できるかな
HTTP であそぼう part3.5
いつまで経っても詳しいと言える自信はないです。どんな分野でも。
🎵 本日の一曲
かっこいい
存在する http ライブラリを実際に試してみる
今回は本題から外れ、実際に存在する rust 製 http ライブラリを試そうと思います。
私が発見したのでは
ところでcookbookはご存知で?
rust-cookbookは、料理レシピ本のように色々なプログラミング例がのってるサイトです。
rust-exampleとの違いは、example は基本的な構文の理解のためにあるのに対し、
cookbook は よく使うクレート(ライブラリ)の例を載せてあります。
httparse
http/1.x のリクエスト、レスポンスを解析するためのパーサーです。 SIMD と呼ばれる一回の計算で複数の式を実行できる的なやつに対応してる模様。
パース後は構造体で管理されるそうです。
一例
request のみ検証しました。
let buf = b"POST / HTTP/1.1\r\nHost: localhost\r\nSec-Fetch-Dest: document\r\nUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Safari/605.1.15\r\nUpgrade-Insecure-Requests: 1\r\nAccept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\nSec-Fetch-Site: none\r\nSec-Fetch-Mode: navigate\r\nAccept-Language: ja\r\nPriority: u=0, i\r\nAccept-Encoding: gzip, deflate\r\nConnection: keep-alive\r\nContent-Type: text/plain\r\n\r\nhello world";
let mut headers = [EMPTY_HEADER; 64];
let mut request = Request::new(&mut headers);
let head_size = request.parse(buf).unwrap().unwrap();
assert_eq!(request.method.unwrap(), "POST");
assert_eq!(request.path.unwrap(), "/");
// 1.0だと0, 1.1だと1
// 1.0, 1.1以外はnoneになる?
assert_eq!(request.version.unwrap(), 1);
assert_eq!(String::from_utf8_lossy(&buf[head_size..]), "hello world");シンプルです。 headers の中身を debug でのぞいてみると
[Header { name: "Host", value: "localhost" }, Header { name: "Sec-Fetch-Dest", value: "document" }, Header { name: "User-Agent", value: "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Safari/605.1.15" }, Header { name: "Upgrade-Insecure-Requests", value: "1" }, Header { name: "Accept", value: "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8" }, Header { name: "Sec-Fetch-Site", value: "none" }, Header { name: "Sec-Fetch-Mode", value: "navigate" }, Header { name: "Accept-Language", value: "ja" }, Header { name: "Priority", value: "u=0, i" }, Header { name: "Accept-Encoding", value: "gzip, deflate" }, Header { name: "Connection", value: "keep-alive" }, Header { name: "Content-Type", value: "text/plain" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }, Header { name: "", value: "" }]
となってます。 なお、私が探した限り、検索などの機能は備わってません。
改行コードが\r\nでないとパースされませんでしたが、おそらくプロトコルの仕様がそうなってるんだと思います、と思って調べてたら面白い記事を発見。
CRLF インジェクションとは? -CyberMatrix
おもろいというか、巧妙な手口だなと思いました。
この例で Cookie を扱ってますが、その辺は今後検証したいと思います。
(この記事書いてる目的は、http を理解するとともに cookie を理解したいから)
reqwest
reqwest は js でいう fetch のように、http クライアントとして通信するのに特化したクレートです。
use anyhow::Result; use std::io::Read; fn main() -> Result<()> { let mut res = reqwest::blocking::get("http://httpbin.org/get")?; let mut body = String::new(); res.read_to_string(&mut body)?; println!("Status: {}", res.status()); println!("Headers:\n{:#?}", res.headers()); println!("Body:\n{}", body); Ok(()) }
そのまま cookbook から持ってきました。
- anyhow
エラー処理を簡単にするクレート - httpbin.org
http 関係のテストができるサイト
http://httpbin.org/getでは、送った get リクエストのヘッダー情報や、url パラメータがそのまま返却される。
reqwest の feature で blocking が必要でした。
まとめ
外部のライブラリに触れると、思わぬ発見があってたのしい。
games
ゲーム記事でも書いてみようかなと
simulator
個人的にシミュレーターが一番得意
焼肉シミュレーターやってみた
猛烈に焼肉が食いたかったので

動作環境
macOS 遣いなワシ、windows のみの対応だったので、いつもどおり wine(Kegworks Winery)でやってます。
note
wine とは mac 民や linux 民といった特殊民族非 windows 民が、windows 向けのプログラムを実行させるためのプログラムです。
オンライン対戦などはシステム上、チートが疑われてしまうため、windows でプレイすることが推奨されてます。
チャレンジモードやってみた
メインメニュー一番上から攻めるのが王道だと思って。
 画像のような色に焼きあがれば高得点になる。
画像のような色に焼きあがれば高得点になる。
note
撮影当時で私の最高点数は 80 点だった
すぐ焦げる
 タイミングよく焼かないと、黒焦げになってしまう。
タイミングよく焼かないと、黒焦げになってしまう。
マイナス点になってしまうため、なんとしても阻止したい
まとめ
やきにくくいたい
bluearchive
ガチャの結果だけ書きます。
なぎちゃん強くしたら 400 位になったじゃんね ⭐︎
2025/08/06 更新
シーズン初めだから上位に行って当然なんだよなぁ...(困惑)
4.5 周年について
結局水着ナギサ諦めました orz
チャレンジミッション全クリを目指して
ブルアカのチャレンジミッションを全クリしたい。
warning
この記事は攻略を目的としておらず、ただのメモにすぎません。
もっといい方法があると思います。
やり方
神ゲー攻略の「【ブルアカ】任務攻略一覧と編成おすすめキャラ」をみてクリアする
攻略みるのは邪道だと言われるかもしれないけど、これ普通に辛い。
というのも、24 年の周年イベで追加された簡易攻略が使えない。
星 3 がむずいなら簡易攻略で代用可能
集中指揮、簡易攻略共に星は共通なので、簡易攻略で星3を目指し、集中指揮でチャレンジミッションはあり。
ただし時間は 1.5 倍、スタミナ 2 倍になるけど。
編成組むのがめんどくさい
エリアごとに使う編成が結構変わるので、プリセットを活用したい。
しかし、キャラ数少ないなら、プリセット自体に登録するキャラを減らすと楽に編成できる。
(特にスペシャルのキャラは枯渇しがちだから外して柔軟に組めるようにしてる)
チャレンジ、星 3 目指すぐらいなら...
まず normal の area25 を目指せ
理由: カフェランクを上げれるから
スタミナが多ければ、イベントの周回ができる。
ぶっちゃけイベント周回の報酬の方が嬉しい
これをやるタイミング
イベントがない時。 カフェランク max の時。
ガチャの石稼ぎするくらいなら、イベント進めた方が石が入ると思う。
チャレンジミッションおよび hard のプレボは暇な時に獲得しておくといいと思う。
カフェランクはあげるとレベルが上がりやすくなる
ぶっちゃけ簡易攻略ならレベル足りてなくても回せると思う。
2025/08/15
イベントもねぇ、なんもねぇ。
チャレンジミッション消化することとした。
1 時間でおおよそ 2 エリアぐらい攻略できる気がする。
ボス戦もオートで回るので、攻略通りにパズルクリアして、終わるだけなので、 動画みながらやってた。
まとめ
ミカセイを推せ(4.5 周年でなぎちゃん当たらなかった人)
4.5 周年
とりあえず石は 18000 ぐらいあった。
毎ログでもらえる石 1200 と、イベントでもらえる石 1200、あとチケット、フリーパス、
新人教師のやつも買えたので 360 円課金。
狙うは水着ミカ
前半戦
無料 10 連をセイアに賭けた。なんと 4 回目で出た。
後半戦
天井でミカ引きました。 悲しい。
なぎちゃん諦めました...
水着ミカで戦ってみた
個人的には結構癖つよだと思う。
ドヒナもそうなんだけど、手動で使うのを前提に組まないとあまり美味しくないのかなって。
mika say "mikasei"
みかせい
みかせいって何?
みかせいである
相性
-
通常ミカ/通常セイア 通常ミカのコストが高いから、普通にありな構成
-
通常ミカ/水着セイア バフかけるのに優秀だと思ってる。コスト問題は水着ホシノ(盾役)とか、正月フウカとか
-
水着ミカ/通常セイア 悪くはないと思う。 水着ミカの都合上、コストを事前に蓄えられないので、バッファーでコスト下げながら、ミカ連続入れて、その後セイアでコストってなる。 ただそれやるなら、ぶっちゃけた話正月フウカの方が使い勝手いい気はする。
-
水着ミカ/水着セイア 前述した、コスト下げるバッファーとして水着セイアを入れるのはありだと思う。コスト役は水着ホシノとか、正月フウカでいいと思うよ
ストーリーとして
日記さんアホだからもしかしたら解釈間違えてるかもしれない。
喧嘩するほど仲がいい、そんな感じだと思う。
何でナギチャンが居ないんですか
引いても出なかったから
subnautica やってみた
海ばかりの星に墜落してしまうゲームやりました。

難易度は割と低い
難易度はかなり低いほうだと感じます。
マイクラを除くこういったゲームあるあるで、飲料資源が少ないなんて問題もないし。
肉もそこらじゅうにあるので取り放題です。 調理も燃料いらずだし。
ストーリーが気になる
ストーリーの奥が深いと聞いたことがあります。 さらに進めたらまた感想も書こうかな。
シーモスよき
最初の画像に写ってる、ufo みたいなやつがシーモスです。 こいつはアプグレなしで海中 200m まで潜れます。
しばらくはこいつの世話になりそう
(2025/08/11 追記)プレイを終えて
改めて、難易度は低いと思う。 日記さんでもクリアできた。
(※日記さんはとんでもなくゲーム能力低いです。AI 使ってヒント得てたなんて口が裂けても言えない)
探索要素が多く、ストーリーからヒントを得ることも多かったです。
終始ぼっちだったのがつらかったです
(2025/08/11 追記)subnautica2 が出てくるらしい。
なんとマルチ対応らしい。 2026 年あたりに出るらしいので、覚えてたらやりたいよね。